
Archive for April, 2019
My preferred workflow for writing technical documents these days is to write in Markdown (Or Jupyter Notebooks) and then use Pandoc to convert to PDF, Microsoft Word or whatever format is required by the end client.
While working with a markdown file recently, the pandoc conversion to PDF failed with the following error message
! Undefined control sequence. l.117 \[ \coloneqq
This happens because Pandoc first converts the Markdown file to LaTeX which then gets compiled to PDF and the command \coloneqq isn’t included in any of the LaTeX packages that Pandoc uses by default.
The coloneqq command is in the mathtools package which, on Ubuntu, can be installed using
apt-get install texlive-latex-recommended
Once we have the package installed, we need to tell Pandoc to make use of it. The way I did this was to create a Pandoc metadata file that contained the following
---
header-includes: |
\usepackage{mathtools}
---
I called this file pandoc_latex.yml and passed it to Pandoc as follows
pandoc --metadata-file=./pandoc_latex.yml ./input.md -o output.pdf
On one system I tried this on, I received the following error message
pandoc: unrecognized option `--metadata-file=./pandoc_latex.yml'
which suggests that the –metadata-file option is a relatively recent addition to Pandoc. I have no idea when this option was added but if this happens to you, you could try installing the latest version from https://github.com/jgm/pandoc/
I used 2.7.1.1 and it was fine so I guess anything later than this should also be OK.
It started with a tweet
While basking in some geek nostalgia on twitter, I discovered that my first ever microcomputer, the Sinclair Spectrum, once had a Fortran compiler

However, that compiler was seemingly lost to history and was declared Missing in Action on World of Spectrum.

A few of us on Twitter enjoyed reading the 1987 review of this Fortran Compiler but since no one had ever uploaded an image of it to the internet, it seemed that we’d never get the chance to play with it ourselves.
I never thought it would come to this
One of the benefits of 5000+ followers on Twitter is that there’s usually someone who knows something interesting about whatever you happen to tweet about and in this instance, that somebody was my fellow Fellow of the Software Sustainability Institute, Barry Rowlingson. Barry was fairly sure that he’d recently packed a copy of the Mira Fortran Compiler away in his loft and was blissfully unaware of the fact that he was sitting on a missing piece of microcomputing history!
He was right! He did have it in the attic…and members of the community considered it valuable.

As Barry mentioned in his tweet, converting a 40 year old cassette to an archivable .tzx format is a process that could result in permanent failure. The attempt on side 1 of the cassette didn’t work but fortunately, side 2 is where the action was!
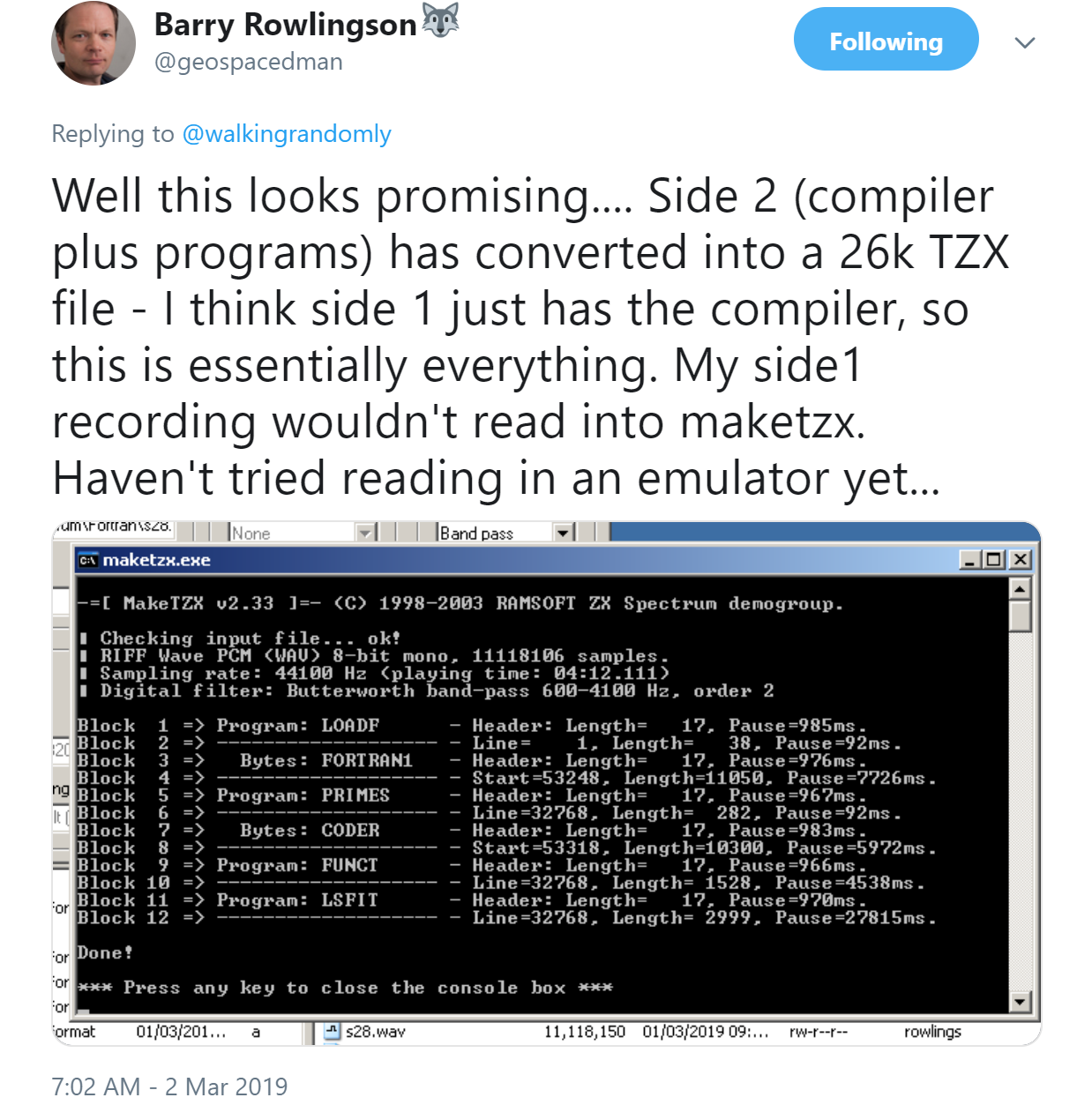
It turns out that everything worked perfectly. On loading it into a Spectrum emulator, Barry could enter and compile Fortran on this platform for the first time in decades! Here is the source code for a program that computes prime numbers

Here it is running

and here we have Barry giving the sales pitch on the advanced functionality of this compiler :)

How to get the compiler
Barry has made the compiler, and scans of the documentation, available at https://gitlab.com/b-rowlingson/mirafortran
I recently wrote a blog post for my new employer, The Numerical Algorithms Group, called Exploiting Matrix Structure in the solution of linear systems. It’s a demonstration that shows how choosing the right specialist solver for your problem rather than using a general purpose one can lead to a speed up of well over 100 times! The example is written in Python but the NAG routines used can be called from a range of languages including C,C++, Fortran, MATLAB etc etc
My friends over at the University of Sheffield Research Software Engineering group are running a GPU Hackathon sponsored by Nvidia. The event will be on August 19-23 2019 in Sheffield, United Kingdom. The call for proposals is at http://gpuhack.shef.ac.uk/
The Sheffield team have this to say about the event:
We are looking for teams of 3-5 developers with a scalable** application to port to or optimize on a GPU accelerator. Collectively the team must have complete knowledge of the application. If the application is a suite of apps, no more than two per team will be allowed and a minimum of 2 people per app must attend. Space will be limited to 8 teams.
** By scalable we mean node-to-node communication implemented, but don’t be discouraged from applying if your application is less than scalable. We are also looking for breadth of application areas.
The goal of the GPU hackathon is for current or prospective user groups of large hybrid CPU-GPU systems to send teams of at least 3 developers along with either:
- (potentially) scalable application that could benefit from GPU accelerators, or
- An application running on accelerators that needs optimization.
There will be intensive mentoring during this 5-day hands-on workshop, with the goal that the teams leave with applications running on GPUs, or at least with a clear roadmap of how to get there.