
Search Results
I’ve been working at The University of Manchester for almost a decade and will be leaving at the end of this week! A huge part of my job was to support a major subset of Manchester’s site licensed application software portfolio so naturally I’ve made use of a lot of it over the years. As of February 20th, I will no longer be entitled to use any of it!
This article is the second in a series where I’ll look at some of the software that’s become important to me and what my options are on leaving Manchester. Here, I consider MATLAB – a technical computing environment that has come to dominate my career at Manchester. For the last 10 years, I’ve used MATLAB at least every week, if not most days.
I had a standalone license for MATLAB and several toolboxes – Simulink, Image Processing, Parallel Computing, Statistics and Optimization. Now, I’ve got nothing! Unfortunately for me, I’ve also got hundreds of scripts, mex files and a few Simulink models that I can no longer run! These are my options:
Go somewhere else that has a MATLAB site license
- I’ll soon be joining the University of Sheffield who have a MATLAB site license. A great option if you can do it.
Use something else
- Octave – Octave is a pretty good free and open source clone of MATLAB and quite a few of my programs would work without modification. Others would require some rewriting and, in some cases, that rewriting could be extensive! There is no Simulink support.
- Scilab – It’s free and it’s MATLAB-like-ish but I’d have to rewrite my code most of the time. I could also port some of my Simulink models to Scilab as was done in this link.
- Rewrite all my code to use something completely different. What I’d choose would depend on what I’m trying to achieve but options include Python, Julia and R among others.
Compile!
- If all I needed was the ability to run a few MATLAB applications I’d written, I could compile them using the MATLAB Compiler and keep the result. The whole point of the MATLAB Compiler is to distribute MATLAB applications to those who don’t have a MATLAB license. Of course once I’ve lost access to MATLAB itself, debugging and adding features will be um……tricky!
Get a hobbyist license for MATLAB
- MATLAB Home – This is the full version of MATLAB for hobbyists. Writing a non-profit blog such as WalkingRandomly counts as a suitable ‘hobby’ activity so I could buy this license. MATLAB itself for 85 pounds with most of the toolboxes coming in at an extra 25 pounds each. Not bad at all! The extra cost of the toolboxes would still lead me to obsess over how to do things without toolboxes but, to be honest, I think that’s an obsession I’d miss if it weren’t there! Buying all of the same toolboxes as I had before would end up costing me a total of £210+VAT.
- Find a MOOC that comes with free MATLAB – Mathworks make MATLAB available for free for students of some online courses such as the one linked to here. Bear in mind, however, that the license only lasts for the duration of the course.
Academic Use
If I were to stay in academia but go to an institution with no MATLAB license, I could buy myself an academic standalone license for MATLAB and the various toolboxes I’m interested in. The price lists are available at http://uk.mathworks.com/pricing-licensing/
For reference, current UK academic prices are
- MATLAB £375 + VAT
- Simulink £375 + VAT
- Standard Toolboxes (statistics, optimisation, image processing etc) £150 +VAT each
- Premium Toolboxes (MATLAB Compiler, MATLAB Coder etc) – Pricing currently not available
My personal mix of MATLAB, Simulink and 4 toolboxes would set me back £1350 + VAT.
Commercial Use
If I were to use MATLAB professionally and outside of academia, I’d need to get a commercial license. Prices are available from the link above which, at the time of writing, are
- MATLAB £1600 +VAT
- Simulink £2400 + VAT
- Standard Toolboxes £800 +VAT each
- Premium Toolboxes – Pricing currently not available
My personal mix of MATLAB, Simulink and 4 toolboxes would set me back £7200 + VAT.
Contact MathWorks
If anyone does find themselves in a situation where they have MATLAB code and no means to run it, then they can always try contacting MathWorks and ask for help in finding a solution.
Welcome to the rather delayed Carnival of Mathematics for July. This is the 113th edition of the mathematical blogging tradition that’s organised by Katie and company over at The Aperiodical.
Number Trivia and a challenge
Long held tradition dictates that I find something interesting about this month’s edition number – 113 – and I turn to Number Gossip for help. It comes up with 3 very nice little prime tidbits:
- 113 is the smallest three-digit permutable prime
- 113 is the smallest three-digit Unholey prime: such primes do not have holes in their digits
- 113 is the smallest three-digit prime whose product and sum of digits is prime
Walking Randomly Challenge: Prove the above using the programming language of your choice and post in the comments section. Here’s a demonstration of the first statement using Mathematica.
(*Returns true if num is a permutable prime*)
permutePrimeQ[num_] :=
AllTrue[PrimeQ[Map[FromDigits, Permutations[IntegerDigits[num]]]],
TrueQ]
(*prints all permutable primes from 1 to 1000*)
Do[
If[permutePrimeQ[x], Print[x]]
, {x, 1, 1000}
]
2
3
5
7
11
13
17
31
37
71
73
79
97
113
131
199
311
337
373
733
919
991
On with the show
Mathematical software blogs
A math carnival wouldn’t be a WalkingRandomly math carnival without some focus on mathematical software blogs. Loren of The Art of MATLAB brings us Analyzing Fitness Data from Wearable Devices in MATLAB which is a guest post by Toshi Takeuchi. The new computational programming language on the block is Julia and the Julia blog contains videos and code on mathematical Optimization in Julia. The Wolfram Blog has a video on how to Create Escher-Inspired art with Mathematica (Don’t forget that Mathematica can be had for free for the Raspberry Pi).
Sage is a free, open-source alternative to Mathematica, Maple and MATLAB and the SageMath blog recently published SageMathCloud — history and status. The Numerical Algorithms Blog, on the other hand, brings us Testing Matrix Functions Using Identities. Efficient linear algebra routines form one of the cornerstones of modern scientific computing and July saw the publication of a tutorial on how to write your own, super-fast Matrix-Matrix Multiply routine.
Stamps, Making Change and Dealing Cards
When was the last time you used a postage stamp? Even if it was a long time ago, you may have held in your hands a strip of stamps. Maybe you have even tried to fold it into a stack, one stamp wide, so that the strip was easier to store. Have you ever wondered how many ways there are to do so? This post reviews a recent research survey about the topic.
How many ways can you make change for a dollar? This post gives a Lisp program that solves the problem and an analytical solution based on generating functions.
Over at The Aperiodical, home of the math carnival, Dave Wilding has been Discovering Integer Sequences by dealing cards.
Ninjas, Lord Voldemort and Hairy Hay Balls
Colin Beveridge has written a delightful follow-up to Pat Ballew’s post which featured in CoM112 – Trigonometric Trick Secrets of the Mathematica Ninja.
Ben of Math with Bad Drawings fame has written a highly readable rant about a bit of syllabus design which will resonate with anyone teaching (or learning) mathematics in The Voldemort of Calculus Classes.
New math blogger, Grace, recently had an experience in which her math education intersected with her everyday life in Hay Ball Meets the Hairy Ball Theorem.
Tweeting bots, 3D Printed Geometry and Hair ties
(/begin shameless plug) I spend a lot of time on twitter posting as @walkingrandomly (/end shameless plug) and have discovered quite a few mathematical twitter bots in my time. Evelyn Lamb has discovered many many more and has posted reviews of them all over at Roots of Unity.
James Tanton posts fun problems on twitter all the time. One particular problem caught the attention of Mike Lawler because of how 3D printing could help younger children see the geometry.
If you’ve ever wondered what a 120-cell would look like if it were made out of hair ties, wonder no longer because Andrea Hawksley has made one – Hair Tie 120-Cell (By the way, hold your mouse of the title of her blog – it’s cool!)
More Ninjas, Dots and Mandelbrots.
A round-up of fun stuff from Colin Beveridge’s “Flying Colours Maths” – a kind of @icecolbeveridge carnival for Mathematics Carnival.
Have you ever wondered what mathematics is behind those pretty Mandelbrot posters that are all over the place? Find out over at Grey Matters: Blog – Mandelbrot Set: What Exactly Are We Looking At, Anyway?
Did you know that dots have power? To see how much power, check out Keith Devlin’s article The Power of Dots.
Football, drugs and underwear
Since I’m not a big fan of football at the best of times, the football world cup is a distant memory for me (England’s dismal performance didn’t help much either). Fortunately, there’s more than one way to enjoy a world cup and Maxwell’s Demon and The Guardian helped me enjoy it in a data science way: How shocking was Brazil’s 7-1 defeat, mathematically speaking? and Data Visualization, From The World Cup To Drugs In Arkansas.
At this time of year, many of us turn our thoughts to vacations. If you are a math geek, you owe it to yourself to optimise your underwear and pack like a nerd.
Puzzles, Games and playing like a mathmo
When I’m on vacation, I often take a notebook with me so I can do a little mathematics during downtime. My wife and friends find this extremely odd behaviour because mathematics looks like hard work to them..in short, they don’t know how to play like a mathematician.
My job at The University of Manchester is wonderful because it often feels like I am being paid to solve puzzles. While on vacation, however, I have to find some unpaid puzzles to solve and this concentric circles puzzle is an example of one thats fun to solve.
I think that one of the best ways to learn is through play and games and, in a new post over at Math Frolic, a Li’l Game From Martin Gardner introduces mathematical “isomorphism.”
Cartoons and Limits
Mathematics is everywhere, it’s even in the voice bubbles used in web comics! As an added bonus, this blog post contains a little Python programming too.
Next up, we have Part 2 of Bressoud’s masterful investigation (Part I featured in Carnival 112) of how students understand limits.
Resources, Exams and Books
Colleen Young brings us a great set of Standard Form Resources.
Patrick Honner continues his long-running evaluation of New York State math Regents exams, the high school required exams there. In this post, he looks at a multiple choice question that asks the student to identify the graph of an “absolute value equation”.
The Maths Book Club gives details of their most anticipated maths books for the rest of 2014.
Bad Mnemonics and a Dislike of Mathematics
Andrea Hawklsey muses on why some people dislike mathematics when they have interests that suggest they should. Perhaps it has something to do with poorly executed mnemonics when students are taught mathematics, or perhaps its just because they had dull math teachers? Most of my math teachers were awesome and I’ve always felt that this was a major factor in me enjoying the subject.
Skirts, Snow globes and Mathematical Mind Hacking
This edition of the carnival is in danger of becoming the Carnival of Andrea Hawksley since so many of her great posts were submitted! In one of her July posts, she manages to combine fashion and hyperbolic geometry – which is quite a feat!
The author of cavmaths has been musing over the dynamics governing snow globes. Can anyone help out?
Hacking your mind sounds like it might be dangerous but it turns out that it’s really quite safe. Head over to Moebius Noodles to see an example of a mathematical mind hack.
That’s all folks
Thanks to Katie for inviting me to host this month’s carnival, thanks to everyone for submitting so many great articles and thanks to you for reading. Carnival #114 will be hosted over at SquareCirclez.
Introduction
Mathematica 10 was released yesterday amid the usual marketing storm we’ve come to expect for a new product release from Wolfram Research. Some of the highlights of this marketing information include
- Mathematica 10 blog post by Stephen Wolfram
- What’s new in 10? From Wolfram Research
- Alphabetical list of new functions
Without a doubt, there is a lot of great new functionality in this release and I’ve been fortunate enough to have access to some pre-releases for a while now. There is no chance that I can compete with the in-depth treatments given by Wolfram Research of the 700+ new functions in Mathematica 10 so I won’t try. Instead, I’ll hop around some of the new features, settling on those that take my fancy.
Multiple Undo
I’ve been a Mathematica user since version 4 of the product which was released way back in 1999. For the intervening 15 years, one aspect of Mathematica that always frustrated me was the fact that the undo feature could only undo the most recent action. I, along with many other users, repeatedly asked for multiple undo to be implemented but were bitterly disappointed for release after release.
Few things have united Mathematica users more than the need for multiple undo:
- A website with petition calling for multiple undo
- A Facebook page calling for multiple undo
- A very popular Mathematica StackExchange question about multiple undo
Finally, with version 10, our hopes and dreams have been answered and multiple undo is finally here. To be perfectly honest, THIS is the biggest reason to upgrade to version 10. Everything else is just tasty gravy.
Key new areas of functionality
Most of the things considered in this article are whimsical and only scratch the surface of what’s new in Mathematica 10. I support Mathematica (and several other products) at the University of Manchester in the UK and so I tend to be interested in things that my users are interested in. Here’s a brief list of new functionality areas that I’ll be shouting about
- Machine Learning I know several people who are seriously into machine learning but few of them are Mathematica users. I’d love to know what they make of the things on offer here.
- New image processing functions The Image Processing Toolbox is one of the most popular MATLAB toolboxes on my site. I wonder if this will help turn MATLAB-heads. I also know people in a visualisation group who may be interested in the new 3D functions on offer.
- Nonlinear control theoryVarious people in our electrical engineering department are looking at alternatives to MATLAB for control theory. Maple/Maplesim and Scilab/Xcos are the key contenders. SystemModeler is too expensive for us to consider but the amount of control functionality built into Mathematica is useful.
Entities – a new data type for things that Mathematica knows stuff about
One of the new functions I’m excited about is GeoGraphics that pulls down map data from Wolfram’s servers and displays them in the notebook. Obviously, I did not read the manual and so my first attempt at getting a map of the United Kingdom was
GeoGraphics["United Kingdom"]
What I got was a map of my home town, Sheffield, surrounded by a red cell border indicating an error message
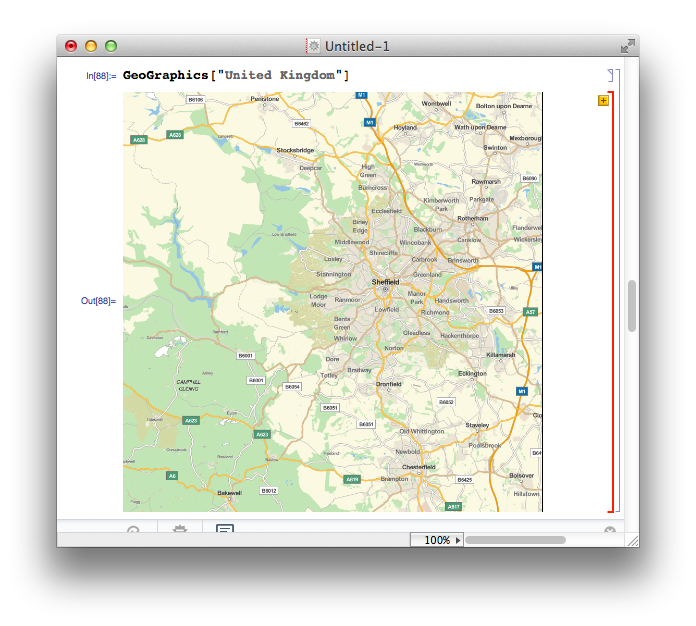
The error message is “United Kingdom is not a Graphics primitive or directive.” The practical upshot of this is that GeoGraphics is not built to take strings as arguments. Fair enough, but why the map of Sheffield? Well, if you call GeoGraphics[] on its own, the default action is to return a map centred on the GeoLocation found by considering your current IP address and it seems that it also does this if you send something bizarre to GeoGraphics. In all honesty, I’d have preferred no map and a simple error message.
In order to get what I want, I have to pass an Entity that represents the UK to the GeoGraphics function. Entities are a new data type in Mathematica 10 and, as far as I can tell, they formally represent ‘things’ that Mathematica knows about. There are several ways to create entities but here I use the new Interpreter function
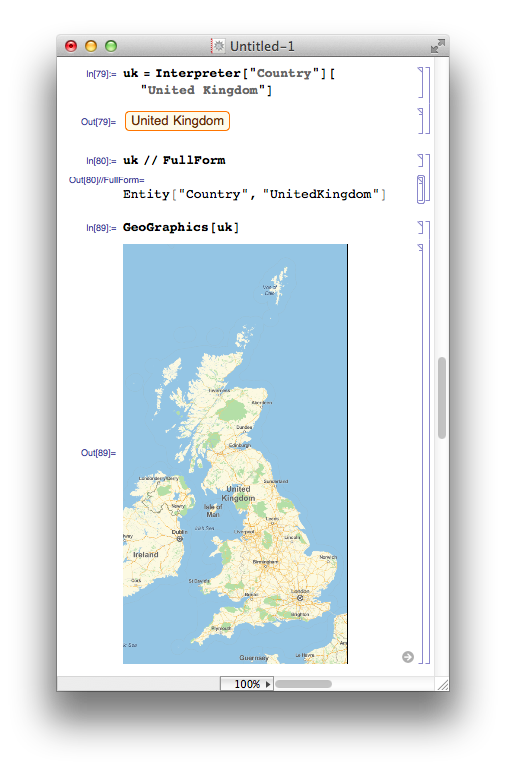
From the above, you can see that Entities have a special new StandardForm but their InputForm looks straightforward enough. One thing to bear in mind here is that all of the above functions require a live internet connection in order to work. For example, on thinking that I had gotten the hang of the Entity syntax, I switched off my internet connection and did
mycity = Entity["City", "Manchester"] During evaluation of In[92]:= URLFetch::invhttp: Couldn't resolve host name. >> During evaluation of In[92]:= WolframAlpha::conopen: Using WolframAlpha requires internet connectivity. Please check your network connection. You may need to configure your firewall program or set a proxy in the Internet Connectivity tab of the Preferences dialog. >> Out[92]= Entity["City", "Manchester"]
So, you need an internet connection even to create entities at this most fundamental level. Perhaps it’s for validation? Turning the internet connection back on and re-running the above command removes the error message but the thing that’s returned isn’t in the new StandardForm:
![]()
If I attempt to display a map using the mycity variable, I get the map of Sheffield that I currently associate with something having gone wrong (If I’d tried this out at work,in Manchester, on the other hand, I would think it had worked perfectly!). So, there is something very wrong with the entity I am using here – It doesn’t look right and it doesn’t work right – clearly that connection to WolframAlpha during its creation was not to do with validation (or if it was, it hasn’t helped). I turn back to the Interpreter function:
In[102]:= mycity2 = Interpreter["City"]["Manchester"] // InputForm
Out[102]//InputForm:= Entity["City", {"Manchester", "Manchester", "UnitedKingdom"}]
So, clearly my guess at how a City entity should look was completely incorrect. For now, I think I’m going to avoid creating Entities directly and rely on the various helper functions such as Interpreter.
What are the limitations of knowledge based computation in Mathematica?
All of the computable data resides in the Wolfram Knowledgebase which is a new name for the data store used by Wolfram Alpha, Mathematica and many other Wolfram products. In his recent blog post, Stephen Wolfram says that they’ll soon release the Wolfram Discovery Platform which will allow large scale access to the Knowledgebase and indicated that ‘basic versions of Mathematica 10 are just set up for small-scale data access.’ I have no idea what this means and what limitations are in place and can’t find anything in the documentation.
Until I understand what limitations there might be, I find myself unwilling to use these data-centric functions for anything important.
IntervalSlider – a new control for Manipulate
I’ll never forget the first time I saw a Mathematica Manipulate – it was at the 2006 International Mathematica Symposium in Avignon when version 6 was still in beta. A Wolfram employee created a fully functional, interactive graphical user interface with just a few lines of code in about 2 minutes –I’d never seen anything like it and was seriously excited about the possibilities it represented.
8 years and 4 Mathematica versions later and we can see just how amazing this interactive functionality turned out to be. It forms the basis of the Wolfram Demonstrations project which currently has 9677 interactive demonstrations covering dozens of fields in engineering, mathematics and science.
Not long after Mathematica introduced Manipulate, the sage team introduced a similar function called interact. The interact function had something that Manipulate did not – an interval slider (see the interaction called ‘Numerical integrals with various rules’ at http://wiki.sagemath.org/interact/calculus for an example of it in use). This control allows the user to specify intervals on a single slider and is very useful in certain circumstances.
As of version 10, Mathematica has a similar control called an IntervalSlider. Here’s some example code of it in use
Manipulate[
pl1 = Plot[Sin[x], {x, -Pi, Pi}];
pl2 = Plot[Sin[x], {x, range[[1]], range[[2]]}, Filling -> Axis,
PlotRange -> {-Pi, Pi}];
inset = Inset["The Integral is approx " <> ToString[
NumberForm[
Integrate[Sin[x], {x, range[[1]], range[[2]]}]
, {3, 3}, ExponentFunction -> (Null &)]], {2, -0.5}];
Show[{pl1, pl2}, Epilog -> inset], {{range, {-1.57, 1.57}}, -3.14,
3.14, ControlType -> IntervalSlider, Appearance -> "Labeled"}]
and here’s the result:

Associations – A new kind of brackets
Mathematica 10 brings a new fundamental data type to the language, associations. As far as I can tell, these are analogous to dictionaries in Python or Julia since they consist of key,value pairs. Since Mathematica has already used every bracket type there is, Wolfram Research have had to invent a new one for associations.
Let’s create an association called scores that links 3 people to their test results
In[1]:= scores = <|"Mike" -> 50.2, "Chris" -> 100.00, "Johnathan" -> 62.3|> Out[1]= <|"Mike" -> 50.2, "Chris" -> 100., "Johnathan" -> 62.3|>
We can see that the Head of the scores object is Association
In[2]:= Head[scores] Out[2]= Association
We can pull out a value by supplying a key. For example, let’s see what value is associated with “Mike”
In[3]:= scores["Mike"] Out[3]= 50.2
All of the usual functions you expect to see for dictionary-type objects are there:-
In[4]:= Keys[scores]
Out[4]= {"Mike", "Chris", "Johnathan"}
In[5]:= Values[scores]
Out[5]= {50.2, 100., 62.3}
In[6]:= (*Show that the key "Bob" does not exist in scores*)
KeyExistsQ[scores, "Bob"]
Out[6]= False
If you ask for a key that does not exist this happens:
In[7]:= scores["Bob"] Out[7]= Missing["KeyAbsent", "Bob"]
There’s a new function called Counts that takes a list and returns an association which counts the unique elements in the list:
In[8]:= Counts[{q, w, e, r, t, y, u, q, w, e}]
Out[8]= <|q -> 2, w -> 2, e -> 2, r -> 1, t -> 1, y -> 1, u -> 1|>
Let’s use this to find something out something interesting, such as the most used words in the classic text, Moby Dick
In[1]:= (*Import Moby Dick from Project gutenberg*) MobyDick = Import["http://www.gutenberg.org/cache/epub/2701/pg2701.txt"]; (*Split into words*) words = StringSplit[MobyDick]; (*Convert all words to lowercase*) words = Map[ToLowerCase[#] &, words]; (*Create an association of words and corresponding word count*) wordcounts = Counts[words]; (*Sort the association by key value*) wordcounts = Sort[wordcounts, Greater]; (*Show the top 10*) wordcounts[[1 ;; 10]] Out[6]= <|"the" -> 14413, "of" -> 6668, "and" -> 6309, "a" -> 4658, "to" -> 4595, "in" -> 4116, "that" -> 2759, "his" -> 2485, "it" -> 1776, "with" -> 1750|>
All told, associations are a useful addition to the Mathematica language and I’m happy to see them included. Many existing functions have been updated to handle Associations making them a fundamental part of the language.
- How to make use of Associations? – a question from Mathematica Stack Exchange
s/Mathematica/Wolfram Language/g
I’ve been programming in Mathematica for well over a decade but the language is no longer called ‘Mathematica’, it’s now called ‘The Wolfram Language.’ I’ll not lie to you, this grates a little but I guess I’ll just have to get used to it. Flicking through the documentation, it seems that a global search and replace has happened and almost every occurrence of ‘Mathematica’ has been changed to ‘The Wolfram Language’
This is part of a huge marketing exercise for Wolfram Research and I guess that part of the reason for doing it is to shift the emphasis away from mathematics to general purpose programming. I wonder if this marketing push will increase the popularity of The Wolfram Language as measured by the TIOBE index? Neither ‘Mathematica’ or ‘The Wolfram Language’ is listed in the top 100 and last time I saw more detailed results had it at number 128.
Fractal exploration
One of Mathematica’s competitors, Maple, had a new release recently which saw the inclusion of a set of fractal exploration functions. Although I found this a fun and interesting addition to the product, I did think it rather an odd thing to do. After all, if any software vendor is stuck for functionality to implement, there is a whole host of things to do that rank higher in most user’s list of priorities than a function that plots a standard fractal.
It seems, however, that both Maplesoft and Wolfram Research have seen a market for such functionality. Mathematica 10 comes with a set of functions for exploring the Mandelbrot and Julia sets. The Mandelbrot set alone accounts for at least 5 of Mathematica 10’s 700 new functions:- MandelbrotSetBoettcher, MandelbrotSetDistance, MandelbrotSetIterationCount, MandelbrotSetMemberQ and MandelbrotSetPlot.
MandelbrotSetPlot[]
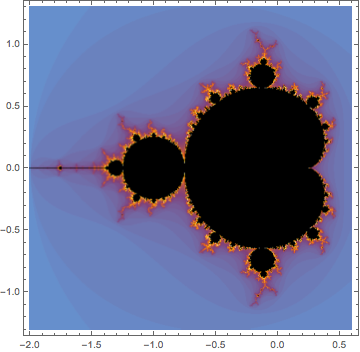
Barcodes
I found this more fun than is reasonable! Mathematica can generate and recognize bar codes and QR codes in various formats. For example
BarcodeImage["www.walkingrandomly.com", "QR"]

Scanning the result using my mobile phone brings me right back home :)
Unit Testing
A decent unit testing framework is essential to anyone who’s planning to do serious software development. Python has had one for years, MATLAB got one in 2013a and now Mathematica has one. This is good news! I’ve not had chance to look at it in any detail, however. For now, I’ll simply nod in approval and send you to the documentation. Opinions welcomed.
Disappointments in Mathematica 10
There’s a lot to like in Mathematica 10 but there’s also several aspects that disappointed me
No update to RLink
Version 9 of Mathematica included integration with R which excited quite a few people I work with. Sadly, it seems that there has been no work on RLink at all between version 9 and 10. Issues include:
- The version of R bundled with RLink is stuck at 2.14.0 which is almost 3 years old. On Mac and Linux, it is not possible to use your own installation of R so we really are stuck with 2.14. On Windows, it is possible to use your own installation of R but CHECK THAT version 3 issue has been fixed http://mathematica.stackexchange.com/questions/27064/rlink-and-r-v3-0-1
- It is only possible to install extra R packages on Windows. Mac and Linux users are stuck with just base R.
This lack of work on RLink really is a shame since the original release was a very nice piece of work.
If the combination of R and notebook environment is something that interests you, I think that the current best solution is to use the R magics from within the IPython notebook.
No update to CUDA/OpenCL functions
Mathematica introduced OpenCL and CUDA functionality back in version 8 but very little appears to have been done in this area since. In contrast, MATLAB has improved on its CUDA functionality (it has never supported OpenCL) every release since its introduction in 2010b and is now superb!
Accelerating computations using GPUs is a big deal at the University of Manchester (my employer) which has a GPU-club made up of around 250 researchers. Sadly, I’ll have nothing to report at the next meeting as far as Mathematica is concerned.
FinancialData is broken (and this worries me more than you might expect)
I wrote some code a while ago that used the FinancialData function and it suddenly stopped working because of some issue with the underlying data source. In short, this happens:
In[12]:= FinancialData["^FTAS", "Members"] Out[12]= Missing["NotAvailable"]
This wouldn’t be so bad if it were not for the fact that an example given in Mathematica’s own documentation fails in exactly the same way! The documentation in both version 9 and 10 give this example:
In[1]:= FinancialData["^DJI", "Members"]
Out[1]= {"AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", \
"GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KFT", "KO", "MCD", \
"MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", \
"XOM"}
but what you actually get is
In[1]:= FinancialData["^DJI", "Members"] Out[1]= Missing["NotAvailable"]
For me, the implications of this bug are far more reaching than a few broken examples. Wolfram Research are making a big deal of the fact that Mathematica gives you access to computable data sets, data sets that you can just use in your code and not worry about the details.
Well, I did just as they suggest, and it broke!
Summary
I’ve had a lot of fun playing with Mathematica 10 but that’s all I’ve really done so far – play – something that’s probably obvious from my choice of topics in this article. Even through play, however, I can tell you that this is a very solid new release with some exciting new functionality. Old-time Mathematica users will want to upgrade for multiple-undo alone and people new to the system have an awful lot of toys to play with.
Looking to the future of the system, I feel excited and concerned in equal measure. There is so much new functionality on offer that it’s almost overwhelming and I love the fact that its all integrated into the core system. I’ve always been grateful of the fact that Mathematica hasn’t gone down the route of hiving functionality off into add-on products like MATLAB does with its numerous toolboxes.
My concerns center around the data and Stephen Wolfram’s comment ‘basic versions of Mathematica 10 are just set up for small-scale data access.’ What does this mean? What are the limitations and will this lead to serious users having to purchase add-ons that would effectively be data-toolboxes?
Final
Have you used Mathematica 10 yet? If so, what do you think of it? Any problems? What’s your favorite function?
Mathematica 10 links
- Playing with Mathematica on Raspberry Pi – The Raspberry Pi was the first platform that saw Mathematica version 10…and it’s free!
Consider the following code
function testpow()
%function to compare integer powers with repeated multiplication
rng default
a=rand(1,10000000)*10;
disp('speed of ^4 using pow')
tic;test4p = a.^4;toc
disp('speed of ^4 using multiply')
tic;test4m = a.*a.*a.*a;toc
disp('maximum difference in results');
max_diff = max(abs(test4p-test4m))
end
On running it on my late 2013 Macbook Air with a Haswell Intel i5 using MATLAB 2013b, I get the following results
speed of ^4 using pow Elapsed time is 0.527485 seconds. speed of ^4 using multiply Elapsed time is 0.025474 seconds. maximum difference in results max_diff = 1.8190e-12
In this case (derived from a real-world case), using repeated multiplication is around twenty times faster than using integer powers in MATLAB. This leads to some questions:-
- Why the huge speed difference?
- Would a similar speed difference be seen in other systems–R, Python, Julia etc?
- Would we see the same speed difference on other operating systems/CPUs?
- Are there any numerical reasons why using repeated multiplication instead of integer powers is a bad idea?
The R code used for this example comes from Barry Rowlingson, so huge thanks to him.
A question I get asked a lot is ‘How can I do nonlinear least squares curve fitting in X?’ where X might be MATLAB, Mathematica or a whole host of alternatives. Since this is such a common query, I thought I’d write up how to do it for a very simple problem in several systems that I’m interested in
This is the R version. For other versions,see the list below
- Simple nonlinear least squares curve fitting in Julia
- Simple nonlinear least squares curve fitting in Maple
- Simple nonlinear least squares curve fitting in Mathematica
- Simple nonlinear least squares curve fitting in MATLAB
- Simple nonlinear least squares curve fitting in Python
The problem
xdata = -2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9 ydata = 0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001
and you’d like to fit the function

using nonlinear least squares. You’re starting guesses for the parameters are p1=1 and P2=0.2
For now, we are primarily interested in the following results:
- The fit parameters
- Sum of squared residuals
- Parameter confidence intervals
Future updates of these posts will show how to get other results. Let me know what you are most interested in.
Solution in R
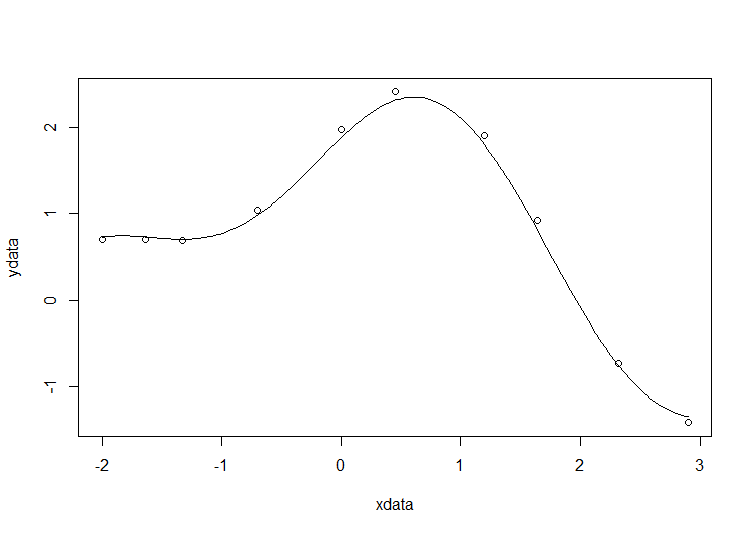
# construct the data vectors using c() xdata = c(-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9) ydata = c(0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001) # look at it plot(xdata,ydata) # some starting values p1 = 1 p2 = 0.2 # do the fit fit = nls(ydata ~ p1*cos(p2*xdata) + p2*sin(p1*xdata), start=list(p1=p1,p2=p2)) # summarise summary(fit)
This gives
Formula: ydata ~ p1 * cos(p2 * xdata) + p2 * sin(p1 * xdata) Parameters: Estimate Std. Error t value Pr(>|t|) p1 1.881851 0.027430 68.61 2.27e-12 *** p2 0.700230 0.009153 76.51 9.50e-13 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 0.08202 on 8 degrees of freedom Number of iterations to convergence: 7 Achieved convergence tolerance: 2.189e-06
Draw the fit on the plot by getting the prediction from the fit at 200 x-coordinates across the range of xdata
new = data.frame(xdata = seq(min(xdata),max(xdata),len=200)) lines(new$xdata,predict(fit,newdata=new))
Getting the sum of squared residuals is easy enough:
sum(resid(fit)^2)
Which gives
[1] 0.0538127
Finally, lets get the parameter confidence intervals.
confint(fit)
Which gives
Waiting for profiling to be done...
2.5% 97.5%
p1 1.8206081 1.9442365
p2 0.6794193 0.7209843
A question I get asked a lot is ‘How can I do nonlinear least squares curve fitting in X?’ where X might be MATLAB, Mathematica or a whole host of alternatives. Since this is such a common query, I thought I’d write up how to do it for a very simple problem in several systems that I’m interested in
This is the MATLAB version. For other versions,see the list below
- Simple nonlinear least squares curve fitting in Julia
- Simple nonlinear least squares curve fitting in Maple
- Simple nonlinear least squares curve fitting in Mathematica
- Simple nonlinear least squares curve fitting in Python
- Simple nonlinear least squares curve fitting in R
The problem
xdata = -2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9 ydata = 0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001
and you’d like to fit the function
using nonlinear least squares. You’re starting guesses for the parameters are p1=1 and P2=0.2
For now, we are primarily interested in the following results:
- The fit parameters
- Sum of squared residuals
Future updates of these posts will show how to get other results such as confidence intervals. Let me know what you are most interested in.
How you proceed depends on which toolboxes you have. Contrary to popular belief, you don’t need the Curve Fitting toolbox to do curve fitting…particularly when the fit in question is as basic as this. Out of the 90+ toolboxes sold by The Mathworks, I’ve only been able to look through the subset I have access to so I may have missed some alternative solutions.
Pure MATLAB solution (No toolboxes)
In order to perform nonlinear least squares curve fitting, you need to minimise the squares of the residuals. This means you need a minimisation routine. Basic MATLAB comes with the fminsearch function which is based on the Nelder-Mead simplex method. For this particular problem, it works OK but will not be suitable for more complex fitting problems. Here’s the code
format compact format long xdata = [-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9]; ydata = [0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001]; %Function to calculate the sum of residuals for a given p1 and p2 fun = @(p) sum((ydata - (p(1)*cos(p(2)*xdata)+p(2)*sin(p(1)*xdata))).^2); %starting guess pguess = [1,0.2]; %optimise [p,fminres] = fminsearch(fun,pguess)
This gives the following results
p = 1.881831115804464 0.700242006994123 fminres = 0.053812720914713
All we get here are the parameters and the sum of squares of the residuals. If you want more information such as 95% confidence intervals, you’ll have a lot more hand-coding to do. Although fminsearch works fine in this instance, it soon runs out of steam for more complex problems.
MATLAB with optimisation toolbox
With respect to this problem, the optimisation toolbox gives you two main advantages over pure MATLAB. The first is that better optimisation routines are available so more complex problems (such as those with constraints) can be solved and in less time. The second is the provision of the lsqcurvefit function which is specifically designed to solve curve fitting problems. Here’s the code
format long format compact xdata = [-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9]; ydata = [0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001]; %Note that we don't have to explicitly calculate residuals fun = @(p,xdata) p(1)*cos(p(2)*xdata)+p(2)*sin(p(1)*xdata); %starting guess pguess = [1,0.2]; [p,fminres] = lsqcurvefit(fun,pguess,xdata,ydata)
This gives the results
p = 1.881848414551983 0.700229137656802 fminres = 0.053812696487326
MATLAB with statistics toolbox
There are two interfaces I know of in the stats toolbox and both of them give a lot of information about the fit. The problem set up is the same in both cases
%set up for both fit commands in the stats toolbox xdata = [-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9]; ydata = [0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001]; fun = @(p,xdata) p(1)*cos(p(2)*xdata)+p(2)*sin(p(1)*xdata); pguess = [1,0.2];
Method 1 makes use of NonLinearModel.fit
mdl = NonLinearModel.fit(xdata,ydata,fun,pguess)
The returned object is a NonLinearModel object
class(mdl) ans = NonLinearModel
which contains all sorts of useful stuff
mdl =
Nonlinear regression model:
y ~ p1*cos(p2*xdata) + p2*sin(p1*xdata)
Estimated Coefficients:
Estimate SE
p1 1.8818508110535 0.027430139389359
p2 0.700229815076442 0.00915260662357553
tStat pValue
p1 68.6052223191956 2.26832562501304e-12
p2 76.5060538352836 9.49546284187105e-13
Number of observations: 10, Error degrees of freedom: 8
Root Mean Squared Error: 0.082
R-Squared: 0.996, Adjusted R-Squared 0.995
F-statistic vs. zero model: 1.43e+03, p-value = 6.04e-11
If you don’t need such heavyweight infrastructure, you can make use of the statistic toolbox’s nlinfit function
[p,R,J,CovB,MSE,ErrorModelInfo] = nlinfit(xdata,ydata,fun,pguess);
Along with our parameters (p) this also provides the residuals (R), Jacobian (J), Estimated variance-covariance matrix (CovB), Mean Squared Error (MSE) and a structure containing information about the error model fit (ErrorModelInfo).
Both nlinfit and NonLinearModel.fit use the same minimisation algorithm which is based on Levenberg-Marquardt
MATLAB with Symbolic Toolbox
MATLAB’s symbolic toolbox provides a completely separate computer algebra system called Mupad which can handle nonlinear least squares fitting via its stats::reg function. Here’s how to solve our problem in this environment.
First, you need to start up the mupad application. You can do this by entering
mupad
into MATLAB. Once you are in mupad, the code looks like this
xdata := [-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9]: ydata := [0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001]: stats::reg(xdata,ydata,p1*cos(p2*x)+p2*sin(p1*x),[x],[p1,p2],StartingValues=[1,0.2])
The result returned is
[[1.88185085, 0.7002298172], 0.05381269642]
These are our fitted parameters,p1 and p2, along with the sum of squared residuals. The documentation tells us that the optimisation algorithm is Levenberg-Marquardt– this is rather better than the simplex algorithm used by basic MATLAB’s fminsearch.
MATLAB with the NAG Toolbox
The NAG Toolbox for MATLAB is a commercial product offered by the UK based Numerical Algorithms Group. Their main products are their C and Fortran libraries but they also have a comprehensive MATLAB toolbox that contains something like 1500+ functions. My University has a site license for pretty much everything they put out and we make great use of it all. One of the benefits of the NAG toolbox over those offered by The Mathworks is speed. NAG is often (but not always) faster since its based on highly optimized, compiled Fortran. One of the problems with the NAG toolbox is that it is difficult to use compared to Mathworks toolboxes.
In an earlier blog post, I showed how to create wrappers for the NAG toolbox to create an easy to use interface for basic nonlinear curve fitting. Here’s how to solve our problem using those wrappers.
format long format compact xdata = [-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9]; ydata = [0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001]; %Note that we don't have to explicitly calculate residuals fun = @(p,xdata) p(1)*cos(p(2)*xdata)+p(2)*sin(p(1)*xdata); start = [1,0.2]; [p,fminres]=nag_lsqcurvefit(fun,start,xdata,ydata)
which gives
Warning: nag_opt_lsq_uncon_mod_func_easy (e04fy) returned a warning indicator (5) p = 1.881850904268710 0.700229557886739 fminres = 0.053812696425390
For convenience, here’s the two files you’ll need to run the above (you’ll also need the NAG Toolbox for MATLAB of course)
MATLAB with curve fitting toolbox
One would expect the curve fitting toolbox to be able to fit such a simple curve and one would be right :)
xdata = [-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9];
ydata = [0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001];
opt = fitoptions('Method','NonlinearLeastSquares',...
'Startpoint',[1,0.2]);
f = fittype('p1*cos(p2*x)+p2*sin(p1*x)','options',opt);
fitobject = fit(xdata',ydata',f)
Note that, unlike every other Mathworks method shown here, xdata and ydata have to be column vectors. The result looks like this
fitobject =
General model:
fitobject(x) = p1*cos(p2*x)+p2*sin(p1*x)
Coefficients (with 95% confidence bounds):
p1 = 1.882 (1.819, 1.945)
p2 = 0.7002 (0.6791, 0.7213)
fitobject is of type cfit:
class(fitobject) ans = cfit
In this case it contains two fields, p1 and p2, which are the parameters we are looking for
>> fieldnames(fitobject)
ans =
'p1'
'p2'
>> fitobject.p1
ans =
1.881848414551983
>> fitobject.p2
ans =
0.700229137656802
For maximum information, call the fit command like this:
[fitobject,gof,output] = fit(xdata',ydata',f)
fitobject =
General model:
fitobject(x) = p1*cos(p2*x)+p2*sin(p1*x)
Coefficients (with 95% confidence bounds):
p1 = 1.882 (1.819, 1.945)
p2 = 0.7002 (0.6791, 0.7213)
gof =
sse: 0.053812696487326
rsquare: 0.995722238905101
dfe: 8
adjrsquare: 0.995187518768239
rmse: 0.082015773244637
output =
numobs: 10
numparam: 2
residuals: [10x1 double]
Jacobian: [10x2 double]
exitflag: 3
firstorderopt: 3.582047395989108e-05
iterations: 6
funcCount: 21
cgiterations: 0
algorithm: 'trust-region-reflective'
message: [1x86 char]
A question I get asked a lot is ‘How can I do nonlinear least squares curve fitting in X?’ where X might be MATLAB, Mathematica or a whole host of alternatives. Since this is such a common query, I thought I’d write up how to do it for a very simple problem in several systems that I’m interested in
This is the Maple version. For other versions,see the list below
- Simple nonlinear least squares curve fitting in Julia
- Simple nonlinear least squares curve fitting in Mathematica
- Simple nonlinear least squares curve fitting in MATLAB
- Simple nonlinear least squares curve fitting in Python
- Simple nonlinear least squares curve fitting in R
The problem
xdata = -2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9 ydata = 0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001
and you’d like to fit the function
using nonlinear least squares. You’re starting guesses for the parameters are p1=1 and P2=0.2
For now, we are primarily interested in the following results:
- The fit parameters
- Sum of squared residuals
Future updates of these posts will show how to get other results such as confidence intervals. Let me know what you are most interested in.
Solution in Maple
Maple’s user interface is quite user friendly and it uses non-linear optimization routines from The Numerical Algorithms Group under the hood. Here’s the code to get the parameter values and sum of squares of residuals
with(Statistics): xdata := Vector([-2, -1.64, -1.33, -.7, 0, .45, 1.2, 1.64, 2.32, 2.9], datatype = float): ydata := Vector([.699369, .700462, .695354, 1.03905, 1.97389, 2.41143, 1.91091, .919576, -.730975, -1.42001], datatype = float): NonlinearFit(p1*cos(p2*x)+p2*sin(p1*x), xdata, ydata, x, initialvalues = [p1 = 1, p2 = .2], output = [parametervalues, residualsumofsquares])
which gives the result
[[p1 = 1.88185090465902, p2 = 0.700229557992540], 0.05381269642]
Various other outputs can be specified in the output vector such as:
- solutionmodule
- degreesoffreedom
- leastsquaresfunction
- parametervalues
- parametervector
- residuals
- residualmeansquare
- residualstandarddeviation
- residualsumofsquares.
The meanings of the above are mostly obvious. In those cases where they aren’t, you can look them up in the documentation link below.
Further documentation
The full documentation for Maple’s NonlinearFit command is at http://www.maplesoft.com/support/help/Maple/view.aspx?path=Statistics%2fNonlinearFit
Notes
I used Maple 17.02 on 64bit Windows to run the code in this post.
A question I get asked a lot is ‘How can I do nonlinear least squares curve fitting in X?’ where X might be MATLAB, Mathematica or a whole host of alternatives. Since this is such a common query, I thought I’d write up how to do it for a very simple problem in several systems that I’m interested in
This is the Python version. For other versions,see the list below
- Simple nonlinear least squares curve fitting in Julia
- Simple nonlinear least squares curve fitting in Maple
- Simple nonlinear least squares curve fitting in Mathematica
- Simple nonlinear least squares curve fitting in MATLAB
- Simple nonlinear least squares curve fitting in R
The problem
xdata = -2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9 ydata = 0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001
and you’d like to fit the function
using nonlinear least squares. You’re starting guesses for the parameters are p1=1 and P2=0.2
For now, we are primarily interested in the following results:
- The fit parameters
- Sum of squared residuals
Future updates of these posts will show how to get other results such as confidence intervals. Let me know what you are most interested in.
Python solution using scipy
Here, I use the curve_fit function from scipy
import numpy as np from scipy.optimize import curve_fit xdata = np.array([-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9]) ydata = np.array([0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001]) def func(x, p1,p2): return p1*np.cos(p2*x) + p2*np.sin(p1*x) popt, pcov = curve_fit(func, xdata, ydata,p0=(1.0,0.2))
The variable popt contains the fit parameters
array([ 1.88184732, 0.70022901])
We need to do a little more work to get the sum of squared residuals
p1 = popt[0] p2 = popt[1] residuals = ydata - func(xdata,p1,p2) fres = sum(residuals**2)
which gives
0.053812696547933969
- I’ve put this in an Ipython notebook which can be downloaded here. There is also a pdf version of the notebook.
A question I get asked a lot is ‘How can I do nonlinear least squares curve fitting in X?’ where X might be MATLAB, Mathematica or a whole host of alternatives. Since this is such a common query, I thought I’d write up how to do it for a very simple problem in several systems that I’m interested in
This is the Mathematica version. For other versions,see the list below
- Simple nonlinear least squares curve fitting in Maple
- Simple nonlinear least squares curve fitting in Julia
- Simple nonlinear least squares curve fitting in MATLAB
- Simple nonlinear least squares curve fitting in Python
- Simple nonlinear least squares curve fitting in R
The problem
You have the following 10 data points
xdata = -2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9 ydata = 0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001
and you’d like to fit the function
using nonlinear least squares. You’re starting guesses for the parameters are p1=1 and P2=0.2
For now, we are primarily interested in the following results:
- The fit parameters
- Sum of squared residuals
Future updates of these posts will show how to get other results such as confidence intervals. Let me know what you are most interested in.
Mathematica Solution using FindFit
FindFit is the basic nonlinear curve fitting routine in Mathematica
xdata={-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9};
ydata={0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001};
(*Mathematica likes to have the data in the form {{x1,y1},{x2,y2},..}*)
data = Partition[Riffle[xdata, ydata], 2];
FindFit[data, p1*Cos[p2 x] + p2*Sin[p1 x], {{p1, 1}, {p2, 0.2}}, x]
Out[4]:={p1->1.88185,p2->0.70023}
Mathematica Solution using NonlinearModelFit
You can get a lot more information about the fit using the NonLinearModelFit function
(*Set up data as before*)
xdata={-2,-1.64,-1.33,-0.7,0,0.45,1.2,1.64,2.32,2.9};
ydata={0.699369,0.700462,0.695354,1.03905,1.97389,2.41143,1.91091,0.919576,-0.730975,-1.42001};
data = Partition[Riffle[xdata, ydata], 2];
(*Create the NonLinearModel object*)
nlm = NonlinearModelFit[data, p1*Cos[p2 x] + p2*Sin[p1 x], {{p1, 1}, {p2, 0.2}}, x];
The NonLinearModel object contains many properties that may be useful to us. Here’s how to list them all
nlm["Properties"]
Out[10]= {"AdjustedRSquared", "AIC", "AICc", "ANOVATable", \
"ANOVATableDegreesOfFreedom", "ANOVATableEntries", "ANOVATableMeanSquares", \
"ANOVATableSumsOfSquares", "BestFit", "BestFitParameters", "BIC", \
"CorrelationMatrix", "CovarianceMatrix", "CurvatureConfidenceRegion", "Data", \
"EstimatedVariance", "FitCurvatureTable", "FitCurvatureTableEntries", \
"FitResiduals", "Function", "HatDiagonal", "MaxIntrinsicCurvature", \
"MaxParameterEffectsCurvature", "MeanPredictionBands", \
"MeanPredictionConfidenceIntervals", "MeanPredictionConfidenceIntervalTable", \
"MeanPredictionConfidenceIntervalTableEntries", "MeanPredictionErrors", \
"ParameterBias", "ParameterConfidenceIntervals", \
"ParameterConfidenceIntervalTable", \
"ParameterConfidenceIntervalTableEntries", "ParameterConfidenceRegion", \
"ParameterErrors", "ParameterPValues", "ParameterTable", \
"ParameterTableEntries", "ParameterTStatistics", "PredictedResponse", \
"Properties", "Response", "RSquared", "SingleDeletionVariances", \
"SinglePredictionBands", "SinglePredictionConfidenceIntervals", \
"SinglePredictionConfidenceIntervalTable", \
"SinglePredictionConfidenceIntervalTableEntries", "SinglePredictionErrors", \
"StandardizedResiduals", "StudentizedResiduals"}
Let’s extract the fit parameters, 95% confidence levels and residuals
{params, confidenceInt, res} =
nlm[{"BestFitParameters", "ParameterConfidenceIntervals", "FitResiduals"}]
Out[22]= {{p1 -> 1.88185,
p2 -> 0.70023}, {{1.8186, 1.9451}, {0.679124,
0.721336}}, {-0.0276906, -0.0322944, -0.0102488, 0.0566244,
0.0920392, 0.0976307, 0.114035, 0.109334, 0.0287154, -0.0700442}}
The parameters are given as replacement rules. Here, we convert them to pure numbers
{p1, p2} = {p1, p2} /. params
Out[38]= {1.88185,0.70023}
Although only a few decimal places are shown, p1 and p2 are stored in full double precision. You can see this by converting to InputForm
InputForm[{p1, p2}]
Out[43]//InputForm=
{1.8818508498053645, 0.7002298171759191}
Similarly, let’s look at the 95% confidence interval, extracted earlier, in full precision
confidenceInt // InputForm
Out[44]//InputForm=
{{1.8185969887307214, 1.9451047108800077},
{0.6791239458086734, 0.7213356885431649}}
Calculate the sum of squared residuals
resnorm = Total[res^2] Out[45]= 0.0538127
Notes
I used Mathematica 9 on Windows 7 64bit to perform these calculations
As soon as I heard the news that Mathematica was being made available completely free on the Raspberry Pi, I just had to get myself a Pi and have a play. So, I bought the Raspberry Pi Advanced Kit from my local Maplin Electronics store, plugged it to the kitchen telly and booted it up. The exercise made me miss my father because the last time I plugged a computer into the kitchen telly was when I was 8 years old; it was Christmas morning and dad and I took our first steps into a new world with my Sinclair Spectrum 48K.
How to install Mathematica on the Raspberry Pi
Future raspberry pis wll have Mathematica installed by default but mine wasn’t new enough so I just typed the following at the command line
sudo apt-get update && sudo apt-get install wolfram-engine
On my machine, I was told
The following extra packages will be installed: oracle-java7-jdk The following NEW packages will be installed: oracle-java7-jdk wolfram-engine 0 upgraded, 2 newly installed, 0 to remove and 1 not upgraded. Need to get 278 MB of archives. After this operation, 588 MB of additional disk space will be used.
So, it seems that Mathematica needs Oracle’s Java and that’s being installed for me as well. The combination of the two is going to use up 588MB of disk space which makes me glad that I have an 8Gb SD card in my pi.
Mathematica version 10!
On starting Mathematica on the pi, my first big surprise was the version number. I am the administrator of an unlimited academic site license for Mathematica at The University of Manchester and the latest version we can get for our PCs at the time of writing is 9.0.1. My free pi version is at version 10! The first clue is the installation directory:
/opt/Wolfram/WolframEngine/10.0
and the next clue is given by evaluating $Version in Mathematica itself
In[2]:= $Version Out[2]= "10.0 for Linux ARM (32-bit) (November 19, 2013)"
To get an idea of what’s new in 10, I evaluated the following command on Mathematica on the Pi
Export["PiFuncs.dat",Names["System`*"]]
This creates a PiFuncs.dat file which tells me the list of functions in the System context on the version of Mathematica on the pi. Transfer this over to my Windows PC and import into Mathematica 9.0.1 with
pifuncs = Flatten[Import["PiFuncs.dat"]];
Get the list of functions from version 9.0.1 on Windows:
winVer9funcs = Names["System`*"];
Finally, find out what’s in pifuncs but not winVer9funcs
In[16]:= Complement[pifuncs, winVer9funcs]
Out[16]= {"Activate", "AffineStateSpaceModel", "AllowIncomplete", \
"AlternatingFactorial", "AntihermitianMatrixQ", \
"AntisymmetricMatrixQ", "APIFunction", "ArcCurvature", "ARCHProcess", \
"ArcLength", "Association", "AsymptoticOutputTracker", \
"AutocorrelationTest", "BarcodeImage", "BarcodeRecognize", \
"BoxObject", "CalendarConvert", "CanonicalName", "CantorStaircase", \
"ChromaticityPlot", "ClassifierFunction", "Classify", \
"ClipPlanesStyle", "CloudConnect", "CloudDeploy", "CloudDisconnect", \
"CloudEvaluate", "CloudFunction", "CloudGet", "CloudObject", \
"CloudPut", "CloudSave", "ColorCoverage", "ColorDistance", "Combine", \
"CommonName", "CompositeQ", "Computed", "ConformImages", "ConformsQ", \
"ConicHullRegion", "ConicHullRegion3DBox", "ConicHullRegionBox", \
"ConstantImage", "CountBy", "CountedBy", "CreateUUID", \
"CurrencyConvert", "DataAssembly", "DatedUnit", "DateFormat", \
"DateObject", "DateObjectQ", "DefaultParameterType", \
"DefaultReturnType", "DefaultView", "DeviceClose", "DeviceConfigure", \
"DeviceDriverRepository", "DeviceExecute", "DeviceInformation", \
"DeviceInputStream", "DeviceObject", "DeviceOpen", "DeviceOpenQ", \
"DeviceOutputStream", "DeviceRead", "DeviceReadAsynchronous", \
"DeviceReadBuffer", "DeviceReadBufferAsynchronous", \
"DeviceReadTimeSeries", "Devices", "DeviceWrite", \
"DeviceWriteAsynchronous", "DeviceWriteBuffer", \
"DeviceWriteBufferAsynchronous", "DiagonalizableMatrixQ", \
"DirichletBeta", "DirichletEta", "DirichletLambda", "DSolveValue", \
"Entity", "EntityProperties", "EntityProperty", "EntityValue", \
"Enum", "EvaluationBox", "EventSeries", "ExcludedPhysicalQuantities", \
"ExportForm", "FareySequence", "FeedbackLinearize", "Fibonorial", \
"FileTemplate", "FileTemplateApply", "FindAllPaths", "FindDevices", \
"FindEdgeIndependentPaths", "FindFundamentalCycles", \
"FindHiddenMarkovStates", "FindSpanningTree", \
"FindVertexIndependentPaths", "Flattened", "ForeignKey", \
"FormatName", "FormFunction", "FormulaData", "FormulaLookup", \
"FractionalGaussianNoiseProcess", "FrenetSerretSystem", "FresnelF", \
"FresnelG", "FullInformationOutputRegulator", "FunctionDomain", \
"FunctionRange", "GARCHProcess", "GeoArrow", "GeoBackground", \
"GeoBoundaryBox", "GeoCircle", "GeodesicArrow", "GeodesicLine", \
"GeoDisk", "GeoElevationData", "GeoGraphics", "GeoGridLines", \
"GeoGridLinesStyle", "GeoLine", "GeoMarker", "GeoPoint", \
"GeoPolygon", "GeoProjection", "GeoRange", "GeoRangePadding", \
"GeoRectangle", "GeoRhumbLine", "GeoStyle", "Graph3D", "GroupBy", \
"GroupedBy", "GrowCutBinarize", "HalfLine", "HalfPlane", \
"HiddenMarkovProcess", "ï¯", "ï ", "ï ", "ï ", "ï ", "ï ", \
"ï
", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", \
"ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", \
"ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ", "ï ¦", "ï ª", \
"ï ¯", "ï \.b2", "ï \.b3", "IgnoringInactive", "ImageApplyIndexed", \
"ImageCollage", "ImageSaliencyFilter", "Inactivate", "Inactive", \
"IncludeAlphaChannel", "IncludeWindowTimes", "IndefiniteMatrixQ", \
"IndexedBy", "IndexType", "InduceType", "InferType", "InfiniteLine", \
"InfinitePlane", "InflationAdjust", "InflationMethod", \
"IntervalSlider", "ï ¨", "ï ¢", "ï ©", "ï ¤", "ï \[Degree]", "ï ", \
"ï ¡", "ï «", "ï ®", "ï §", "ï £", "ï ¥", "ï \[PlusMinus]", \
"ï \[Not]", "JuliaSetIterationCount", "JuliaSetPlot", \
"JuliaSetPoints", "KEdgeConnectedGraphQ", "Key", "KeyDrop", \
"KeyExistsQ", "KeyIntersection", "Keys", "KeySelect", "KeySort", \
"KeySortBy", "KeyTake", "KeyUnion", "KillProcess", \
"KVertexConnectedGraphQ", "LABColor", "LinearGradientImage", \
"LinearizingTransformationData", "ListType", "LocalAdaptiveBinarize", \
"LocalizeDefinitions", "LogisticSigmoid", "Lookup", "LUVColor", \
"MandelbrotSetIterationCount", "MandelbrotSetMemberQ", \
"MandelbrotSetPlot", "MinColorDistance", "MinimumTimeIncrement", \
"MinIntervalSize", "MinkowskiQuestionMark", "MovingMap", \
"NegativeDefiniteMatrixQ", "NegativeSemidefiniteMatrixQ", \
"NonlinearStateSpaceModel", "Normalized", "NormalizeType", \
"NormalMatrixQ", "NotebookTemplate", "NumberLinePlot", "OperableQ", \
"OrthogonalMatrixQ", "OverwriteTarget", "PartSpecification", \
"PlotRangeClipPlanesStyle", "PositionIndex", \
"PositiveSemidefiniteMatrixQ", "Predict", "PredictorFunction", \
"PrimitiveRootList", "ProcessConnection", "ProcessInformation", \
"ProcessObject", "ProcessStatus", "Qualifiers", "QuantityVariable", \
"QuantityVariableCanonicalUnit", "QuantityVariableDimensions", \
"QuantityVariableIdentifier", "QuantityVariablePhysicalQuantity", \
"RadialGradientImage", "RandomColor", "RegularlySampledQ", \
"RemoveBackground", "RequiredPhysicalQuantities", "ResamplingMethod", \
"RiemannXi", "RSolveValue", "RunProcess", "SavitzkyGolayMatrix", \
"ScalarType", "ScorerGi", "ScorerGiPrime", "ScorerHi", \
"ScorerHiPrime", "ScriptForm", "Selected", "SendMessage", \
"ServiceConnect", "ServiceDisconnect", "ServiceExecute", \
"ServiceObject", "ShowWhitePoint", "SourceEntityType", \
"SquareMatrixQ", "Stacked", "StartDeviceHandler", "StartProcess", \
"StateTransformationLinearize", "StringTemplate", "StructType", \
"SystemGet", "SystemsModelMerge", "SystemsModelVectorRelativeOrder", \
"TemplateApply", "TemplateBlock", "TemplateExpression", "TemplateIf", \
"TemplateObject", "TemplateSequence", "TemplateSlot", "TemplateWith", \
"TemporalRegularity", "ThermodynamicData", "ThreadDepth", \
"TimeObject", "TimeSeries", "TimeSeriesAggregate", \
"TimeSeriesInsert", "TimeSeriesMap", "TimeSeriesMapThread", \
"TimeSeriesModel", "TimeSeriesModelFit", "TimeSeriesResample", \
"TimeSeriesRescale", "TimeSeriesShift", "TimeSeriesThread", \
"TimeSeriesWindow", "TimeZoneConvert", "TouchPosition", \
"TransformedProcess", "TrapSelection", "TupleType", "TypeChecksQ", \
"TypeName", "TypeQ", "UnitaryMatrixQ", "URLBuild", "URLDecode", \
"URLEncode", "URLExistsQ", "URLExpand", "URLParse", "URLQueryDecode", \
"URLQueryEncode", "URLShorten", "ValidTypeQ", "ValueDimensions", \
"Values", "WhiteNoiseProcess", "XMLTemplate", "XYZColor", \
"ZoomLevel", "$CloudBase", "$CloudConnected", "$CloudDirectory", \
"$CloudEvaluation", "$CloudRootDirectory", "$EvaluationEnvironment", \
"$GeoLocationCity", "$GeoLocationCountry", "$GeoLocationPrecision", \
"$GeoLocationSource", "$RegisteredDeviceClasses", \
"$RequesterAddress", "$RequesterWolframID", "$RequesterWolframUUID", \
"$UserAgentLanguages", "$UserAgentMachine", "$UserAgentName", \
"$UserAgentOperatingSystem", "$UserAgentString", "$UserAgentVersion", \
"$WolframID", "$WolframUUID"}
There we have it, a preview of the list of functions that might be coming in desktop version 10 of Mathematica courtesy of the free Pi version.
No local documentation
On a desktop version of Mathematica, all of the Mathematica documentation is available on your local machine by clicking on Help->Documentation Center in the Mathematica notebook interface. On the pi version, it seems that there is no local documentation, presumably to keep the installation size down. You get to the documentation via the notebook interface by clicking on Help->OnlineDocumentation which takes you to http://reference.wolfram.com/language/?src=raspi
Speed vs my laptop
I am used to running Mathematica on high specification machines and so naturally the pi version felt very sluggish–particularly when using the notebook interface. With that said, however, I found it very usable for general playing around. I was very curious, however, about the speed of the pi version compared to the version on my home laptop and so created a small benchmark notebook that did three things:
- Calculate pi to 1,000,000 decimal places.
- Multiply two 1000 x 1000 random matrices together
- Integrate sin(x)^2*tan(x) with respect to x
The comparison is going to be against my Windows 7 laptop which has a quad-core Intel Core i7-2630QM. The procedure I followed was:
- Start a fresh version of the Mathematica notebook and open pi_bench.nb
- Click on Evaluation->Evaluate Notebook and record the times
- Click on Evaluation->Evaluate Notebook again and record the new times.
Note that I use the AbsoluteTiming function instead of Timing (detailed reason given here) and I clear the system cache (detailed resason given here). You can download the notebook I used here. Alternatively, copy and paste the code below
(*Clear Cache*)
ClearSystemCache[]
(*Calculate pi to 1 million decimal places and store the result*)
AbsoluteTiming[pi = N[Pi, 1000000];]
(*Multiply two random 1000x1000 matrices together and store the \
result*)
a = RandomReal[1, {1000, 1000}];
b = RandomReal[1, {1000, 1000}];
AbsoluteTiming[prod = Dot[a, b];]
(*calculate an integral and store the result*)
AbsoluteTiming[res = Integrate[Sin[x]^2*Tan[x], x];]
Here are the results. All timings in seconds.
| Test | Laptop Run 1 | Laptop Run 2 | RaspPi Run 1 | RaspPi Run 2 | Best Pi/Best Laptop |
| Million digits of Pi | 0.994057 | 1.007058 | 14.101360 | 13.860549 | 13.9434 |
| Matrix product | 0.108006 | 0.074004 | 85.076986 | 85.526180 | 1149.63 |
| Symbolic integral | 0.035002 | 0.008000 | 0.980086 | 0.448804 | 56.1 |
From these tests, we see that Mathematica on the pi is around 14 to 1149 times slower on the pi than my laptop. The huge difference between the pi and laptop for the matrix product stems from the fact that ,on the laptop, Mathematica is using Intels Math Kernel Library (MKL). The MKL is extremely well optimised for Intel processors and will be using all 4 of the laptop’s CPU cores along with extra tricks such as AVX operations etc. I am not sure what is being used on the pi for this operation.
I also ran the standard BenchMarkReport[] on the Raspberry Pi. The results are available here.
Speed vs Python
Comparing Mathematica on the pi to Mathematica on my laptop might have been a fun exercise for me but it’s not really fair on the pi which wasn’t designed to perform against expensive laptops. So, let’s move on to a more meaningful speed comparison: Mathematica on pi versus Python on pi.
When it comes to benchmarking on Python, I usually turn to the timeit module. This time, however, I’m not going to use it and that’s because of something odd that’s happening with sympy and caching. I’m using sympy to calculate pi to 1 million places and for the symbolic calculus. Check out this ipython session on the pi
pi@raspberrypi ~ $ SYMPY_USE_CACHE=no pi@raspberrypi ~ $ ipython Python 2.7.3 (default, Jan 13 2013, 11:20:46) Type "copyright", "credits" or "license" for more information. IPython 0.13.1 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: import sympy In [2]: pi=sympy.pi.evalf(100000) #Takes a few seconds In [3]: %timeit pi=sympy.pi.evalf(100000) 100 loops, best of 3: 2.35 ms per loop
In short, I have asked sympy not to use caching (I think!) and yet it is caching the result. I don’t want to time how quickly sympy can get a result from the cache so I can’t use timeit until I figure out what’s going on here. Since I wanted to publish this post sooner rather than later I just did this:
import sympy
import time
import numpy
start = time.time()
pi=sympy.pi.evalf(1000000)
elapsed = (time.time() - start)
print('1 million pi digits: %f seconds' % elapsed)
a = numpy.random.uniform(0,1,(1000,1000))
b = numpy.random.uniform(0,1,(1000,1000))
start = time.time()
c=numpy.dot(a,b)
elapsed = (time.time() - start)
print('Matrix Multiply: %f seconds' % elapsed)
x=sympy.Symbol('x')
start = time.time()
res=sympy.integrate(sympy.sin(x)**2*sympy.tan(x),x)
elapsed = (time.time() - start)
print('Symbolic Integration: %f seconds' % elapsed)
Usually, I’d use time.clock() to measure things like this but something *very* strange is happening with time.clock() on my pi–something I’ll write up later. In short, it didn’t work properly and so I had to resort to time.time().
Here are the results:
1 million pi digits: 5535.621769 seconds Matrix Multiply: 77.938481 seconds Symbolic Integration: 1654.666123 seconds
The result that really surprised me here was the symbolic integration since the problem I posed didn’t look very difficult. Sympy on pi was thousands of times slower than Mathematica on pi for this calculation! On my laptop, the calculation times between Mathematica and sympy were about the same for this operation.
That Mathematica beats sympy for 1 million digits of pi doesn’t surprise me too much since I recall attending a seminar a few years ago where Wolfram Research described how they had optimized the living daylights out of that particular operation. Nice to see Python beating Mathematica by a little bit in the linear algebra though.