
Archive for the ‘Fortran’ Category
Earlier this week Apple announced their new, Arm-based ‘Apple Silicon’ machines to the world in a slick marketing event that had many of us reaching for our credit cards. Simultaneously, The Numerical Algorithms Group announced that they had ported their Fortran Compiler to the new platform. At the time of writing this is the only Fortran compiler publicly available for Apple Silicon although that will likely change soon as open source Fortran compilers get updated.
Fortran on your Mac! @NAGTalk announce the first Fortran Compiler for Apple Silicon Macs ahead of @Apple event #OneMoreThing – learn more https://t.co/pcCuTs2vET #AppleEvent #Apple #AppleSiliconMacs #Fortran #Compiler #SC20 @Arm pic.twitter.com/d03WsGVrUN
— NAG (@NAGTalk) November 10, 2020
Fortran? OK Boomer!
At over 60 years old, Fortran is one of the oldest programming languages that continues to be actively developed and used (The latest language specification is Fortran 2018). Routinely mocked by software engineers as old-skool (including me who, over a decade ago, suggested that it shouldn’t be taught to undergraduates), Fortran is the language that everyone overlooks as they spend their days sipping flat-whites in Starbucks while hacking away in MATLAB, R or Python on shiny Macbook Airs.
It can come as quite a shock, therefore, to discover that much of our favourite data science tools simply cannot work natively on any system that doesn’t have a Fortran compiler!
It’s Fortran all the way down
Much of the numerical functionality we routinely use today was developed decades ago and released in Fortran. More modern systems, such as R, make direct use of a lot of this code because it is highly performant and, perhaps more importantly, has been battle tested in production for decades. Numerical computing is hard (even when all of your instincts suggest otherwise) and when someone demonstrably does it right, it makes good sense to reuse rather than reinvent.
As a result, with no Fortran, there’s no R.

The Python crowd don’t get away with it either. Here are the GitHub stats for Scipy as of today
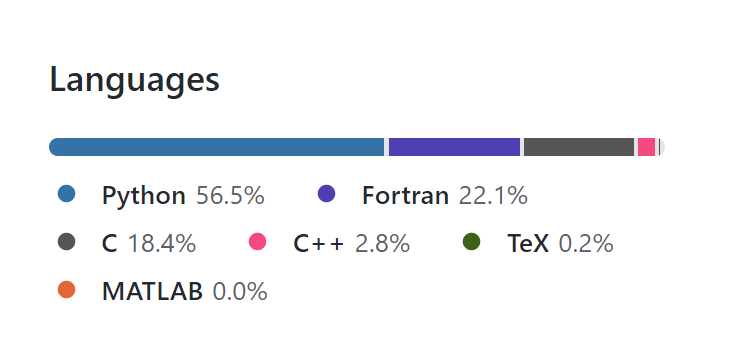
Of course, no Scipy means you also can’t have anything that depends on Scipy including things like Keras or Scikit-learn. Also, if you want good performance for linear algebra operations (Which underpins a huge number of data science and ML algorithms) then you’ll need a good BLAS implementation. Many projects use OpenBLAS (It’s a popular option in Numpy for example) which…you guessed it…is almost 49% Fortran.
Emulation for now
NAG’s Fortran compiler is excellent (it routinely tops independent charts for its checking and Fortran standards compliance for example) but it is commercial. The community needs and will demand open source (or at least free) Fortran compilers if data scientists are ever going to realise the full potential of Apple’s new hardware and I have no doubt that these are on the way. Other major silicon providers (e.g. Intel, AMD, NEC and NVIDIA/PGI) have their own Fortran compiler that co-exist with the open ones. Perhaps Apple should join the club (I suggest they talk to NAG!).
Until this is resolved, most of us will be relying on the Rosetta2 emulation…which, thankfully, is apparently pretty good!
It started with a tweet
While basking in some geek nostalgia on twitter, I discovered that my first ever microcomputer, the Sinclair Spectrum, once had a Fortran compiler

However, that compiler was seemingly lost to history and was declared Missing in Action on World of Spectrum.

A few of us on Twitter enjoyed reading the 1987 review of this Fortran Compiler but since no one had ever uploaded an image of it to the internet, it seemed that we’d never get the chance to play with it ourselves.
I never thought it would come to this
One of the benefits of 5000+ followers on Twitter is that there’s usually someone who knows something interesting about whatever you happen to tweet about and in this instance, that somebody was my fellow Fellow of the Software Sustainability Institute, Barry Rowlingson. Barry was fairly sure that he’d recently packed a copy of the Mira Fortran Compiler away in his loft and was blissfully unaware of the fact that he was sitting on a missing piece of microcomputing history!
He was right! He did have it in the attic…and members of the community considered it valuable.

As Barry mentioned in his tweet, converting a 40 year old cassette to an archivable .tzx format is a process that could result in permanent failure. The attempt on side 1 of the cassette didn’t work but fortunately, side 2 is where the action was!
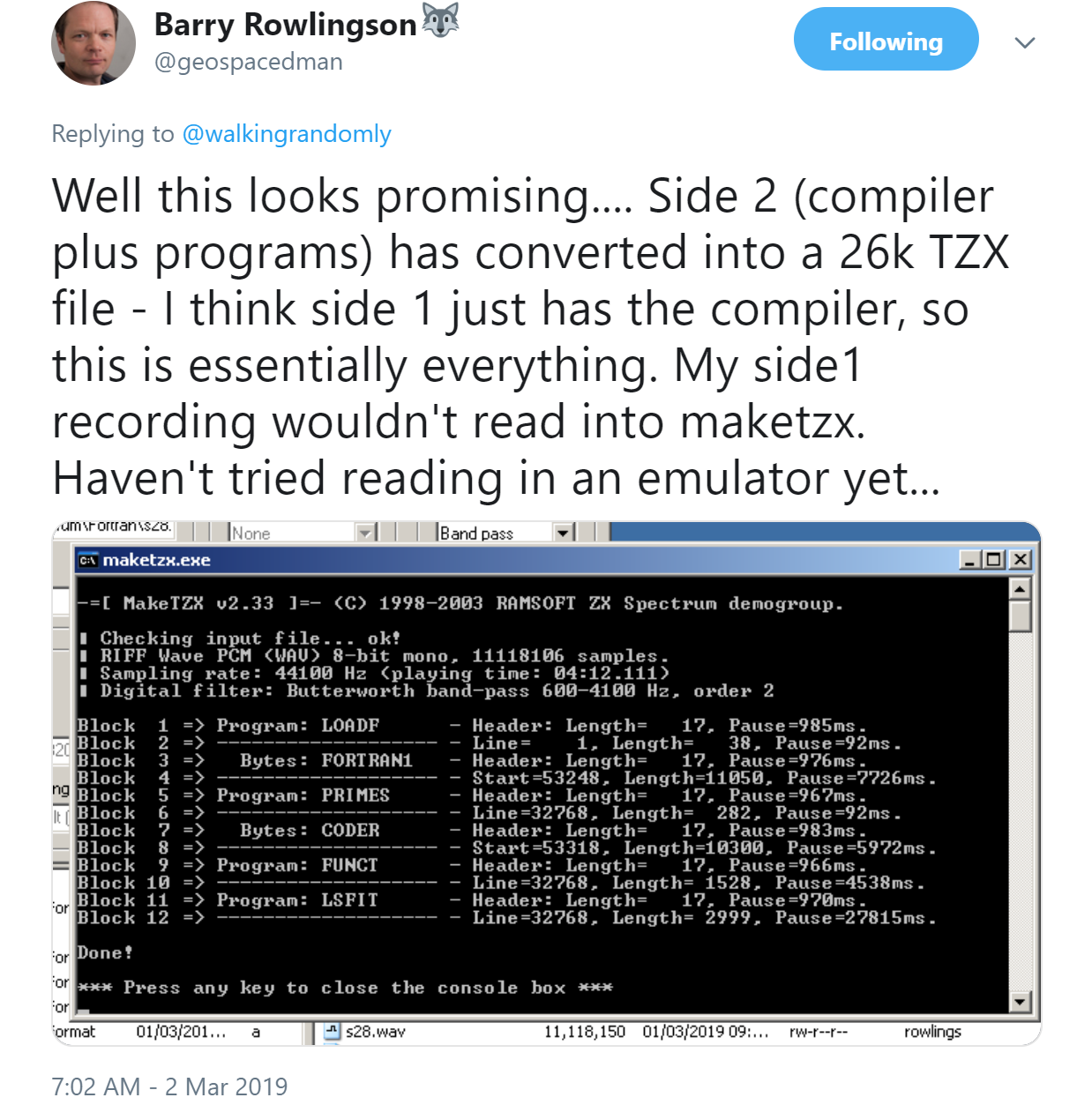
It turns out that everything worked perfectly. On loading it into a Spectrum emulator, Barry could enter and compile Fortran on this platform for the first time in decades! Here is the source code for a program that computes prime numbers

Here it is running

and here we have Barry giving the sales pitch on the advanced functionality of this compiler :)

How to get the compiler
Barry has made the compiler, and scans of the documentation, available at https://gitlab.com/b-rowlingson/mirafortran
The Numerical Algorithms Group (NAG) are principally known for their numerical library but they also offer products such as a MATLAB toolbox and a Fortran compiler. My employer, The University of Manchester, has a full site license for most of NAG’s stuff where it is heavily used by both our students and researchers.
While at a recent software conference, I saw a talk by NAG’s David Sayers where he demonstrated some of the features of the NAG Fortran Compiler. During this talk he showed some examples of broken Fortran and asked us if we could spot how they were broken without compiler assistance. I enjoyed the talk and so asked David if he would mind writing a guest blog post on the subject for WalkingRandomly. He duly obliged.
This is a guest blog post by David Sayers of NAG.
What do you want from your Fortran compiler? Some people ask for extra (non-standard) features, others require very fast execution speed. The very latest extensions to the Fortran language appeal to those who like to be up to date with their code.
I suspect that very few would put enforcement of the Fortran standard at the top of their list, yet this essential if problems are to be avoided in the future. Code written specifically for one compiler is unlikely to work when computers change, or may contain errors that appear only intermittently. Without access to at least one good checking compiler, the developer or support desk will be lacking a valuable tool in the fight against faulty code.
The NAG Fortran compiler is such a tool. It is used extensively by NAG’s own staff to validate their library code and to answer user-support queries involving user’s Fortran programs. It is available on Windows, where it has its own IDE called Fortran Builder, and on Unix platforms and Mac OS X.
Windows users also have the benefit of some Fortran Tools bundled in to the IDE. Particularly nice is the Fortran polisher which tidies up the presentation of your source files according to user-specified preferences.
The compiler includes most Fortran 2003 features, very many Fortran 2008 features and the most commonly used features of OpenMP 3.0 are supported.
The principal developer of the compiler is Malcolm Cohen, co-author of the book, Modern Fortran Explained along with Michael Metcalf and John Reid. Malcolm has been a member of the international working group on Fortran, ISO/IEC JTC1/SC22/WG5, since 1988, and the USA technical subcommittee on Fortran, J3, since 1994. He has been head of the J3 /DATA subgroup since 1998 and was responsible for the design and development of the object-oriented features in Fortran 2003. Since 2005 he has been Project Editor for the ISO/IEC Fortran standard, which has continued its evolution with the publication of the Fortran 2008 standard in 2010.
Of all people Malcolm Cohen should know Fortran and the way the standard should be enforced!
His compiler reflects that knowledge and is designed to assist the programmer to detect how programs might be faulty due to a departure from the Fortran standard or prone to trigger a run time error. In either case the diagnostics of produced by the compiler are clear and helpful and can save the developer many hours of laborious bug-tracing. Here are some particularly simple examples of faulty programs. See if you can spot the mistakes, and think how difficult these might be to detect in programs that may be thousands of times longer:
Example 1
Program test
Real, Pointer :: x(:, :)
Call make_dangle
x(10, 10) = 0
Contains
Subroutine make_dangle
Real, Target :: y(100, 200)
x => y
End Subroutine make_dangle
End Program test
Example 2
Program dangle2 Real,Pointer :: x(:),y(:) Allocate(x(100)) y => x Deallocate(x) y = 3 End
Example 3
program more
integer n, i
real r, s
equivalence (n,r)
i=3
r=2.5
i=n*n
write(6,900) i, r
900 format(' i = ', i5, ' r = ', f10.4)
stop 'ok'
end
Example 4
program trouble1
integer n
parameter (n=11)
integer iarray(n)
integer i
do 10 i=1,10
iarray(i) = i
10 continue
write(6,900) iarray
900 format(' iarray = ',11i5)
stop 'ok'
end
And finally if this is all too easy …
Example 5
! E04UCA Example Program Text
! Mark 23 Release. NAG Copyright 2011.
MODULE e04ucae_mod
! E04UCA Example Program Module:
! Parameters and User-defined Routines
! .. Use Statements ..
USE nag_library, ONLY : nag_wp
! .. Implicit None Statement ..
IMPLICIT NONE
! .. Parameters ..
REAL (KIND=nag_wp), PARAMETER :: one = 1.0_nag_wp
REAL (KIND=nag_wp), PARAMETER :: zero = 0.0_nag_wp
INTEGER, PARAMETER :: inc1 = 1, lcwsav = 1, &
liwsav = 610, llwsav = 120, &
lrwsav = 475, nin = 5, nout = 6
CONTAINS
SUBROUTINE objfun(mode,n,x,objf,objgrd,nstate,iuser,ruser)
! Routine to evaluate objective function and its 1st derivatives.
! .. Implicit None Statement ..
IMPLICIT NONE
! .. Scalar Arguments ..
REAL (KIND=nag_wp), INTENT (OUT) :: objf
INTEGER, INTENT (INOUT) :: mode
INTEGER, INTENT (IN) :: n, nstate
! .. Array Arguments ..
REAL (KIND=nag_wp), INTENT (INOUT) :: objgrd(n), ruser(*)
REAL (KIND=nag_wp), INTENT (IN) :: x(n)
INTEGER, INTENT (INOUT) :: iuser(*)
! .. Executable Statements ..
IF (mode==0 .OR. mode==2) THEN
objf = x(1)*x(4)*(x(1)+x(2)+x(3)) + x(3)
END IF
IF (mode==1 .OR. mode==2) THEN
objgrd(1) = x(4)*(x(1)+x(1)+x(2)+x(3))
objgrd(2) = x(1)*x(4)
objgrd(3) = x(1)*x(4) + one
objgrd(4) = x(1)*(x(1)+x(2)+x(3))
END IF
RETURN
END SUBROUTINE objfun
SUBROUTINE confun(mode,ncnln,n,ldcj,needc,x,c,cjac,nstate,iuser,ruser)
! Routine to evaluate the nonlinear constraints and their 1st
! derivatives.
! .. Implicit None Statement ..
IMPLICIT NONE
! .. Scalar Arguments ..
INTEGER, INTENT (IN) :: ldcj, n, ncnln, nstate
INTEGER, INTENT (INOUT) :: mode
! .. Array Arguments ..
REAL (KIND=nag_wp), INTENT (OUT) :: c(ncnln)
REAL (KIND=nag_wp), INTENT (INOUT) :: cjac(ldcj,n), ruser(*)
REAL (KIND=nag_wp), INTENT (IN) :: x(n)
INTEGER, INTENT (INOUT) :: iuser(*)
INTEGER, INTENT (IN) :: needc(ncnln)
! .. Executable Statements ..
IF (nstate==1) THEN
! First call to CONFUN. Set all Jacobian elements to zero.
! Note that this will only work when 'Derivative Level = 3'
! (the default; see Section 11.2).
cjac(1:ncnln,1:n) = zero
END IF
IF (needc(1)>0) THEN
IF (mode==0 .OR. mode==2) THEN
c(1) = x(1)**2 + x(2)**2 + x(3)**2 + x(4)**2
END IF
IF (mode==1 .OR. mode==2) THEN
cjac(1,1) = x(1) + x(1)
cjac(1,2) = x(2) + x(2)
cjac(1,3) = x(3) + x(3)
cjac(1,4) = x(4) + x(4)
END IF
END IF
IF (needc(2)>0) THEN
IF (mode==0 .OR. mode==2) THEN
c(2) = x(1)*x(2)*x(3)*x(4)
END IF
IF (mode==1 .OR. mode==2) THEN
cjac(2,1) = x(2)*x(3)*x(4)
cjac(2,2) = x(1)*x(3)*x(4)
cjac(2,3) = x(1)*x(2)*x(4)
cjac(2,4) = x(1)*x(2)*x(3)
END IF
END IF
RETURN
END SUBROUTINE confun
END MODULE e04ucae_mod
PROGRAM e04ucae
! E04UCA Example Main Program
! .. Use Statements ..
USE nag_library, ONLY : dgemv, e04uca, e04wbf, nag_wp
USE e04ucae_mod, ONLY : confun, inc1, lcwsav, liwsav, llwsav, lrwsav, &
nin, nout, objfun, one, zero
! .. Implicit None Statement ..
! IMPLICIT NONE
! .. Local Scalars ..
! REAL (KIND=nag_wp) :: objf
INTEGER :: i, ifail, iter, j, lda, ldcj, &
ldr, liwork, lwork, n, nclin, &
ncnln, sda, sdcjac
! .. Local Arrays ..
REAL (KIND=nag_wp), ALLOCATABLE :: a(:,:), bl(:), bu(:), c(:), &
cjac(:,:), clamda(:), objgrd(:), &
r(:,:), work(:), x(:)
REAL (KIND=nag_wp) :: ruser(1), rwsav(lrwsav)
INTEGER, ALLOCATABLE :: istate(:), iwork(:)
INTEGER :: iuser(1), iwsav(liwsav)
LOGICAL :: lwsav(llwsav)
CHARACTER (80) :: cwsav(lcwsav)
! .. Intrinsic Functions ..
INTRINSIC max
! .. Executable Statements ..
WRITE (nout,*) 'E04UCA Example Program Results'
! Skip heading in data file
READ (nin,*)
READ (nin,*) n, nclin, ncnln
liwork = 3*n + nclin + 2*ncnln
lda = max(1,nclin)
IF (nclin>0) THEN
sda = n
ELSE
sda = 1
END IF
ldcj = max(1,ncnln)
IF (ncnln>0) THEN
sdcjac = n
ELSE
sdcjac = 1
END IF
ldr = n
IF (ncnln==0 .AND. nclin>0) THEN
lwork = 2*n**2 + 20*n + 11*nclin
ELSE IF (ncnln>0 .AND. nclin>=0) THEN
lwork = 2*n**2 + n*nclin + 2*n*ncnln + 20*n + 11*nclin + 21*ncnln
ELSE
lwork = 20*n
END IF
ALLOCATE (istate(n+nclin+ncnln),iwork(liwork),a(lda,sda), &
bl(n+nclin+ncnln),bu(n+nclin+ncnln),c(max(1, &
ncnln)),cjac(ldcj,sdcjac),clamda(n+nclin+ncnln),objgrd(n),r(ldr,n), &
x(n),work(lwork))
IF (nclin>0) THEN
READ (nin,*) (a(i,1:sda),i=1,nclin)
END IF
READ (nin,*) bl(1:(n+nclin+ncnln))
READ (nin,*) bu(1:(n+nclin+ncnln))
READ (nin,*) x(1:n)
! Initialise E04UCA
ifail = 0
CALL e04wbf('E04UCA',cwsav,lcwsav,lwsav,llwsav,iwsav,liwsav,rwsav, &
lrwsav,ifail)
! Solve the problem
ifail = -1
CALL e04uca(n,nclin,ncnln,lda,ldcj,ldr,a,bl,bu,confun,objfun,iter, &
istate,c,cjac,clamda,objf,objgrd,r,x,iwork,liwork,work,lwork,iuser, &
ruser,lwsav,iwsav,rwsav,ifail)
SELECT CASE (ifail)
CASE (0:6,8)
WRITE (nout,*)
WRITE (nout,99999)
WRITE (nout,*)
DO i = 1, n
WRITE (nout,99998) i, istate(i), x(i), clamda(i)
END DO
IF (nclin>0) THEN
! A*x --> work.
! The NAG name equivalent of dgemv is f06paf
CALL dgemv('N',nclin,n,one,a,lda,x,inc1,zero,work,inc1)
WRITE (nout,*)
WRITE (nout,*)
WRITE (nout,99997)
WRITE (nout,*)
DO i = n + 1, n + nclin
j = i - n
WRITE (nout,99996) j, istate(i), work(j), clamda(i)
END DO
END IF
IF (ncnln>0) THEN
WRITE (nout,*)
WRITE (nout,*)
WRITE (nout,99995)
WRITE (nout,*)
DO i = n + nclin + 1, n + nclin + ncnln
j = i - n - nclin
WRITE (nout,99994) j, istate(i), c(j), clamda(i)
END DO
END IF
WRITE (nout,*)
WRITE (nout,*)
WRITE (nout,99993) objf
END SELECT
99999 FORMAT (1X,'Varbl',2X,'Istate',3X,'Value',9X,'Lagr Mult')
99998 FORMAT (1X,'V',2(1X,I3),4X,1P,G14.6,2X,1P,G12.4)
99997 FORMAT (1X,'L Con',2X,'Istate',3X,'Value',9X,'Lagr Mult')
99996 FORMAT (1X,'L',2(1X,I3),4X,1P,G14.6,2X,1P,G12.4)
99995 FORMAT (1X,'N Con',2X,'Istate',3X,'Value',9X,'Lagr Mult')
99994 FORMAT (1X,'N',2(1X,I3),4X,1P,G14.6,2X,1P,G12.4)
99993 FORMAT (1X,'Final objective value = ',1P,G15.7)
END PROGRAM e04ucae
Answers to this particular New Year quiz will be posted in a future blog post.
I work for the University of Manchester in the UK as a ‘Science and Engineering Applications specialist’ which basically means that I am obsessed with software used by mathematicians and scientists. One of the applications within my portfolio is the NAG library – a product that we use rather a lot in its various incarnations. We have people using it from Fortran, C, C++, MATLAB, Python and even Visual Basic in areas as diverse as engineering, applied maths, biology and economics.
Yes, we are big users of NAG at Manchester but then that stands to reason because NAG and Manchester have a collaborative history stretching back 40 years to NAG’s very inception. Manchester takes a lot of NAG’s products but for reasons that are lost in the mists of time, we have never (to my knowledge at least) had a site license for their SMP library (more recently called The NAG Library for SMP & multicore). Very recently, that changed!
SMP stands for Symmetric Multi-Processor which essentially means ‘two or more CPUs sharing the same bit of memory.’ Five years ago, it would have been rare for a desktop user to have an SMP machine but these days they are everywhere. Got a dual-core laptop or a quad-core desktop? If the answer’s ‘yes’ then you have an SMP machine and you are probably wondering how to get the most out of it.
‘How can I use all my cores (without any effort)’
One of the most common newbie questions I get asked these days goes along the lines of ‘Program X is only using 50%/25%/12.5% of my CPU – how can I fix this?’ and, of course, the reason for this is that the program in question is only using a single core of their multicore machine. So, the problem is easy enough to explain but not so easy to fix because it invariably involves telling the user that they are going to have to learn how to program in parallel.
Explicit parallel programming is a funny thing in that sometimes it is trivial and other times it is pretty much impossible – it all depends on the problem you see. Sometimes all you need to do is drop a few OpenMP pragmas here and there and you’ll get a 2-4 times speed up. Other times you need to completely rewrite your algorithm from the ground up to get even a modest speed up. Yet more times you are simply stuck because your problem is inherently non-parallelisable. It is even possible to slow your code down by trying to parallelize it!
If you are lucky, however, then you can make use of all those extra cores with no extra effort at all! Slowly but surely, mathematical software vendors have been re-writing some of their functions to ensure that they work efficiently on parallel processors in such a way that it is transparent to the user. This is sometimes referred to as implicit parallelism.
Take MATLAB, for example, ever since release 2007a more and more built in MATLAB functions have been modified to allow them to make full use of multi-processor systems. If your program makes extensive use of these functions then you don’t need to spend extra money or time on the parallel computing toolbox, just run your code on the latest version of MATLAB, sit back and enjoy the speed boost. It doesn’t work for all functions of course but it does for an ever increasing subset.
The NAG SMP Library – zero effort parallel programming
For users of NAG routines, the zero-effort approach to making better use of your multicore system is to use their SMP library. According to NAG’s advertising blurb you don’t need to rewrite your code to get a speed boost – you just need to link to the SMP library instead of the Fortran library at compile time.
Just like MATLAB, you won’t get this speed boost for every function, but you will get it for a significant subset of the library (around 300+ functions as of Mark 22 – the full list is available on NAG’s website). Also, just like MATLAB, sometimes the speed-up will be massive and other times it will be much more modest.
I wanted to test NAG’s claims for myself on the kind of calculations that researchers at Manchester tend to perform so I asked NAG for a trial of the upcoming Mark 22 of the SMP library and, since I am lazy, I also asked them to provide me with simple demonstration programs and I’d like to share the results with you all. These are not meant to be an exhaustive set of benchmarks (I don’t have the time to do such a thing) but should give you an idea of what you can expect from NAG’s new library.
System specs
All of these timings were made on a 3Ghz Intel Core2 Quad Q9650 CPU desktop machine with 8Gb of RAM running Ubuntu 9.10. The serial version of the NAG library used was fll6a22dfl and the SMP version of the library was fsl6a22dfl. The version of gfortran used was 4.4.1 and the cpu-frequency governor was switched off as per a previous blog post of mine.
Example 1 – Nearest correlation matrix
The first routine I looked at was one that calculated the nearest correlation matrix. In other words ‘Given a symmetric matrix, what is the nearest correlation matrix—that is, the nearest symmetric positive semidefinite matrix with unit diagonal?’[1] This is a problem that pops up a lot in Finance – option pricing, risk management – that sort of thing.
The NAG routine that calculates the nearest correlation matrix is G02AAF which is based on the algorithm developed by Qi and Sun[2]. The example program I was sent first constructs a N x N tridiagonal matrix A of the form A(j,j)=2, A(j-1,j)=-1.1 and A(j,j-1)=1.0. It then times how long it takes G02AAF to find the nearest correlation matrix to A. You can download this example, along with all supporting files, from the links below.
To compile this benchmark against the serial library I did
gfortran ./bench_g02aaf.f90 shtim.c wltime.f /opt/NAG/fll6a22dfl/lib/libnag_nag.a \ /opt/NAG/fll6a22dfl/acml/libacml_mv.a -o serial_g02aaf
To compile the parallel version I did
gfortran -fopenmp ./bench_g02aaf.f90 shtim.c wltime.f /opt/NAG/fsl6a22dfl/lib/libnagsmp.a \ /opt/NAG/fsl6a22dfl/acml4.3.0/lib/libacml_mp.a -o smp_g02aaf
I didn’t need to modify the source code in any way when going from a serial version to a parallel version of this benchmark. The only work required was to link to the SMP library instead of the serial library – so far so good. Let’s run the two versions and see the speed differences.
First things first, let’s ensure that there is no limit to the stack size of my shell by doing the following in bash
ulimit -s unlimited
Also, for the parallel version, I need to set the number of threads to equal the number of processors I have on my machine by setting the OMP_NUM_THREADS environment variable.
export OMP_NUM_THREADS=4
This won’t affect the serial version at all. So, onto the program itself. When you run it, it will ask you for two inputs – an integer, N, and a boolean, IO. N gives the size of the starting matrix and IO determines whether or not to output the result.
Here’s an example run of the serial version with N=1000 and IO set to False. (In Fortran True is represented as .t. and False is represented as .f. )
./serial_g02aaf G02AAF: Enter N, IO 1000 .f. G02AAF: Time, IFAIL = 37.138997077941895 0 G02AAF: ITER, FEVAL, NRMGRD = 4 5 4.31049822255544465E-012
The only output I am really interested in here is the time and 37.13 seconds doesn’t seem too bad for a 1000 x 1000 matrix at first glance. Move to the parallel version though and you get a very nice surprise
./smp_g02aaf G02AAF: Enter N, IO 1000 .f. G02AAF: Time, IFAIL = 5.1906139850616455 0 G02AAF: ITER, FEVAL, NRMGRD = 4 5 4.30898281428799420E-012
The above times were typical and varied little from run to run (although the SMP version varied by a bigger percentage than the serial version). However I averaged over 10 runs to make sure and got 37.14 s for the serial version and 4.88 s for the SMP version which gives a speedup of 7.6 times!
Now, this is rather impressive. Usually, when one parallelises over N cores then the very best you can expect in an ideal word is a speed up of just less than N times, so called ‘linear scaling’. Here we have N=4 and a speedup of 7.6 implying that NAG have achieved ‘super-linear scaling’ which is usually pretty rare.
I dropped them a line to ask what was going on. It turns out that when they looked at parallelising this routine they worked out a way of speeding up the serial version as well. This serial speedup will be included in the serial library in its next release, Mark 23 but the SMP library got it as of Mark 22.
So, some of that 7.6 times speedup is as a result of serial speedup and the rest is parallelisation. By setting OMP_NUM_THREADS to 1 we can force the SMP version of the benchmark to only run on only one core and thus see how much of the speedup we can attribute to parallelisation:
export OMP_NUM_THREADS=1 ./smp_g02aaf G02AAF: Enter N, IO 1000 .f. G02AAF: Time, IFAIL = 12.714214086532593 0 G02AAF: ITER, FEVAL, NRMGRD = 4 5 4.31152424170390294E-012
Recall that the 4 core version took an average of 4.88 seconds so the speedup from parallelisation alone is 2.6 times – much closer to what I expected to see. Now, it is probably worth mentioning that there is an extra level of complication (with parallel programming there is always an extra level of complication) in that some of this parallelisation speedup comes from extra work that NAG has done in their algorithm and some of it comes from the fact that they are linking to parallel versions of the BLAS and LAPACK libraries. We could go one step further and determine how much of the speed up comes from NAG’s work and how much comes from using parallel BLAS/LAPACK but, well, life is short.
The practical upshot is that if you come straight from the Mark 22 serial version then you can expect a speed-up of around 7.6 times. In the future, when you compare the Mark 22 SMP library to the Mark 23 serial library then you can expect a speedup of around 2.6 times on a 4 core machine like mine.
Example 2 – Quasi random number generation
Quasi random numbers (also referred to as ‘Low discrepancy sequences’) are extensively used in Monte-Carlo simulations which have applications in areas such as finance, chemistry and computational physics. When people need a set of quasi random numbers they usually need a LOT of them and so the faster they can be produced the better. The NAG library contains several quasi random number generators but the one considered here is the routine g05ymf. The benchmark program I used is called bench_g05ymf.f90 and the full set of files needed to compile it are available at the end of this section.
The benchmark program requires the user to input 4 numbers and a boolean as follows.
- The first number is the quasi random number generator to use with the options being:
- NAG’s newer Sobol generator (based on the 2008 Joe and Kuo algorithm[3] )
- NAG’s older Sobol generator
- NAG’s Niederreiter generator
- NAG’s Faure generator
- The second number is the order in which the generated values are returned (The parameter RCORD as referred to in the documentation for g05ymf). Say that the matrix of returned values is called QUAS then if RCORD=1, QUAS(i,j) holds the jth value for the ith dimension, otherwise QUAS(i,j) holds the ith value for the jth dimension.
- The third number is the number of dimensions required.
- The fourth number is the number of number of quasi-random numbers required.
- The boolean (either .t. or .f.) determines whether or not the output should be verbose or not. A value of .t. will output the first 100 numbers in the sequence.
To compile the benchmark program against the serial library I did:
gfortran ./bench_g05ymf.f90 shtim.c wltime.f /opt/NAG/fll6a22dfl/lib/libnag_nag.a \ /opt/NAG/fll6a22dfl/acml/libacml_mv.a -o serial_g02aaf
As before, the only thing needed to turn this into a parallel program was to compile against the SMP library and add the -fopenmp switch
gfortran -fopenmp ./bench_g05ymf.f90 shtim.c wltime.f /opt/NAG/fsl6a22dfl/lib/libnagsmp.a \ /opt/NAG/fsl6a22dfl/acml4.3.0/lib/libacml_mp.a -o smp_g02aaf
The first set of parameters I used was
1 2 900 1000000 .f.
Which uses NAG’s new Sobol generator with RCORD=2 to generate and store 1,000,000 numbers over 900 dimensions with no verbose output. Averaged over 10 runs the times were 5.17 seconds for the serial version and 2.14 seconds for the parallel version giving a speedup of 2.4x on a quad-core machine. I couldn’t push number of dimensions much higher because the benchmark stores all of the numbers in one large array and I was starting to run out of memory.
If you only want a relatively small sequence then switching to the SMP library is actually slower thanks to the overhead involved in spawning extra threads. For example if you only want 100,000 numbers over 8 dimensions:
1 2 8 100000 .f.
then the serial version of the code takes an average of 0.0048 seconds compared to 0.0479 seconds for the parallel version so the parallel version is almost 10 times slower when using 4 threads for small problems. Setting OMP_NUM_THREADS to 1 gives exactly the same speed as the serial version as you might expect.
NAG have clearly optimized this function to ensure that you get a good speedup for large problem sets which is where it really matters so I am very pleased with it. However, the degradation in performance for smaller problems concerns me a little. I think I’d prefer it if NAG were to modify this function so that it works serially for small sequences and to automatically switch to parallel execution if the user requests a large sequence.
Conclusions
In the old days we could speedup our programs simply by buying a new computer. The new computer would have a faster clock speed than the old one and so our code would run faster with close to zero effort on our part. Thanks to the fact that clock speeds have stayed more or less constant for the last few years those days are over. Now, when we buy a new computer we get more processors rather than faster ones and this requires a change in thinking. Products such as the NAG Library for SMP & multicore help us to to get the maximum benefit out of our machines with the minimum amount of effort on our part. If switching to a product like this doesn’t give you the performance boost you need then the next thing for you to do is to learn how to program in parallel. The free ride is over.
In summary:
- You don’t need to modify your code if it already uses NAG’s serial library. Just recompile against the new library and away you go. You don’t need to know anything about parallel programming to make use of this product.
- The SMP Library works best with big problems. Small problems don’t work so well because of the inherent overheads of parallelisation.
- On a quad-core machine you can expect speed-ups around 2-4 times compared to the serial library. In exceptional circumstances you can expect speed-up as large as 7 times or more.
- You should notice a speed increase in over 300 functions compared to the serial library.
- Some of this speed increase comes from fundamental libraries such as BLAS and LAPACK, some of it comes from NAG directly parallelising their algorithms and yet more comes from improvements to the underlying serial code.
- I’m hoping that this Fortran version is just the beginning. I’ve always felt that NAG program in Fortran so I don’t have to and I’m hoping that they will go on to incorporate their SMP improvements in their other products, especially their C library and MATLAB toolbox.
Acknowledgements
Thanks to several staff at NAG who suffered my seemingly endless stream of emails during the writing of this article. Ed, in particular, has the patience of a saint. Any mistakes left over are all mine!
Links
- The Nearest Correlation Matrix benchmark program used here – bench_g02aaf.f90 – along with the source code for the timing routine.
- NAG’s documentation for the g02aaf routine.
- The Quasi Random Number benchmark program used here – bench_g05ymf.f90 – along with the source code for the timing routine.
- An Introduction to quasi random numbers (written by a member of NAG’s staff)
- Official NAG documentation for g05ymf – the quasi random number generator considered here.
References
[1] – Higham N, Computing the nearest correlation matrix—a problem from finance, IMA Journal of Numerical Analysis 22 (3): 329–343
[2] – Qi H and Sun D (2006), A Quadratically Convergent Newton Method for Computing the Nearest
Correlation Matrix, SIAM J. Matrix AnalAppl 29(2) 360–385
[3] – Joe S and Kuo F Y (2008) Constructing Sobol sequences with better two-dimensional projects SIAM J. Sci. Comput. 30 2635–2654
Dislaimer: This is a personal blog and the opinions expressed on it are mine and do not necessarily reflect the policies and opinions of my employer, The University of Manchester.
Back in 1997 I was a 2nd year undergraduate of Physics and I was taught how to program in Fortran, a language that has survived over 40 years due to several facts including
- It is very good at what it does. Well written Fortran code, pushed through the right compiler is screamingly fast.
- There are millions of lines of legacy code still being used in the wild. If you end up doing research in subjects such as Chemistry, Physics or Engineering then you will almost certainly bump into Fortran code (I did!).
- A beginner’s course in Fortran has been part of the staple diet in degrees in Physics, Chemistry and various engineering disciplines (among others) for decades.
- It constantly re-invents itself to include new features. I was taught Fortran 77 (despite it being 1997) but you can now also have your pick of Fortran 90, 95, 2003, and soon 2008.
Almost everyone I knew hated that 1997 Fortran course and the reasons for the hatred essentially boiled down to one of two points depending on your past experience.
- Fortran was too hard! So much work for such small gains (First time – programmers)
- The course was far too easy. It was just a matter of learning Fortran syntax and blitzing through the exercises. (People with prior experience)
The course was followed by a numerical methods course which culminated in a set of projects that had to be solved in Fortran. People hated the follow on course for one of two reasons
- They didn’t have a clue what was going on in the first course and now they were completely lost.
- The problems given were very dull and could be solved too easily. In Excel! Fortran was then used to pass the course.
Do you see a pattern here?
Fast forward to 2009 and I see that Fortran is still being taught to many undergraduates all over the world as their first ever introduction to programming. Bear in mind that these students are used to being able to get interactive 3D plots from the likes of Mathematica, Maple or MATLAB and can solve complex differential equations simply by typing them into Wolfram Alpha on the web. They can solve problems infinitely more complicated then the ones I was faced with in even my most advanced Fortran courses with just a couple of lines of code.
Learn Fortran – spend a semester achieving not very much
These students study subjects such as physics and chemistry because they are interested in the subject matter and computers are just a way of crunching through numbers (and the algebra for that matter) as far as they are concerned. Despite having access to untold amounts of computational and visualisation power coupled with easy programming languages thanks to languages such as MATLAB and Python, these enthusiastic, young potential programmers get forced to bend their minds around the foibles of Fortran.
For many it’s their first ever introduction to programming and they get forced to work with one of the most painful programming languages in existence (in my opinion at least). Looking at a typical one-semester course it seems that by the time they have finished they will be able to produce command line only programs that do things like multiply matrices together (slowly), solve the quadratic equation and find the mean and standard deviation of a list of numbers.
Not particularity impressive for an introduction to the power of computation in their subject is it?
Fortran syntax is rather unforgiving compared to something like Python and it takes many lines of code to achieve even relatively simple results. Don’t believe me? OK, write a program in pure Fortran that gives a plot of a Sin(n*x) for integer n and x ranging from -2*pi to 2*pi. Now connect that plot up to a slider control which will control the value of n. Done? Ok – now get it working on another operating system (eg if you originally used Windows, get it to work on Mac OS X).
Now try the same exercise in Python or Mathematica.
This is still a very basic program but it would give a much greater sense of achievement compared to finding the mean of list of numbers and could easily be extended for more able students (Fourier Series perhaps). I believe that many introductory Fortran programming courses end up teaching students that programming means ‘Calculating things the hard way’ when they should be leaving an introductory course with the opposite impression.
Learn Fortran – and never use it again.
Did you learn Fortran at University? Are you still using it? If you answer yes to both of those questions then there is a high probability that you are still involved in research or that advanced numerical analysis is the mainstay of your job. I know a lot of people in the (non-academic) IT industry – many of them were undergraduates in Physics or Chemistry and so they learned Fortran. They don’t use it anymore. In fact they never used it since completing their 1st semester, 2nd year exam and that includes the computational projects they chose to do as part of their degrees.
The fact of the matter is that most undergraduates in subjects such as Physics end up in careers that have nothing to do with their degree subject and so most of them will never use Fortran ever again. The ‘programming concepts’ they learned might be useful if they end up learning Java, Python or something along those lines but that’s about it. Would it not be more sensible to teach a language that can support the computational concepts required in the underlying subject that also has an outside chance of being used outside of academia?
Teach Fortran – and spend a fortune on compilers
There are free Fortran compilers available but in my experience these are not the ones that get used the most for teaching or research and this is because the commercial Fortran compilers tend to be (or at least,they are perceived to be) much better. The problem is that when you are involved with looking after the software portfolio of a large University (and I am) then no one will agree on what ‘the best’ compiler is. (Very) roughly paraphrased, here are some comments I have received from Fortran programmers and teachers over the last four years or so.
- When you teach Fortran, you MUST use the NAG Fortran compiler since it is the most standards compliant. The site license allows students to have it on their own machines which is useful.
- When you teach Fortran, you MUST use the Silverfrost compiler because it supports Windows GUI programming via Clearwin.
- We MUST avoid the Silverfrost compiler for teaching because it is not available on platforms such as Mac and Linux.
- We MUST avoid the NAG compiler for teaching because although it has a great user interface for Windows, it is command line only for Linux and Mac. This confuses students.
- If we are going to teach Fortran then we simply MUST use the Intel Fortran Compiler. It’s the best and the fastest.
- We need the Intel Fortran Compiler for research because it is the only one compatible with Abaqus.
- A site license for Absoft Fortran is essential. It’s the only one that will compile <insert application here> which is essential for my group’s work.
- We should only ever use free Fortran compilers – relying on commercial offerings is wrong.
I’m only getting started! Choose a compiler, any compiler – I’ll get back to you within the week with an advocate who thinks we should get a site license for it and another who hates it with a passion. Let’s say you had a blank cheque book and you gave everyone exactly what they wanted – your institution would be spending tens of thousands of pounds on Fortran compilers and you’d still be annoying the free-software advocate.
Needless to say, most people don’t have a blank cheque book. At Manchester University (my workplace) we support 2 site-wide Fortran compilers
- The NAG Compiler – recommended for teaching.
- The Intel Fortran Compiler – recommended for research
We have a truly unlimited site license for NAG (every student can have a copy on their own machine if they wish) which makes it perfect from a licensing point of view and many people like to use it to teach. The Widows version has a nice GUI and help system for example – perfect for beginners. There are Mac and Linux versions too and although these are command-line only, they are better than nothing.
The Intel Fortran Compiler licenses we have are in the form of network licenses and we have a very limited number of these – enough to support the research of every (Windows and Linux) Fortran programmer on campus but nowhere near enough for teaching. To get enough for teaching would cost a lot.
There are also pockets of usage of various other compilers but nothing on a site-wide basis.
Of course, not everyone is happy with this set-up, and I was only recently on the receiving end of a very nasty email from someone because I had to inform him that we didn’t have the money to buy his compiler of choice. It’s not my fault that he couldn’t have it (I don’t have a budget and never have had) but he felt that I was due an ear lashing I guess and blamed all of his entire department’s woes on me personally. Anway, I digress….
The upshot is that Fortran compilers are expensive and no one can agree on which one(s) you should get. If you get them all to please (almost) everybody then you will be very cash poor and it won’t be long before the C++ guys start knocking on your door to discuss the issue of a commercial C++ compiler or three….
Learn Fortran – because it is still very useful
Fortran has been around in one form or another for significantly longer than I have been alive for a very good reason. It’s good at what it does. I know a few High Performance Computing specialists and have been reliably informed that if every second counts in your code execution – if it absolutely, positively, definitely has to run as fast as humanly possible then it is hard to beat Fortran. I take their word for it because they know what they are talking about.
Organisations such as the Numerical Algorithm’s Group (NAG) seem to agree with this stance since their core product is a Fortran Library and NAG have a reputation that is hard to ignore. When it comes to numerics – they know their stuff and they work in Fortran so it MUST be a good choice for certain applications.
If you find yourself using research-level applications such as Abaqus or Gaussian then you’ll probably end up needing to use Fortran, just as you will if you end up having to modify one of the thousands of legacy applications out there. Fortran is a fact of life for many graduate students. It was a fact of life for me too once and I hated it.
I know that it is used a lot at Manchester for research because ,as mentioned earlier, we have network licenses for Intel Fortran and when I am particularly bored I grep the usage logs to see how many unique user names have used it to compile something. There are many.
I am not for a second suggesting that Fortran is irrelevant because it so obviously isn’t. It is heavily used in certain, specialist areas. What I am suggesting is that it is not the ideal language to use as a first exposure to programming. All of the good reasons for using Fortran seem to come up at a time in your career when you are a reasonably advanced programmer not when you first come across the concepts loops and arrays.
Put bluntly I feel that the correct place for learning Fortran is in grad school and only if it is needed.
If not Introductory Fortran then Introductory what?
If you have got this far then you can probably guess what I am going to suggest – Python. Python is infinitely more suitable for beginner programmers in my opinion and with even just a smattering of the language it is possible to achieve a great deal. Standard python modules such as matplotlib and numpy help take care of plotting and heavy-duty numerics with ease and there are no licensing problems to speak of . It’s free!
You can use it interactively which helps with learning the basics and even a beginner can produce impressive looking results with relatively little effort. Not only is it more fun than Fortran but it is probably a lot more useful for an undergraduate because they might actually use it. Its use in the computational sciences is growing very quickly and it also has a lot of applications in areas such as the web, games and general task automation.
If and when a student is ready to move onto graduate level problems then he/she may well find that Python still fulfills their needs but if they really do need raw speed then they can either hook into existing Fortran libraries using Python modules such as ctypes and f2py or they can roll up their sleeves and learn Fortran syntax.
Using Fortran to teach raw beginners is a bit like teaching complex numbers to kindergarten children before they can count to ten. Sure, some of them will need complex numbers one day but if it was complex numbers or nothing then a lot of people would really struggle to count.
So, I am (finally) done. Do I have it all wrong? Is Fortran so essential that Universities would be short changing students of numerate degrees if they didn’t teach it or are people just teaching what they were taught themselves because that’s the way it has always been done? I am particularly interested in hearing from either students or teachers of Fortran but, as always, comments from everyone are welcome – even if you disagree with me.
If you are happy to talk in public then please use the comments section but if you would prefer a private discussion then feel free to email me.
(I am skating closer to my job than I usually do on this blog so here is the hopefully unnecessary disclaimer. These are my opinions alone and do not necessarily reflect the policy of my employer, The Univeristy of Manchester. If you find yourself coming to me for Fortran compiler support there then I will do the very best I can for you – no matter what my personal programming prejudices may be. However, if you are up for a friendly chat over coffee concerning this then feel free to drop me a line. )