
Archive for the ‘Cloud Computing’ Category
At the time of writing, Microsoft Azure has 3 High Performance Computing instances available and I often find myself looking up their specifications and benchmark results when discussing their various methods with colleagues and clients. All the information is out there but seems to be spread across several documents. To save me the trouble in future, here is everything I usually need in one place
HC nodes: Original source of data
* CPU: Intel Skylake
* Cores: 44 (non-hyperthreaded)
* 3.5 TeraFLOPS double precision peak
* 352 Gigabyte RAM
* 700 Gigabyte local SSD storage
* 190 GB/s memory bandwidth
* 100 GB/s infiniband
HB Nodes: Original source of data
* CPU: AMD EPYC 7000 series (Naples)
* Cores: 60 (non-hyperthreaded)
* ???? Peak double precision peak
* 240 Gigabyte RAM
* 700 Gigabyte local SSD storage
* 263 GB/s memory bandwidth
* 100 GB/s infiniband
HBv2 nodes: Original source of data
* CPU: AMD EPYC 7002 series (Rome)
* Cores: 120 (non-hyperthreaded)
* 4 TeraFlops Peak double precision
* 480 Gigabyte RAM
* 1.6 Terabyte local SSD storage
* 350 GB/s memory bandwidth
* 200 GB/s infiniband
Azure HPC Benchmarks
When using the Azure Command Line Interface (CLI), it is often necessary to explicitly state which region you want to perform an operation in. For example, when creating a resource group
az group create --name <rg_name> --location <location>
Where you replace <location>with the region where you want to create the resource group. You may have a region in mind (South Central US perhaps) or you may be wondering which regions are available. Either way, it is helpful to see the list of all possible values for <location> in commands like the one above.
The way to do this is with the following command
az account list-locations
By default, the output is in JSON format:
[
{
"displayName": "East Asia",
"id": "/subscriptions/1ce68363-bb47-4365-b243-7451a25611c4/locations/eastasia",
"latitude": "22.267",
"longitude": "114.188",
"name": "eastasia",
"subscriptionId": null
},
{
"displayName": "Southeast Asia",
"id": "/subscriptions/1ce68363-bb47-4365-b243-7451a25611c4/locations/southeastasia",
"latitude": "1.283",
"longitude": "103.833",
"name": "southeastasia",
"subscriptionId": null
},
{
"displayName": "Central US",
"id": "/subscriptions/1ce68363-bb47-4365-b243-7451a25611c4/locations/centralus",
"latitude": "41.5908",
"longitude": "-93.6208",
"name": "centralus",
"subscriptionId": null
Let’s get the output in a more human readable table format.
az account list-locations -o table
DisplayName Latitude Longitude Name
-------------------- ---------- ----------- ------------------
East Asia 22.267 114.188 eastasia
Southeast Asia 1.283 103.833 southeastasia
Central US 41.5908 -93.6208 centralus
East US 37.3719 -79.8164 eastus
East US 2 36.6681 -78.3889 eastus2
West US 37.783 -122.417 westus
North Central US 41.8819 -87.6278 northcentralus
South Central US 29.4167 -98.5 southcentralus
North Europe 53.3478 -6.2597 northeurope
West Europe 52.3667 4.9 westeurope
Japan West 34.6939 135.5022 japanwest
Japan East 35.68 139.77 japaneast
Brazil South -23.55 -46.633 brazilsouth
Australia East -33.86 151.2094 australiaeast
Australia Southeast -37.8136 144.9631 australiasoutheast
South India 12.9822 80.1636 southindia
Central India 18.5822 73.9197 centralindia
West India 19.088 72.868 westindia
Canada Central 43.653 -79.383 canadacentral
Canada East 46.817 -71.217 canadaeast
UK South 50.941 -0.799 uksouth
UK West 53.427 -3.084 ukwest
West Central US 40.890 -110.234 westcentralus
West US 2 47.233 -119.852 westus2
Korea Central 37.5665 126.9780 koreacentral
Korea South 35.1796 129.0756 koreasouth
France Central 46.3772 2.3730 francecentral
France South 43.8345 2.1972 francesouth
Australia Central -35.3075 149.1244 australiacentral
Australia Central 2 -35.3075 149.1244 australiacentral2
UAE Central 24.466667 54.366669 uaecentral
UAE North 25.266666 55.316666 uaenorth
South Africa North -25.731340 28.218370 southafricanorth
South Africa West -34.075691 18.843266 southafricawest
Switzerland North 47.451542 8.564572 switzerlandnorth
Switzerland West 46.204391 6.143158 switzerlandwest
Germany North 53.073635 8.806422 germanynorth
Germany West Central 50.110924 8.682127 germanywestcentral
Norway West 58.969975 5.733107 norwaywest
Norway East 59.913868 10.752245 norwayeast
The entries in the Name column are valid options for <location> in the command we started out with.
HPC! To cloud or not to cloud….
Over the course of my career I have been involved with the provision of High Performance Computing (HPC) at almost every level. As a researcher and research software engineer I have been, and continue to be, a user of many large scale systems. As a member of research computing support, I was involved in service development and delivery, user-support, system administration and HPC training. Finally, as a member of senior leadership teams, I have been involved in the financial planning and strategic development of institution-wide HPC services.
In recent years, the question that pops up at every level of involvement with HPC is ‘Should we do this with our own equipment or should we do this in the cloud?’
This is an extremely complex, multi-dimensional question where the parameters are constantly shifting. The short, answer is always ‘well…it depends’ and it always does ‘depend’…on many things! What do you want to do? What is the state of the software that you have available? How much money do you have? How much time do you have? What support do you have? What equipment do you currently have and who else are you working with and so on.
Today, I want to focus on just one of these factors. Cost. I’m not saying that cost is necessarily the most important consideration in making HPC-related decisions but given that most of us have fixed budgets, it is impossible to ignore.
The value of independence
I have been involved in many discussions of HPC costs over the years and have seen several attempts at making the cloud vs on-premise cost-comparison. Such attempts are often biased in one direction or the other. It’s difficult not to be when you have a vested interest in the outcome.
When I chose to leave academia and join industry, I decided to work with the Numerical Algorithms Group (NAG), a research computing company that has been in business for almost 50 years. One reason for choosing them was their values which strongly resonate with my own. Another was their independence. NAG are a not-for-profit (yet commercial!) company who literally cannot be bought. They solve the independence problem by collaborating with pretty much everybody in the industry.
So, NAG are more interested in helping clients solve their technical computing problems than they are in driving them to any given solution. Cloud or on-premise? They don’t mind…they just want to help you make the decision.
Explore HPC cost models yourself
NAG’s VP for HPC services and consulting, Andrew Jones (@hpcnotes), has been teaching seminars on Total Cost Of Ownership models for several years at events like the SC Supercomputing conference series. To support these tutorials, Andrew created a simple, generic TCO model spreadsheet to illustrate the concepts and to show how even a simple TCO model can guide decisions.
Many people asked if NAG could send them the TCO spreadsheet from the tutorial but they decided to go one better and converted it into a web-form where you can start exploring some of the concepts yourself.
- Here’s the HPC Total Cost of Ownership calculator for you to play with: https://www.nag.com/content/hpc-tco-calculator
I also made a video about it.
If you want more, get in touch with either me (@walkingrandomly) or Andrew (@hpcnotes) on twitter or email hpc@nag.com. We’ll also be teaching this type of thing at ISC 2019 so please do join us there too.
I’m working on some MATLAB code at the moment that I’ve managed to reduce down to a bunch of implicitly parallel functions. This is nice because the data that we’ll eventually throw at it will be represented as a lot of huge matrices. As such, I’m expecting that if we throw a lot of cores at it, we’ll get a lot of speed-up. Preliminary testing on local HPC nodes shows that I’m probably right.
During testing and profiling on a smaller data set I thought that it would be fun to run the code on the most powerful single node I can lay my hands on. In my case that’s an Azure F72s_v2 which I currently get for free thanks to a Microsoft Azure for Research grant I won.
These Azure F72s_v2 machines are NICE! Running Intel Xeon Platinum 8168 CPUs with 72 virtual cores and 144GB of RAM, they put my Macbook Pro to shame! Theoretically, they should be more powerful than any of the nodes I can access on my University HPC system.
So, you can imagine my surprise when the production code ran almost 3 times slower than on my Macbook Pro!
Here’s a Microbenchmark, extracted from the production code, running on MATLAB 2017b on a few machines to show the kind of slowdown I experienced on these super powerful virtual machines.
test_t = rand(8755,1);
test_c = rand(5799,1);
tic;test_res = bsxfun(@times,test_t,test_c');toc
tic;test_res = bsxfun(@times,test_t,test_c');toc
I ran the bsxfun twice and report the fastest since the first call to any function in MATLAB is often slower than subsequent ones for various reasons. This quick and dirty benchmark isn’t exactly rigorous but its good enough to show the issue.
- Azure F72s_v2 (72 vcpus, 144 GB memory) running Windows Server 2016: 0.3 seconds
- Azure F32s_v2 (32 vcpus, 64 GB memory) running Windows Server 2016: 0.29 seconds
- 2014 Macbook Pro running OS X: 0.11 seconds
- Dell XPS 15 9560 laptop running Windows 10: 0.11 seconds
- 8 cores on a node of Sheffield University’s Linux HPC cluster: 0.03 seconds
- 16 cores on a node of Sheffield University’s Linux HPC cluster: 0.015 seconds
After a conversation on twitter, I ran it on Azure twice — once on a 72 vCPU instance and once on a 32 vCPU instance. This was to test if the issue was related to having 2 physical CPUs. The results were pretty much identical.
The results from the University HPC cluster are more in line with what I expected to see — faster than a laptop and good scaling with respect to number of cores. I tried running it on 32 cores but the benchmark is still in the queue ;)
What’s going on?
I have no idea! I’m stumped to be honest. Here are some thoughts that occur to me in no particular order
- Maybe it’s an issue with Windows Server 2016. Is there some environment variable I should have set or security option I could have changed? Maybe the Windows version of MATLAB doesn’t get on well with large core counts? I can only test up to 4 on my own hardware and that’s using Windows 10 rather than Windows server. I need to repeat the experiment using a Linux guest OS.
- Is it an issue related to the fact that there isn’t a 1:1 mapping between physical hardware and virtual cores? Intel Xeon Platinum 8168 CPUs have 24 cores giving 48 hyperthreads so two of them would give me 48 cores and 96 hyperthreads. They appear to the virtualised OS as 2 x 18 core CPUs with 72 hyperthreads in total. Does this matter in any way?
In a previous blog post, I told the story of how I used Amazon AWS and AlcesFlight to create a temporary multi-user HPC cluster for use in a training course. Here are the details of how I actually did it.
Note that I have only ever used this configuration as a training cluster. I am not suggesting that the customisations are suitable for real work.
Before you start
Before attempting to use AlcesFlight on AWS, I suggest that you ensure that you have the following things working
- A working AWS account. Ensure that you can create an EC2 virtual machine and connect to it via ssh.
- Get the AWS Command Line Interface working.
Customizing the HPC cluster on AWS
AlcesFlight provides a CloudFormation template for launching cluster instances on Amazon AWS. The practical upshot of this is that you answer a bunch of questions on a web form to customise your cluster and then you launch it.
We are going to use this CloudFormation template along with some bash scripts that provide additional customisation.
Get the customisation scripts
The first step is to get some customization scripts in an S3 bucket. You could use your own or you could use the ones I created.
If you use mine, make sure you take a good look at them first to make sure you are happy with what I’ve done! It’s probably worth using your own fork of my repo so you can customise your cluster further.
It’s the bash scripts that allow the creation of a bunch of user accounts for trainees with randomized passwords. My scripts do some other things too and I’ve listed everything in the github README.md.
git clone https://github.com/mikecroucher/alces_flight_customisation
cd alces_flight_customisation
Now you need to upload these to an s3 bucket. I called mine walkingrandomly-aws-cluster
aws s3api create-bucket --bucket walkingrandomly-aws-cluster --region eu-west-2 --create-bucket-configuration LocationConstraint=eu-west-2
aws s3 sync . s3://walkingrandomly-aws-cluster --delete
Set up the CloudFormation template
- Head over to Alces Flight Solo (Community Edition) and click on continue to subscribe
- Choose the region you want to create the cluster in, select Personal HPC compute cluster and click on Launch with CloudFormationConsole

- Go through the CloudFormation template screens, creating the cluster as you want it until you get to the S3 bubcket for customization profiles box where you fill in the name of the S3 bucket you created earlier.
- Enable the default profile
- Continue answering the questions asked by the web form. For this simple training cluster, I just accepted all of the defaults and it worked fine
When the CloudFormation stack has been fully created, you can log into your new cluster as an administrator. To get the connection details of the headnode, go to the EC2 management console in your web-browser, select the headnode and click on Connect.
When you log in to the cluster as administrator, the usernames and passwords for your training cohort will be in directory specified by the password_file variable in the configure.d/run_me.sh script. I set my administrator account to be called walkingrandomly and so put the password file in /home/walkingrandomly/users.txt. I could then print this out and distribute the usernames and passwords to each training delegate.
This is probably not great sysadmin practice but worked on the day. If anyone can come up with a better way, Pull Requests are welcomed!

Try a training account
At this point, I suggest that you try logging in as one of the training user accounts and make sure you can successfully submit a job. When I first tried all of this, the default scheduler on the created cluster was SunGridEngine and my first attempt at customisation left me with user accounts that couldn’t submit jobs.
The current scripts have been battle tested with Sun Grid Engine, including MPI job submission and I’ve also done a very basic test with Slurm. However, you really should check that a user account can submit all of the types of job you expect to use in class.
Troubleshooting
When I first tried to do this, things didn’t go completely smoothly. Here are some things I learned to help diagnose the problems
Full documentation is available at http://docs.alces-flight.com/en/stable/customisation/customisation.html
On the cluster, we can see where its looking for its customisation scripts with the alces about command
alces about customizer
Customizer bucket prefix: s3://walkingrandomly-aws-cluster/customizer
The log file at /var/log/clusterware/instance.log on both the head node and worker nodes is very useful.
Once, I did all of this using a Windows CMD bash prompt and the customisation scripts failed to run. The logs showed this error
/bin/bash^M: bad interpreter: No such file or directory
This is a classic dos2unix error and could be avoided, for example, by using the Windows Subsystem for linux instead of CMD.exe.
I needed a supercomputer…..quickly!
One of the things that we do in Sheffield’s Research Software Engineering Group is host training courses delivered by external providers. One such course is on parallel programming using MPI for which we turn to the experts at NAG (Numerical Algorithms Group). A few days before turning up to deliver the course, the trainer got in touch with me to ask for details about our HPC cluster.
Because Croucher’s law, I had forgotten to let our HPC sysadmin know that I’d need a bunch of training accounts and around 128 cores set-aside for us to play around with for a couple of days.
In other words, I was hosting a supercomputing course and had forgotten the supercomputer.
Building a HPC cluster in the cloud
AlcesFlight is a relatively new product that allows you to spin up a traditional-looking High Performance Computing cluster on cloud computing substrates such as Microsoft Azure or Amazon AWS. You get a head node, a bunch of worker nodes and a job scheduler such as Slurm or Sun Grid Engine. It looks just the systems that The University of Sheffield provides for its researchers!
You also get lots of nice features such as the ability to scale the number of worker nodes according to demand, a metric ton of available applications and the ability to customise the cluster at start up.
The supercomputing budget was less than the coffee budget
…and I only bought coffee for myself and the two trainers over the two days! The attendees had to buy their own (In my defence…the course was free for attendees!).
I used the following
- A head node of: t2.large (2 vCPUs, 8Gb RAM)
- Initial worker nodes: 4 of c4.4xlarge (16 vCPUs and 30GB RAM each)
- Maximum worker nodes: 8 of c4.4xlarge (16 vCPUs and 30GB RAM each)
This gave me a cluster with between 64 and 128 virtual cores depending on the amount that the class were using it. Much of the time, only 4 nodes were up and running – the others spun up automatically when the class needed them and vanished when they hadn’t been used for a while.
I was using the EU (Ireland) region and the prices at the time were
- Head node: On demand pricing of $0.101 per hour
- Worker nodes: $0.24 (ish) using spot pricing. Each one about twice as powerful as a 2014 Macbook Pro according to this benchmark.
HPC cost: As such, the maximum cost of this cluster was $2.73 per hour when all nodes were up and running. The class ran from 10am to 5pm for two days so we needed it for 14 hours. Maximum cost would have been $38.22.
Coffee cost: 2 instructors and me needed coffee twice a day. So that’s 12 coffees in total. Around £2.50 or $3.37 per coffee so $40.44
The HPC cost was probably less than that since we didn’t use 128 cores all the time and the coffee probably cost a little more.
Setting up the cluster
Technical details of how I configured the cluster can be found in the follow up post at https://www.walkingrandomly.com/?p=6431
The Meltdown bug which affects most modern CPUs has been called by some ‘The worst ever CPU bug’. Accessible explanations about what the Meltdown bug actually is are available here and here.
Software patches have been made available but some people have estimated a performance hit of up to 30% in some cases. Some of us in the High Performance Computing (HPC) community (See here for the initial twitter conversation) started to wonder what this might mean for the type of workloads that run on our systems. After all, if the worst case scenario of 30% is the norm, it will drastically affect the power of our systems and hence reduce the amount of science we are able to support.
In the video below, Professor Mark Handley from University College London gives a detailed explanation of both Meltdown and Spectre at an event held at Alan Turing Institute in London.
Another video that gives a great introduction to this topic was given by Jon Masters at https://fosdem.org/2018/schedule/event/closing_keynote/
To patch or not to patch
To a first approximation, a patch causing a 30% performance hit on a system costing £1 million pounds is going to cost an equivalent of £300,000 — not exactly small change! This has led to some people wondering if we should patch HPC systems at all:
Given the size of the performance hit should we even *be* patching for this? Unless you need trusted computing, does it really matter for the average HPC?
— Phil Tooley (@acceleratedsci) January 5, 2018
All of the UK Tier-3 HPC centres I’m aware of have applied the patches (Sheffield, Leeds and Manchester) but I’d be interested to learn of centres that decided not to. Feel free to comment here or message me on twitter if you have something to add to this discussion and I’ll update this post where appropriate.
Research paper discussing the performance penalties of these patches on HPC workloads
A group of people have written a paper on Arxiv that looks at HPC performance penalties in more detail. From the paper’s abstract:
The results show that although some specific functions can have execution times decreased by as much as 74%, the majority of individual metrics indicates little to no decrease in performance. The real-world applications show a 2-3% decrease in performance for single node jobs and a 5-11% decrease for parallel multi node jobs.
Other relevant results and benchmarks
Here are a few other links that discuss the performance penalty of applying the Meltdown patch.
- Redhat’s experiments showing worst-case performance drops of 19% in certain benchmarks.
- Wikipedia article showing a summary of various benchmarks.
Acknowledgements
Thanks to Adrian Jackson, Phil Tooley, Filippo Spiga and members of the UK HPC-SIG for useful discussions.
The RCUK Cloud Working Group are hosting their 3rd free annual workshop in January 2018 and I’ll be attending. At the time of writing, there are still places left and you can sign up at https://www.eventbrite.co.uk/e/research-councils-uk-cloud-workshop-tickets-39439492584
From the event advertisement:
For a while now, Microsoft have provided a free Jupyter Notebook service on Microsoft Azure. At the moment they provide compute kernels for Python, R and F# providing up to 4Gb of memory per session. Anyone with a Microsoft account can upload their own notebooks, share notebooks with others and start computing or doing data science for free.
They University of Cambridge uses them for teaching, and they’ve also been used by the LIGO people (gravitational waves) for dissemination purposes.
This got me wondering. How much power does Microsoft provide for free within these notebooks? Computing is pretty cheap these days what with the Raspberry Pi and so on but what do you get for nothing? The memory limit is 4GB but how about the computational power?
To find out, I created a simple benchmark notebook that finds out how quickly a computer multiplies matrices together of various sizes.
- The benchmark notebook is here on Azure https://notebooks.azure.com/walkingrandomly/libraries/MatrixMatrix
- and here on GitHub https://github.com/mikecroucher/Jupyter-Matrix-Matrix
Matrix-Matrix multiplication is often used as a benchmark because it’s a common operation in many scientific domains and it has been optimised to within an inch of it’s life. I have lost count of the number of times where my contribution to a researcher’s computational workflow has amounted to little more than ‘don’t multiply matrices together like that, do it like this…it’s much faster’
So how do Azure notebooks perform when doing this important operation? It turns out that they max out at 263 Gigaflops! 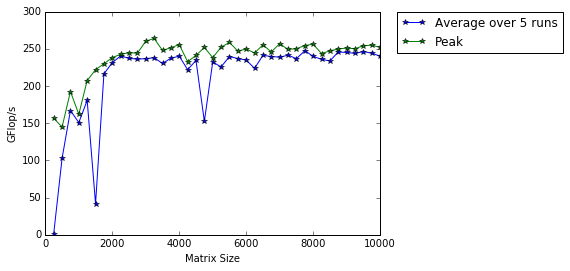
For context, here are some other results:
- A 16 core Intel Xeon E5-2630 v3 node running on Sheffield’s HPC system achieved around 500 Gigaflops.
- My mid-2014 Mabook Pro, with a Haswell Intel CPU hit, hit 169 Gigaflops.
- My Dell XPS9560 laptop, with a Kaby Lake Intel CPU, manages 153 Gigaflops.
As you can see, we are getting quite a lot of compute power for nothing from Azure Notebooks. Of course, one of the limiting factors of the free notebook service is that we are limited to 4GB of RAM but that was more than I had on my own laptops until 2011 and I got along just fine.
Another fun fact is that according to https://www.top500.org/statistics/perfdevel/, 263 Gigaflops would have made it the fastest computer in the world until 1994. It would have stayed in the top 500 supercomputers of the world until June 2003 [1].
Not bad for free!
[1] The top 500 list is compiled using a different benchmark called LINPACK so a direct comparison isn’t strictly valid…I’m using a little poetic license here.