
Archive for August, 2016
I sometimes give a talk called Is Your Research Software correct (github repo, slide deck) where I attempt to give a (hopefully) entertaining overview of some of the basic issues in modern research software practice and what can be done to make the world a little better.
One section of this talk is a look at some case studies where software errors caused problems in research. Ideally, I try to concentrate on simple errors that led to profound scientific screw-ups. I want the audience to think ‘Damn! *I* could have made that mistake in my code‘.
Curating this talk has turned me into an interested collector of such stories. This is not an exercise in naming and shaming (after all, the odds are that its only a matter of time before I, or one of my collaborators, makes it into the list — why set myself up for a beating?). Instead, it is an exercise in observing the problems that other people have had and using them to enhance our own working practices.
Thus begins a new recurring WalkingRandomly feature.
Excel corrupts genetics data
Today’s entry comes courtesy of a recent paper by Mark Ziemann, Yotam Eren and Assam El-OstaEmail – ‘Gene name errors are widespread in the scientific literature‘ where they demonstrate that the supplementary data files for hundreds of papers in genetics have been corrupted by Microsoft Excel which has helpfully turned gene symbols into dates and floating point numbers.
The paper gives advice to reviewers on how to spot this particular error and the authors have also published the code used for the analysis. I’ve not run it myself so can only attest to its existence, not it’s accuracy.
I’ve not dealt with genetic data directly myself so ask you — what would you have used instead of Excel? (my gut tells me R or Python but I have no details to offer).
Do you have a story to contribute?
If you are interested in contributing a story where a software glitch caused problems in research, please contact me to discuss details.
Update (31st August 2016)
One of the authors of the paper, Mark Ziemann, has written a follow up of the Excel work on his blog: http://genomespot.blogspot.co.uk/2016/08/my-personal-thoughts-on-gene-name-errors.html
This is my rant on import *. There are many like it, but this one is mine.
I tend to work with scientists so I’ll use something from mathematics as my example. What is the result of executing the following line of Python code?
result = sqrt(-1)
Of course, you have no idea if you don’t know which module sqrt came from. Let’s look at a few possibilities. Perhaps you’ll get an exception:
In [1]: import math In [2]: math.sqrt(-1) --------------------------------------------------------------------------- ValueError Traceback (most recent call last) in () ----> 1 math.sqrt(-1) ValueError: math domain error
Or maybe you’ll just get a warning and a nan
In [3]: import numpy In [4]: numpy.sqrt(-1) /Users/walkingrandomly/anaconda/bin/ipython:1: RuntimeWarning: invalid value encountered in sqrt #!/bin/bash /Users/walkingrandomly/anaconda/bin/python.app Out[4]: nan
You might get an answer but the datatype of your answer could be all sorts of strange and wonderful stuff.
In [5]: import cmath In [6]: cmath.sqrt(-1) Out[6]: 1j In [7]: type(cmath.sqrt(-1)) Out[7]: complex In [8]: import scipy In [9]: scipy.sqrt(-1) Out[9]: 1j In [10]: type(scipy.sqrt(-1)) Out[10]: numpy.complex128 In [11]: import sympy In [12]: sympy.sqrt(-1) Out[12]: I In [13]: type(sympy.sqrt(-1)) Out[13]: sympy.core.numbers.ImaginaryUnit
Even the humble square root function behaves very differently when imported from different modules! There are probably other sqrt functions, with yet more behaviours that I’ve missed.
Sometimes, they seem to behave in very similar ways:-
In [16]: math.sqrt(2) Out[16]: 1.4142135623730951 In [17]: numpy.sqrt(2) Out[17]: 1.4142135623730951 In [18]: scipy.sqrt(2) Out[18]: 1.4142135623730951
Let’s invent some trivial code.
from scipy import sqrt
x = float(input('enter a number\n'))
y = sqrt(x)
# important things happen after here. Complex numbers are fine!
I can input -1 just fine. Then, someone comes along and decides that they need a function from math in the ‘important bit’. They use import *
from scipy import sqrt
from math import *
x = float(input('enter a number\n'))
y = sqrt(x)
# important things happen after here. Complex numbers are fine!
They test using inputs like 2 and 4 and everything works (we don’t have automated tests — we suck!). Of course it breaks for -1 now though. This is easy to diagnose when you’ve got a few lines of code but it causes a lot of grief when there’s hundreds…or, horror of horrors, if the ‘from math import *’ was done somewhere in the middle of the source file!
I’m sometimes accused of being obsessive and maybe I’m labouring the point a little but I see this stuff, in various guises, all the time!
So, yeah, don’t use import *.
Like many people, I was excited to learn about the new Linux subsystem in Windows announced by Microsoft earlier this year (See Bash on Windows: The scripting game just changed).
Along with others, I’ve been playing with it on the Windows Insider builds but now that the Windows Anniversary Update has been released, everyone can get in on the action.
Activating the Linux Subsystem in Windows
Once you’ve updated to the Anniversary Update of Windows, here’s what you need to do.
Open settings
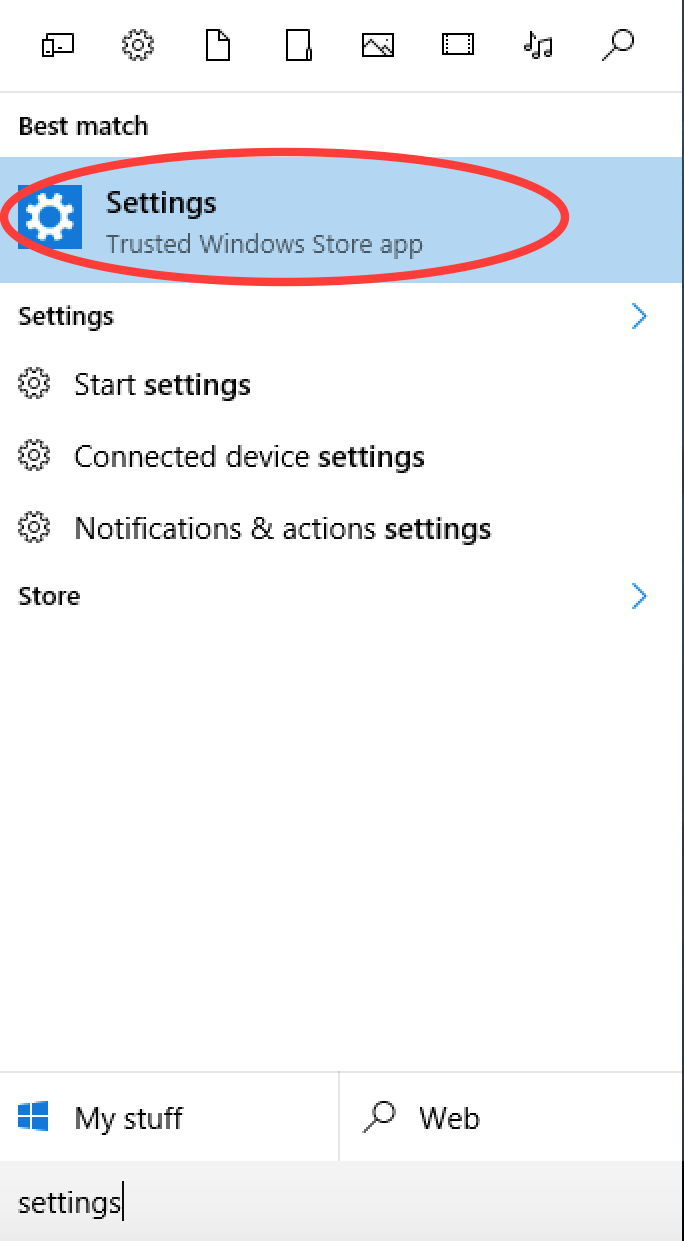
In settings, click on Update and Security
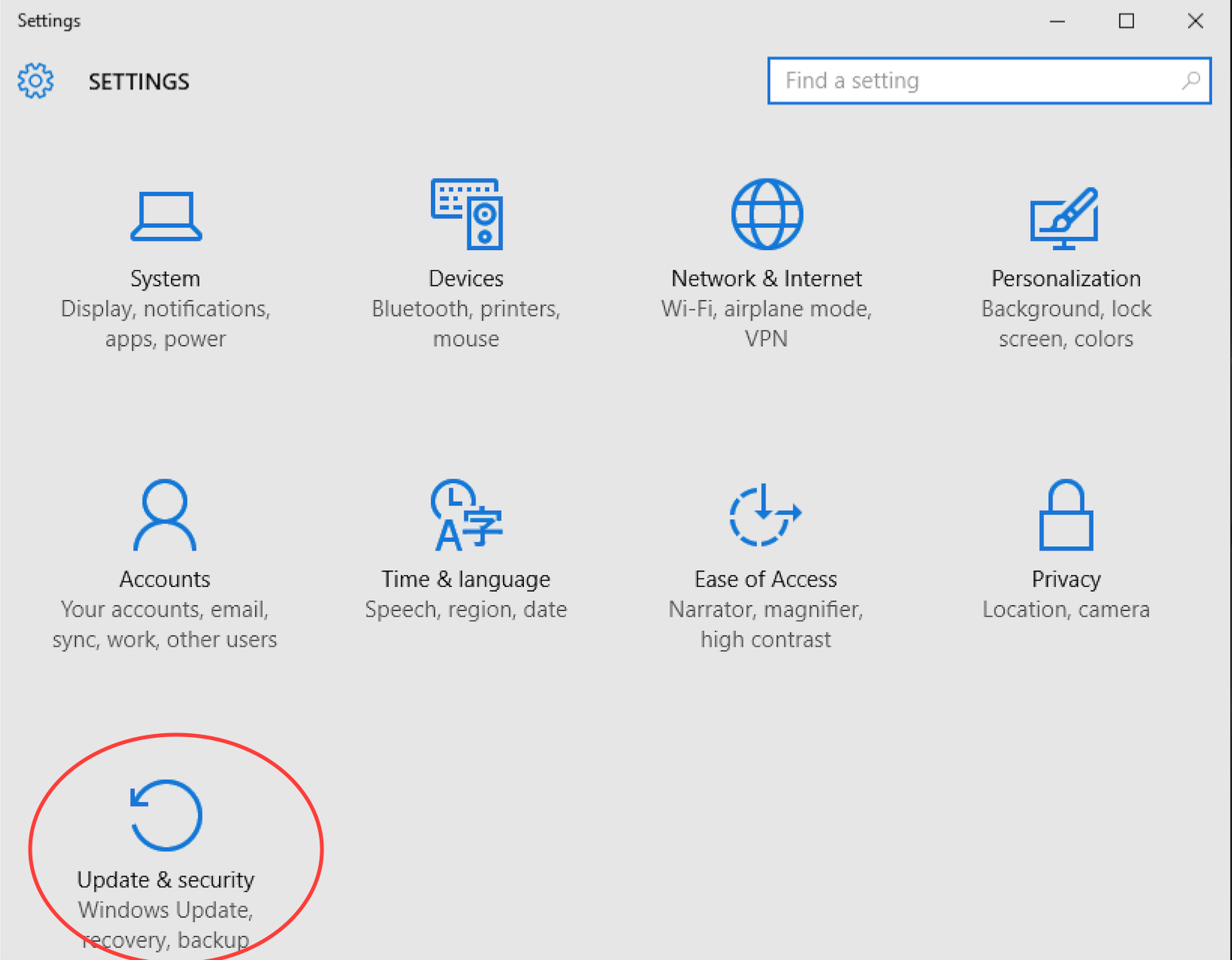
In Update and Security, click on For developers in the left hand pane. Then click on Developer mode.

Take note of the Use developer features warning and click Yes if you are happy. Developer mode gives you greater power, and with great power comes great responsibility.

Reboot the machine (may not be necessary here but it’s what I did).
Search for Features and click on Turn Windows features on or off
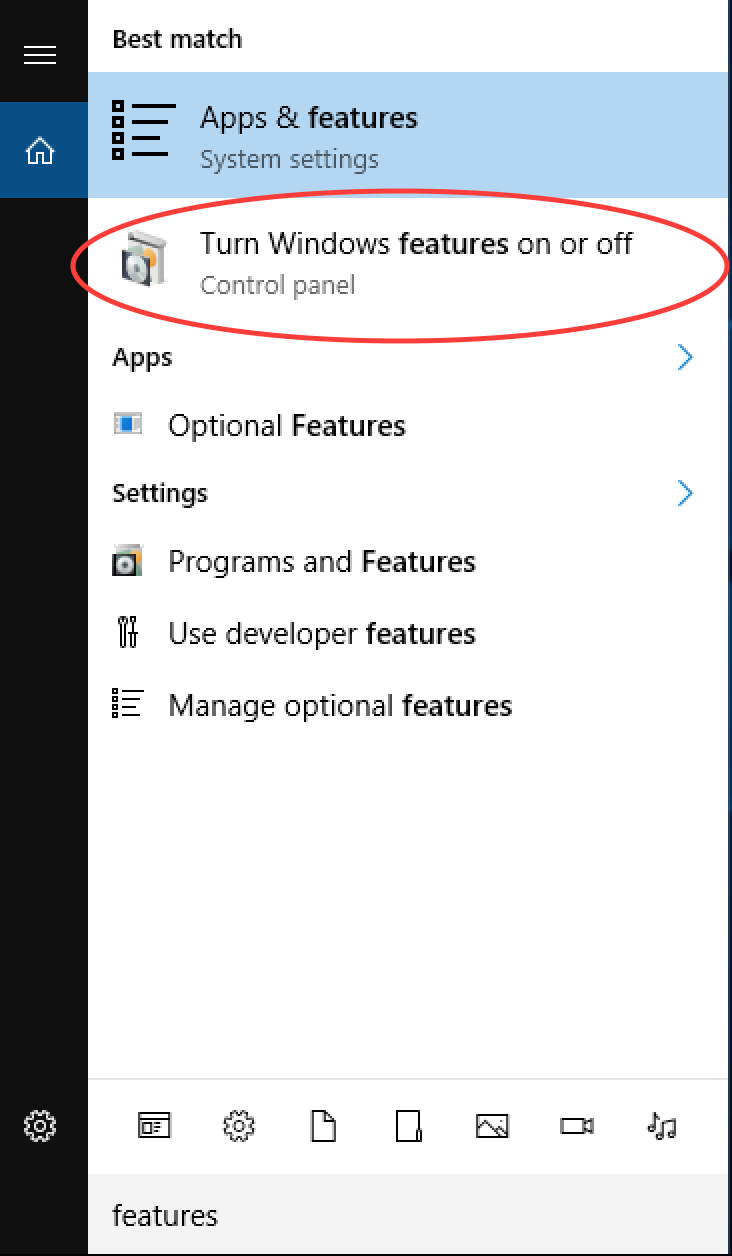
Tick Windows Subsystem for Linux (Beta) and click OK

When it’s finished churning, reboot the machine.
Launch cmd.exe
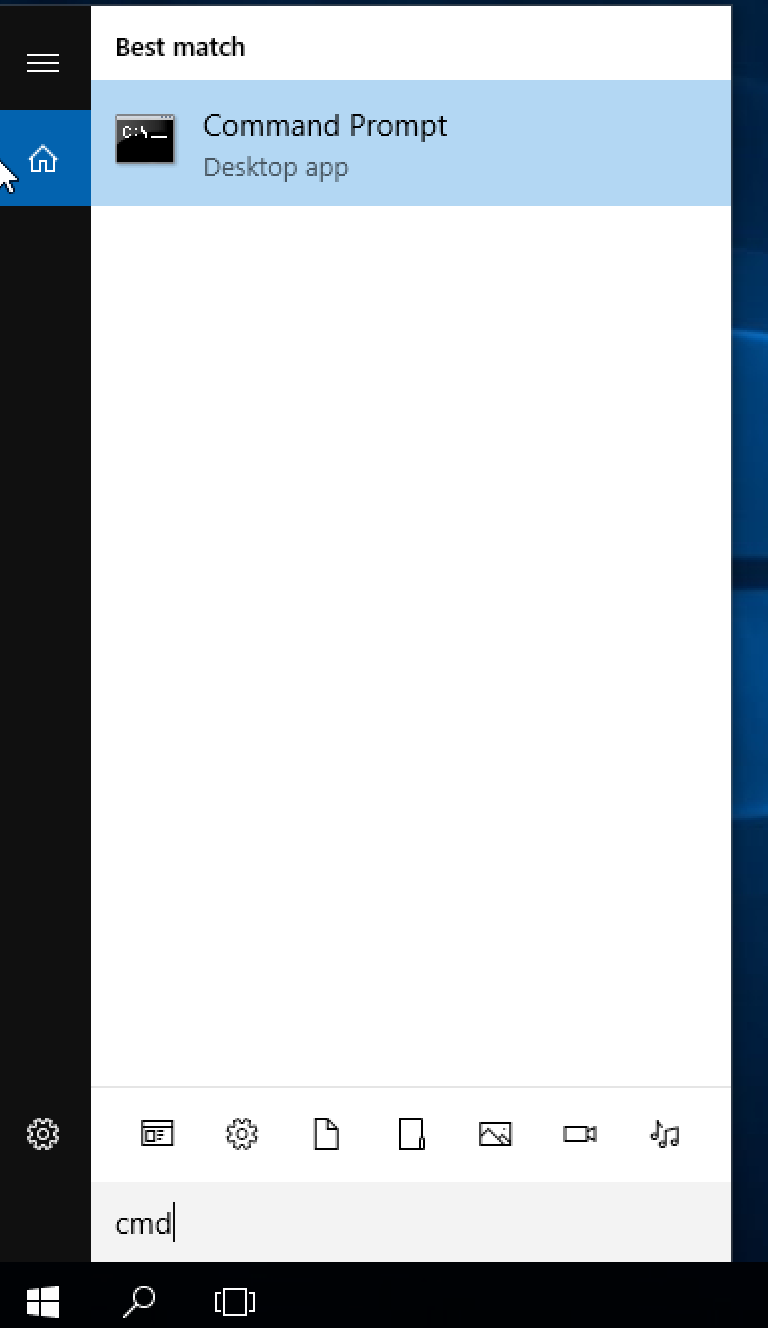
Type bash, press enter and follow the instructions
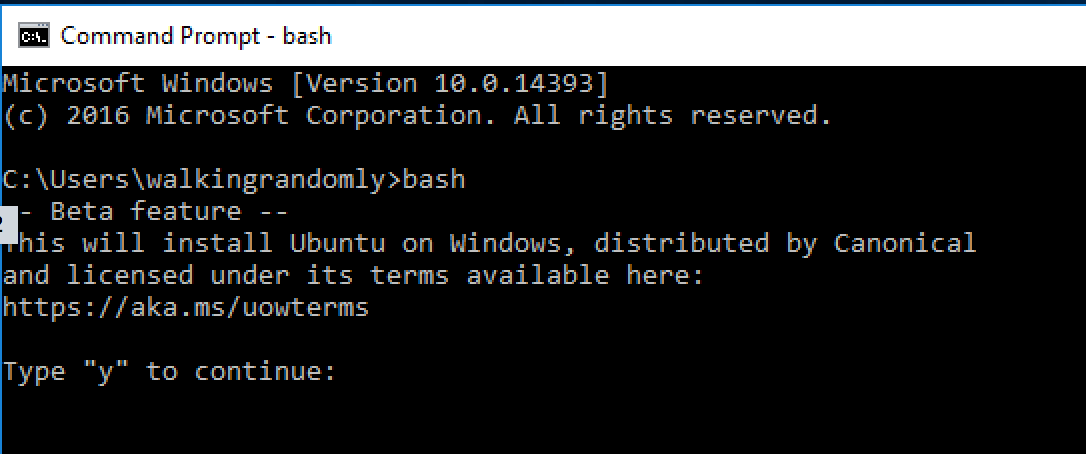
The linux subsystem will be downloaded from the windows store and you’ll be asked to create a Unix username and password.
Try something linux-y
The short version of what’s available is ‘Every userland tool that’s available for Ubuntu’ with the caveat that anything requiring a GUI won’t work.
This isn’t emulation, it isn’t cygwin, it’s something else entirely. It’s very cool!
The gcc compiler isn’t installed by default so let’s fix that:
sudo apt-get install gcc
Using your favourite terminal based editor (I used vi), enter the following ‘Hello World’ code in C and call it hello.c.
/* Hello World program */
#include
int main()
{
printf("Hello World from C\n");
return(0);
}
Compile using gcc
gcc hello.c -o hello
Run the executable
./hello Hello World from C
Now, transfer the executable to a modern Ubuntu machine (I just emailed it to myself) and run it there.
That’s right – you just wrote and compiled a C-program on a Windows machine and ran it on a Linux machine.
Now install cowsay — because you can:
sudo apt-get install cowsay
cowsay 'Hello from Windows'
____________________
< Hello from Windows >
--------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
Update 1:
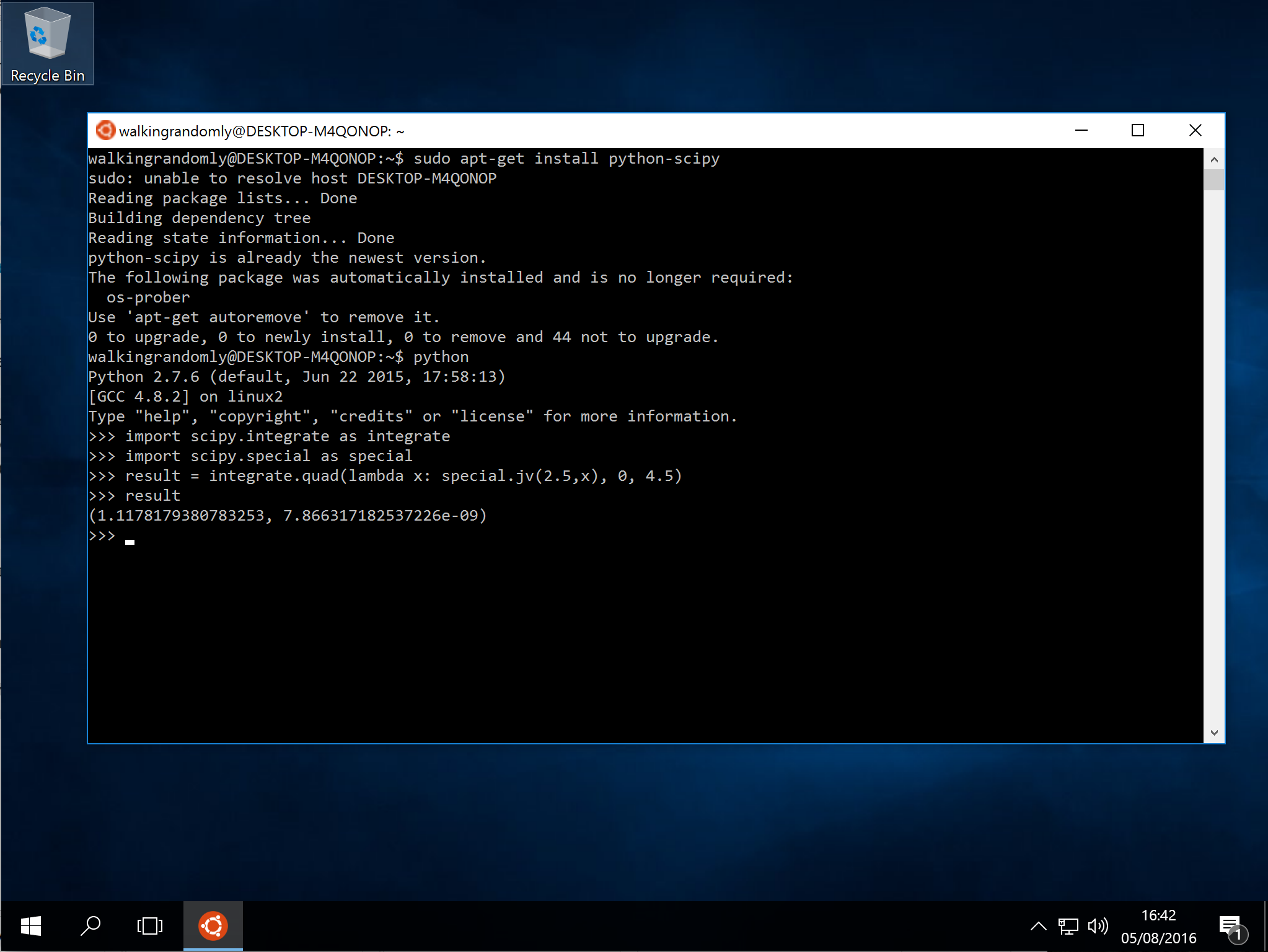
I was challenged by @linuxlizard to do a follow up tutorial that showed how to install the scientific Python stack — Numpy, SciPy etc.
@walkingrandomly Follow up with HOWTO on installing NumPy, SiPy, Pillow, etc. :-)
— David Poole (@linuxlizard) August 5, 2016
It’s all there :)
sudo apt-get install python-scipy
Update 2
TensorFlow on LinuxOnWindows is also easy: http://www.hanselman.com/blog/PlayingWithTensorFlowOnWindows.aspx