
Archive for April, 2011
Last month I published an article that included an interactive mathematical demonstration powered by Wolfram’s new CDF (Computable Document Format) player. These demonstrations work on many modern web-browsers including Internet Explorer 8 and Firefox 3.6. So, how do you go about adding them to your own websites?
What you need
- Mathematica 8.0.1 or above to create demonstrations. Viewers of your demonstration only need the free CDF player for their platform.
- A modern browser such as Internet Explorer 8, Firefox 3.6 or Safari 5.
- Basic knowledge of HTML, uploading files to a webserver etc. If you maintain a blog or similar then you almost certainly know enough
Our aim is the following, very simple, interactive demonstration.
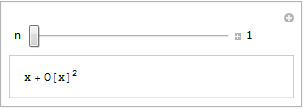
If all you see is a static image then you do not have the CDF player or Mathematica 8 correctly installed. Alternatively, you are using an unsupported platform such as Linux, iOS or Android.
Step 1 – Create the .cdf file
Fire up Mathematica, type in and evaluate the following code. You should get an applet similar to the one above.
Manipulate[
Series[Sin[x], {x, 0, n}]
, {n, 1, 10, 1, Appearance -> "Labeled"}
]
Save it as a .cdf file called series.cdf by clicking on File->Save as — Give it the File Name series.cdf and change the Save as Type to Computable Document (*.cdf)

Step 2 – Get a static screenshot
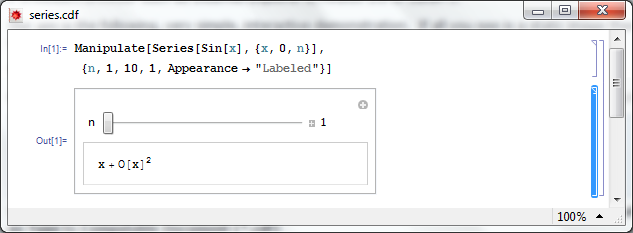
Not everyone is going to have either Mathematica 8 or the free CDF player installed when they visit your website so we need to give them something to look at. So, lets give them a static image of the Manipulate applet. As a bonus, this will act as a place holder for the interactive version for those who do have the requisite software.
Open series.cdf in Mathematica and left click on the bracket surrounding the manipulate (see below). Click on Cell->Convert To->Bitmap. Then click on File->Save Selection As . Make sure you change .pdf to something more sensible such as .png
Don’t save your .cdf file at this point or it won’t be interactive. Re-evaluate the code again to get back your interactive Manipulate.
Here’s one I made earlier – series.png
Step 4 – Hide the source code
In this particular instance, I don’t want the user to see the source code. So, lets sort that out.
- Open series.cdf in Mathematica if you haven’t already and make sure that the Manipulate is evaluated.
- Left click on the inner cell bracket surrounding the Manipulate source code only and click on Cell->Cell Properties and un-tick Open
Step 5 – Hide the cell brackets
Those blue brackets at the far right of the Mathematica notebook are called the Cell brackets and I don’t want to see them on my web site as they make the applet look messy.
- Open series.cdf in Mathematica if you haven’t already
- Open the option inspector: Edit->Preferences->Advanced->Open Option Inspector
- Ensure Show option values is set to “series.cdf” and that they are sorted by category. Click on Apply.
- Click on Cell Options-> Display options and in the right hand pane set ShowCellBracket to False
- Click Apply
Before you save series.cdf ensure that the applet is interactive and not a static bitmap. If it isn’t interactive then click on Evaluation->Evaluate notebook to re-evaluate the (now hidden) source code. Also ensure that there is nothing but the applet anywhere else in the notebook.
Step 6 – Get interactive on your website
Upload series.png and series.cdf to your server. The next thing we need to do is get the static image into our webpage. Here’s what the HTML might look like
<img id="Series_applet" src="series.png" alt="Series demo" />
Obviously, you’ll need to put the full path to series.png on your server in this piece of code. The only thing that is different to the way you might usually use the img tag is that it includes an id; in this case it is Series_applet. We’ll make use of this later.
The magic happens thanks to a small javascript applet called the CDF javascript plugin. Version one is at http://www.wolfram.com/cdf-player/plugin/v1.0/cdfplugin.js and that’s the one I’ll be using here. Here’s the code which needs to be placed before the img tag in your HTML file.
<script src="http://www.wolfram.com/cdf-player/plugin/v1.0/cdfplugin.js"
type="text/javascript"></script><script type="text/javascript">// <![CDATA[
var cdf = new cdf_plugin();
cdf.addCDFObject("Series_applet", "series.cdf", 403,109);
// ]]></script>
The only line you’ll need to change if you use this for anything else is
cdf.addCDFObject("Series_applet", "series.cdf", 403,109);
where Series_applet is the id of the image we wish to replace and series.cdf is the cdf file we want to replace it with. The numbers 403,109 are the dimensions of the applet. These will not be the same as the .png file as the dimensions of the .cdf file are slightly larger. I used trial and error to determine what they should be as I haven’t come up with a better way yet (suggestions welcomed).
So that’s it for now. Hope this mini-tutorial was useful. Let me know if you upload any demonstrations to your own website or if you have any comments, questions or problems.
Update (6th June 2011)
Thanks to ‘Paul’ in the comments section, I have discovered that this mechanism won’t work for .cdf files that Wolfram deem are unsafe. According to Paul the definition of unsafe is as follows:
Dynamic content is considered unsafe if it:
- uses File operations
- uses interprocess communication via MathLink Mathematica Functions
- uses JLink or NETLink
- uses Low-Level Notebook Programming
- uses data as code by Converting between Expressions and Strings
- uses Namespace Management
- uses Options Management
- uses External Programs
I love mathematics and I also love gadgets so you’d think that I’d be overjoyed to learn that there are a couple of new graphical calculators on the block. You’d be wrong!
Late last year, Casio released the Prizm colour graphical calculator. It costs $130 and its spec is pitiful:
- 216*384 pixel display with 65,536 colours
- 16Mb memory
- The CPU is a SuperH 3 running at 58Mhz (according to this site)

More recently, Texas Instruments countered with its color offering, the TI-NSpire CX CAS. This one costs $162 (source) and its specs are also a bit on the weak side but quite a bit higher than the Casio.
- 320*240 pixels with 65,536 colours
- 100Mb memory
- CPU? I have no idea. Can anyone help?
If you are into retro-computing then those specs might appeal to you but they leave me cold. They are slow with limited memory and the ‘high-resolution’ display is no such thing. For $100 dollars more than the NSpire CX CAS I could buy a netbook and fill it with cutting edge mathematical software such as Octave, Scilab, SAGE and so on. I could also use it for web browsing,email and a thousand other things.
I (and many students) also have mobile phones with hardware that leave these calculators in the dust. Combined with software such as Spacetime or online services such as Wolfram Alpha, a mobile phone is infinitely more capable than these top of the line graphical calculators.
They also only ever seem to be used in schools and colleges. I spend a lot of time working with engineers, scientists and mathematicians and I hardly ever see a calculator such as the Casio Prizm or TI NSpire on their desks. They tend to have simple calculators for everyday use and will turn to a computer for anything more complicated such as plotting a graph or solving equations.
One argument I hear for using these calculators is ‘They are limited enough to use in exams.‘ Sounds sensible but then I get to thinking ‘Why are we teaching a generation of students to use crippled technology?‘ Why not go the whole hog and ban ALL technology in exams? Alternatively, supply locked down computers for exams that limit the software used by students. Surely we need experts in useful technology, not crippled technology?
So, I don’t get it. Why do so many people advocate the use of these calculators? They seem pointless! Am I missing something? Comments welcomed.
Update 1: I’ve been slashdotted! Check out the slashdot article for more comments.
Update 2: My favourite web-comic, xkcd, covered this subject a while ago.
Other posts you may find useful / interesting
Welcome to the very late 76th carnival of Maths. As per tradition, lets start with the trivia. 76 is an automorphic number , can be written as a sum of three squares (2^2+6^2+6^2) and is the 9th Lucas number.

Every now and then I get asked the question ‘Eigenvectors….so what are they good for?’ I’ve got a few stock answers but Language Log’s Mark Liberman goes the extra mile when he considers how they might have been used in Cinderella and goes on to discuss how they are used in linguistics. Are you suitably intrigued? Check it out in Eigenfeet, eigenfaces, eigenlinguistics, …
If you have worked on the classification of multivariate data then you may well have heard of or used the Mahalanobis distance (I came across it for the first time when working with MATLAB’s pdist function). It turns out that this commonly used metric has rather surprising origins! Read all about it in Anthropometry and Anglo-Indians over at Jost a Mon.
March 14th is, of course, Pi day and several bloggers have written something about everyone’s favouburite irrational number. Carnival regular, John D. Cook, brings us A Ramanujan series for calculating pi, 360 has The Difference and Qiaochu Yuan counters with Pi is still wrong. Finally, madkane brings us a Pi day limerick.
Over at God Plays Dice, Michael Lugo brings us A street-fighting approach to the variance of a hypergeometric random variable and some of Denise’s favourite math websites have gone AWOL over at Let’s Play Math. Can you help her find them?
Peter Rowlett asked Twitter for links to enthuse people about mathematics. Here are the answers. Finally, Guillermo Bautista gives us an example of the epsilon-delta definition of limits.
Your Carnival needs you
The Carnival of Math desperately needs people to write and host future editions. If you have a math related blog and would like a bucket-load of extra traffic then contact me for more information.
A couple of weeks ago my friend and colleague, Ian Cottam, wrote a guest post here at Walking Randomly about his work on interfacing Dropbox with the high throughput computing software, Condor. Ian’s post was very well received and so he’s back; this time writing about a very different kind of project. Over to Ian.
Natural Scientists: their very big output files – and a tale of diffs by Ian Cottam
I’ve noticed that natural scientists (as opposed to computer scientists) often write, or use, programs that produce masses of output, usually just numbers. It might be the final results file or, often, some intermediate test results.
Am I being a little cynical in thinking that many users glance – ok, carefully check – a few of these thousands (millions?) of numbers and then delete the file? Let’s assume such files are really needed. A little automation is often added to the process by having a baseline file and running a program to show you the differences between it and your latest output (assuming wholesale changes are not the norm).
One of the popular difference programs is the Unix diff command . (I’ve been using it since the 1970s.) It popularised the idea of showing minimal differences between two text files (and, later, binary ones too). There are actually a few algorithms for doing minimal difference computation, and GNU diff, for example, uses a different one from the original Bell Labs version. They all have one thing in common: to achieve minimal difference computation the two files being compared must be read into main memory (aka RAM). Back in the 1970s, and on my then department’s PDP-11/40, this restricted the size of the files considerably; not that we noticed much as everything was 16bit and “small was beautiful”. GNU diff, on modern machines, can cope with very big files, but still chokes if your files, in aggregate, approach the gigabyte range.
(As a bit of an aside: a major contribution of all the GNU tools, over what we had been used to from the Unix pioneers at Bell Labs, was that they removed all arbitrary size restrictions; the most common and frustrating one being the length of text lines.)
Back to the 1970s again: Bell Labs did know that some files were too big to compare with diff , and they also shipped: diffh. The h stands for halfhearted. Diffh does not promise minimal differences, but can be very good for big files with occasional differences. It uses a pass over the files using a simple ‘sliding window’ heuristic approach (the other word that the h is sometimes said to stand for). You can still find an old version of diffh on the Internet. However, it ‘gives up’ rather easily and you may have to spend some time modifying it for, e.g., 64 bit ints and pointers, as well as for compiling with modern C compilers. Other tools exist that can compare enormous files, but they don’t produce readable output in diff’s pleasant format.
A few years back, when a user at the University of Manchester asked for help with the ‘diff – files too big/ out of memory’ problem, I wrote a modern version that I called idiffh (for Ian’s diffh). My ground rules were:
- Work on any text files on any operating system with a C compiler
- Have no limits on, e.g., line lengths or file size
- Never ‘give up’ if the going gets tough (i.e. when the files are very different)
You won’t find this with the GNU collection as they like to write code to the Unix interface and I like to write to the C standard I/O interface (see the first bullet point above).
An interesting implementation detail is that it uses random access to the files directly, relying on the operating system’s cache of file blocks to make this tolerably efficient. Waiting a minute or two to compare gigabyte sized files is usually acceptable.
As the comments in the code say, you can get some improvements by conditional compilation on Unix systems and especially on BSD Systems (including Apple Macs), but you can compile it straight, without such, on Windows and other platforms.
If you would like to try idffh out you can download it here.