
Archive for the ‘Scientific Software’ Category
I recently had the opportunity to appear on Jousef Murad’s podcast Deep Dive. My appearance was sponsored by my employer, MathWorks, but I was given free reign to talk about pretty much whatever I wanted. So I chose to talk about Research Software Engineering and the techniques from software engineering that I think every scientist and engineer should employ (e.g. Version Control!). MATLAB and MathWorks is mentioned a bit but the aim of the podcast was that it would be of interest to anyone who has to do technical computing in any programming language.
Check it out and let me know what you think.
Feel free to discuss and contribute to this article over at the corresponding GitHub repo.
Many people suggest that you should use version control as part of your scientifc workflow. This is usually quickly followed up by recommendations to learn git and to put your project on GitHub. Learning and doing all of this for the first time takes a lot of effort. Alongside all of the recommendations to learn these technologies are horror stories telling how difficult it can be and memes saying that no one really knows what they are doing!

There are a lot of reasons to not embrace the git but there are even more to go ahead and do it. This is an attempt to convince you that it’s all going to be worth it alongside a bunch of resources that make it easy to get started and academic papers discussing the issues that version control can help resolve.
This document will not address how to do version control but will instead try to answer the questions what you can do with it and why you should bother. It was inspired by a conversation on twitter.
Improvements to individual workflow
Ways that git and GitHub can help your personal computational workflow – even if your project is just one or two files and you are the only person working on it.
Fixing filename hell
Is this a familiar sight in your working directory?
mycode.py
mycode_jane.py
mycode_ver1b.py
mycode_ver1c.py
mycode_ver1b_january.py
mycode_ver1b_january_BROKEN.py
mycode_ver1b_january_FIXED.py
mycode_ver1b_january_FIXED_for_supervisor.pyFor many people, this is just the beginning. For a project that has existed long enough there might be dozens or even hundreds of these simple scripts that somehow define all of part of your computational workflow. Version control isn’t being used because ‘The code is just a simple script developed by one person’ and yet this situation is already becoming the breeding ground for future problems.
- Which one of these files is the most up to date?
- Which one produced the results in your latest paper or report?
- Which one contains the new work that will lead to your next paper?
- Which ones contain deep flaws that should never be used as part of the research?
- Which ones contain possibly useful ideas that have since been removed from the most recent version?
Applying version control to this situation would lead you to a folder containing just one file
mycode.pyAll of the other versions will still be available via the commit history. Nothing is ever lost and you’ll be able to effectively go back in time to any version of mycode.py you like.

A single point of truth
I’ve even seen folders like the one above passed down generations of PhD students like some sort of family heirloom. I’ve seen labs where multple such folders exist across a dozen machines, each one with a mixture of duplicated and unique files. That is, not only is there a confusing mess of files in a folder but there is a confusing mess of these folders!
This can even be true when only one person is working on a project. Perhaps you have one version of your folder on your University HPC cluster, one on your home laptop and one on your work machine. Perhaps you email zipped versions to yourself from time to time. There are many everyday events that can lead to this state of affairs.
By using a GitHub repository you have a single point of truth for your project. The latest version is there. All old versions are there. All discussion about it is there.
Everything…one place.
The power of this simple idea cannot be overstated. Whenever you (or anyone else) wants to use or continue working on your project, it is always obvious where to go. Never again will you waste several days work only to realise that you weren’t working on the latest version.
Keeping track of everything that changed
The latest version of your analysis or simulation is different from the previous one. Thanks to this, it may now give different results today compared to yesterday. Version control allows you to keep track of everything that changed between two versions. Every line of code you added, deleted or changed is highlighted. Combined with your commit messages where you explain why you made each set of changes, this forms a useful record of the evolution of your project.
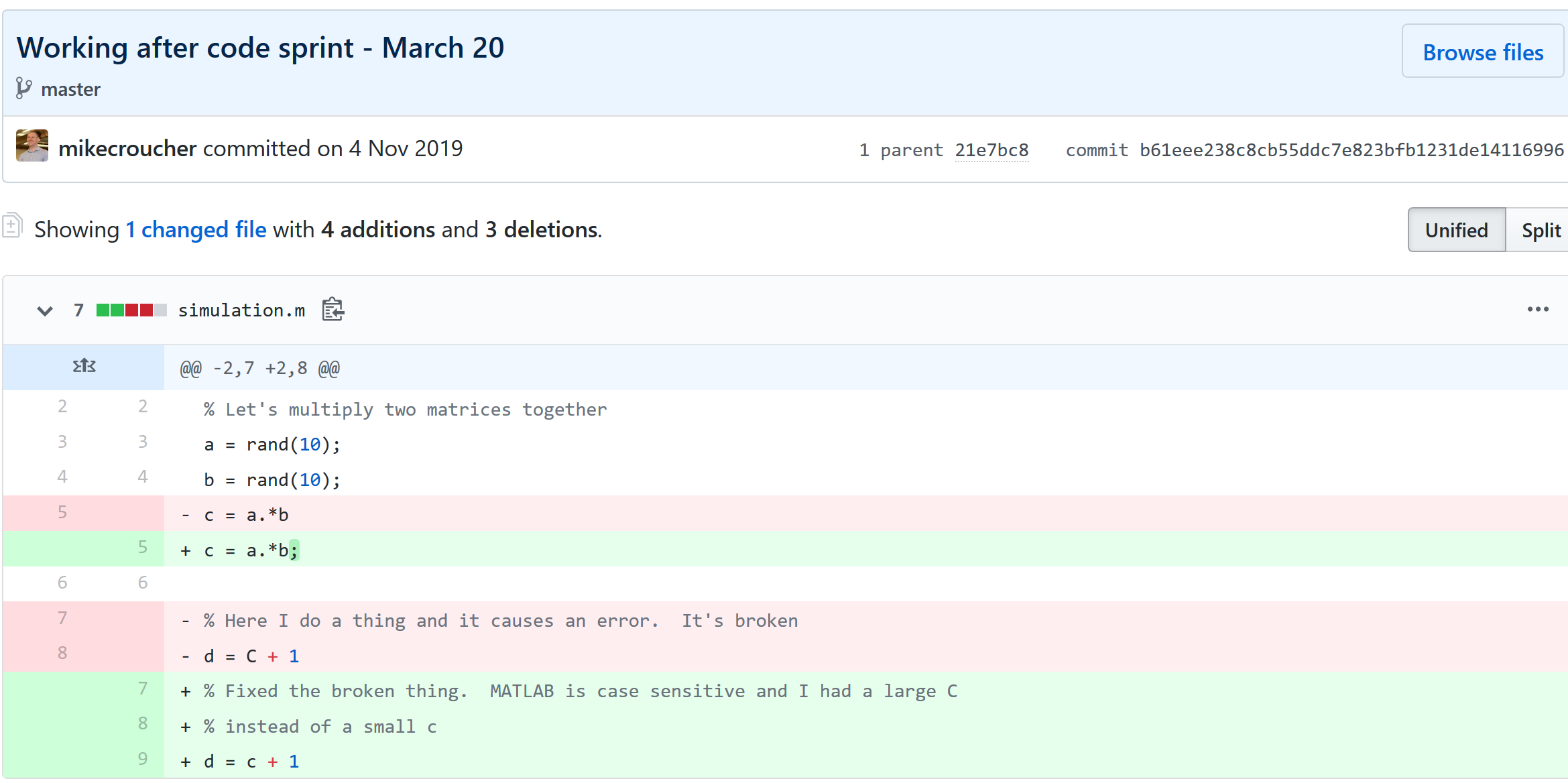
It is possible to compare the differences between any two commits, not just two consecutive ones which allows you to track the evolution of your project over time.
Always having a working version of your project
Ever noticed how your collaborator turns up unnanounced just as you are in the middle of hacking on your code. They want you to show them your simulation running but right now its broken! You frantically try some of the other files in your folder but none of them seem to be the version that was working last week when you sent the report that moved your collaborator to come to see you.
If you were using version control you could easily stash your current work, revert to the last good commit and show off your work.
Tracking down what went wrong
You are always changing that script and you test it as much as you can but the fact is that the version from last year is giving correct results in some edge case while your current version is not. There are 100 versions between the two and there’s a lot of code in each version! When did this edge case start to go wrong?
With git you can use git bisect to help you track down which commit started causing the problem which is the first step towards fixing it.

Providing a back up of your project
Try this thought experiment: Your laptop/PC has gone! Fire, theft, dead hard disk or crazed panda attack.

It, and all of it’s contents have vanished forever. How do you feel? What’s running through your mind? If you feel the icy cold fingers of dread crawling up your spine as you realise Everything related to my PhD/project/life’s work is lost then you have made bad life choices. In particular, you made a terrible choice when you neglected to take back ups.
Of course there are many ways to back up a project but if you are using the standard version control workflow, your code is automatically backed up as a matter of course. You don’t have to remember to back things up, back-ups happen as a natural result of your everyday way of doing things.
Making your project easier to find and install
There are dozens of ways to distribute your software to someone else. You could (HORRORS!) email the latest version to a colleuage or you could have a .zip file on your web site and so on.
Each of these methods has a small cognitive load for both recipient and sender. You need to make sure that you remember to update that .zip file on your website and your user needs to find it. I don’t want to talk about the email case, it makes me too sad. If you and your collaborator are emailing code to each other, please stop. Think of the children!

One great thing about using GitHub is that it is a standardised way of obtaining software. When someone asks for your code, you send them the URL of the repo. Assuming that the world is a better place and everyone knows how to use git, you don’t need to do anything else since the repo URL is all they need to get your code. a git clone later and they are in business.
Additionally, you don’t need to worry abut remembering to turn your working directory into a .zip file and uploading it to your website. The code is naturally available for download as part of the standard workflow. No extra thought needed!
In addition to this, some popular computational environments now allow you to install packages directly from GitHub. If, for example, you are following standard good practice for building an R package then a user can install it directly from your GitHub repo from within R using the devtools::install_github() function.
Automatically run all of your tests
You’ve sipped of the KoolAid and you’ve been writing unit tests like a pro. GitHub allows you to link your repo with something called Continuous Integration (CI) that helps maximise the utility of those tests.
Once its all set up the CI service runs every time you, or anyone else, makes a commit to your project. Every time the CI service runs, a virtual machine is created from scratch, your project is installed into it and all of your tests are run with any failures reported.
This gives you increased confidence that everything is OK with your latest version and you can choose to only accept commits that do not break your testing framework.
Collaboration and Community
How git and GitHub can make it easier to collaborate with others on computational projects.
Control exactly who can see your work
‘I don’t want to use GitHub because I want to keep my project private’ is a common reason given to me for not using the service. The ability to create private repositories has been free for some time now (Price plans are available here https://github.com/pricing) and you can have up to 3 collaborators on any of your private repos before you need to start paying. This is probably enough for most small academic projects.
This means that you can control exactly who sees your code. In the early stages it can be just you. At some point you let a couple of trusted collaborators in and when the time is right you can make the repo public so everyone can enjoy and use your work alongside the paper(s) it supports.
Faciliate discussion about your work
Every GitHub repo comes with an Issues section which is effectively a discussion forum for the project. You can use it to keep track of your project To-Do list, bugs, documentation discussions and so on. The issues log can also be integrated with your commit history. This allows you to do things like git commit -m "Improve the foo algorithm according to the discussion in #34" where #34 refers to the Issue discussion where your collaborator pointed out
Allow others to contribute to your work
You have absolute control over external contributions! No one can make any modifications to your project without your explicit say-so.
I start with the above statement because I’ve found that when explaining how easy it is to collaborate on GitHub, the first question is almost always ‘How do I keep control of all of this?’
What happens is that anyone can ‘fork’ your project into their account. That is, they have an independent copy of your work that is clearly linked back to your original. They can happily work away on their copy as much as they like – with no involvement from you. If and when they want to suggest that some of their modifications should go into your original version, they make a ‘Pull Request’.
I emphasised the word ‘Request’ because that’s exactly what it is. You can completely ignore it if you want and your project will remain unchanged. Alternatively you might choose to discuss it with the contributor and make modifications of your own before accepting it. At the other end of the spectrum you might simply say ‘looks cool’ and accept it immediately.
Congratulations, you’ve just found a contributing collaborator.
Reproducible research
How git and GitHub can contribute to improved reproducible research.
Simply making your software available
A paper published without the supporting software and data is (much!) harder to reproduce than one that has both.
Making your software citable
Most modern research cannot be done without some software element. Even if all you did was run a simple statistical test on 20 small samples, your paper has a data and software dependency. Organisations such as the Software Sustainability Institute and the UK Research Software Engineering Association (among many others) have been arguing for many years that such software and data dependencies should be part of the scholarly record alongside the papers that discuss them. That is, they should be archived and referenced with a permanent Digital Object Identifier (DOI).
Once your code is in GitHub, it is straightforward to archive the version that goes with your latest paper and get it its own DOI using services such as Zenodo. Your University may also have its own archival system. For example, The University of Sheffield in the UK has built a system called ORDA which is based on an institutional Figshare instance which allows Sheffield academics to deposit code and data for long term archival.
Which version gave these results?
Anyone who has worked with software long enough knows that simply stating the name of the software you used is often insufficient to ensure that someone else could reproduce your results. To help improve the odds, you should state exactly which version of the software you used and one way to do this is to refer to the git commit hash. Alternatively, you could go one step better and make a GitHub release of the version of your project used for your latest paper, get it a DOI and cite it.
This doesn’t guarentee reproducibility but its a step in the right direction. For extra points, you may consider making the computational environment reproducible too (e.g. all of the dependencies used by your script – Python modules, R packages and so on) using technologies such as Docker, Conda and MRAN but further discussion of these is out of scope for this article.
Building a computational environment based on your repository
Once your project is on GitHub, it is possible to integrate it with many other online services. One such service is mybinder which allows the generation of an executable environment based on the contents of your repository. This makes your code immediately reproducible by anyone, anywhere.
Similar projects are popping up elsewhere such as The Littlest JupyterHub deploy to Azure button which allows you to add a button to your GitHub repo that, when pressed by a user, builds a server in their Azure cloud account complete with your code and a computational environment specified by you along with a JupterHub instance that allows them to run Jupyter notebooks. This allows you to write interactive papers based on your software and data that can be used by anyone.
Complying with funding and journal guidelines
When I started teaching and advocating the use of technologies such as git I used to make a prediction These practices are so obviously good for computational research that they will one day be mandated by journal editors and funding providers. As such, you may as well get ahead of the curve and start using them now before the day comes when your funding is cut off because you don’t. The resulting debate was usually good fun.
My prediction is yet to come true across the board but it is increasingly becoming the case where eyebrows are raised when papers that rely on software are published don’t come with the supporting software and data. Research Software Engineers (RSEs) are increasingly being added to funding review panels and they may be Reviewer 2 for your latest paper submission.
Other uses of git and GitHub for busy academics
It’s not just about code…..
- Build your own websites using GitHub pasges. Every repo can have its own website served directly from GitHub
- Put your presentations on GitHub. I use reveal.js combined with GitHub pages to build and serve my presentations. That way, whenever I turn up at an event to speak I can use whatever computer is plugged into the projector. No more ‘I don’t have the right adaptor’ hell for me.
- Write your next grant proposal. Use Markdown, LaTex or some other git-friendly text format and use git and GitHub to collaboratively write your next grant proposal
The movie below is a visualisation showing how a large H2020 grant proposal called OpenDreamKit was built on GitHub. Can you guess when the deadline was based on the activity?
Further Resources
Further discussions from scientific computing practitioners that discuss using version control as part of a healthy approach to scientific computing
- Good Enough Practices in Scientific Computing –
- Is Your Research Software Correct? – A presentation from Mike Croucher discussing what can go wrong in computational research and what practices can be adopted to do help us do better
- The Turing Way A handbook of good practice in data science brought to you from the Alan Turning Institute
- A guide to reproducible code in ecology and evolution – A handbook from the British Ecological Society that discusses version control as part of general good practice
Learning version control
Convinced? Want to start learning? Let’s begin!
- Git lesson from Software Carpentry – A free, community written tutorial on the basics of git version control
Graphical User Interfaces to git
If you prefer not to use the command line, try these
My stepchildren are pretty good at mathematics for their age and have recently learned about Pythagora’s theorem
$c=\sqrt{a^2+b^2}$
The fact that they have learned about this so early in their mathematical lives is testament to its importance. Pythagoras is everywhere in computational science and it may well be the case that you’ll need to compute the hypotenuse to a triangle some day.
Fortunately for you, this important computation is implemented in every computational environment I can think of!
It’s almost always called hypot so it will be easy to find.
Here it is in action using Python’s numpy module
import numpy as np a = 3 b = 4 np.hypot(3,4) 5
When I’m out and about giving talks and tutorials about Research Software Engineering, High Performance Computing and so on, I often get the chance to mention the hypot function and it turns out that fewer people know about this routine than you might expect.
Trivial Calculation? Do it Yourself!
Such a trivial calculation, so easy to code up yourself! Here’s a one-line implementation
def mike_hypot(a,b):
return(np.sqrt(a*a+b*b))
In use it looks fine
mike_hypot(3,4) 5.0
Overflow and Underflow
I could probably work for quite some time before I found that my implementation was flawed in several places. Here’s one
mike_hypot(1e154,1e154) inf
You would, of course, expect the result to be large but not infinity. Numpy doesn’t have this problem
np.hypot(1e154,1e154) 1.414213562373095e+154
My function also doesn’t do well when things are small.
a = mike_hypot(1e-200,1e-200) 0.0
but again, the more carefully implemented hypot function in numpy does fine.
np.hypot(1e-200,1e-200) 1.414213562373095e-200
Standards Compliance
Next up — standards compliance. It turns out that there is a an official standard for how hypot implementations should behave in certain edge cases. The IEEE-754 standard for floating point arithmetic has something to say about how any implementation of hypot handles NaNs (Not a Number) and inf (Infinity).
It states that any implementation of hypot should behave as follows (Here’s a human readable summary https://www.agner.org/optimize/nan_propagation.pdf)
hypot(nan,inf) = hypot(inf,nan) = inf
numpy behaves well!
np.hypot(np.nan,np.inf) inf np.hypot(np.inf,np.nan) inf
My implementation does not
mike_hypot(np.inf,np.nan) nan
So in summary, my implementation is
- Wrong for very large numbers
- Wrong for very small numbers
- Not standards compliant
That’s a lot of mistakes for one line of code! Of course, we can do better with a small number of extra lines of code as John D Cook demonstrates in the blog post What’s so hard about finding a hypotenuse?
Hypot implementations in production
Production versions of the hypot function, however, are much more complex than you might imagine. The source code for the implementation used in openlibm (used by Julia for example) was 132 lines long last time I checked. Here’s a screenshot of part of the implementation I saw for prosterity. At the time of writing the code is at https://github.com/JuliaMath/openlibm/blob/master/src/e_hypot.c

That’s what bullet-proof, bug checked, has been compiled on every platform you can imagine and survived code looks like.
There’s more!
Active Research
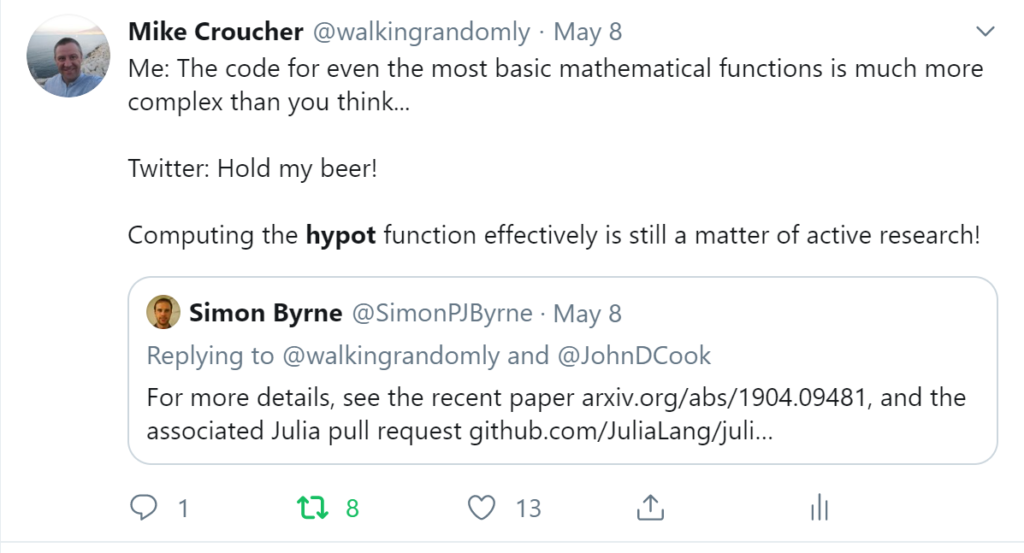
When I learned how complex production versions of hypot could be, I shouted out about it on twitter and learned that the story of hypot was far from over!
The implementation of the hypot function is still a matter of active research! See the paper here https://arxiv.org/abs/1904.09481
Is Your Research Software Correct?
Given that such a ‘simple’ computation is so complicated to implement well, consider your own code and ask Is Your Research Software Correct?.
In many introductions to numpy, one gets taught about np.ones, np.zeros and np.empty. The accepted wisdom is that np.empty will be faster than np.ones because it doesn’t have to waste time doing all that initialisation. A quick test in a Jupyter notebook shows that this seems to be true!
import numpy as np
N = 200
zero_time = %timeit -o some_zeros = np.zeros((N,N))
empty_time = %timeit -o empty_matrix = np.empty((N,N))
print('np.empty is {0} times faster than np.zeros'.format(zero_time.average/empty_time.average))
8.34 µs ± 202 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
436 ns ± 10.6 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
np.empty is 19.140587654682545 times faster than np.zeros
20 times faster may well be useful in production when using really big matrices. Might even be worth the risk of dealing with uninitialised variables even though they are scary!
However…..on my machine (Windows 10, Microsoft Surface Book 2 with 16Gb RAM), we see the following behaviour with a larger matrix size (1000 x 1000).
import numpy as np
N = 1000
zero_time = %timeit -o some_zeros = np.zeros((N,N))
empty_time = %timeit -o empty_matrix = np.empty((N,N))
print('np.empty is {0} times faster than np.zeros'.format(zero_time.average/empty_time.average))
113 µs ± 2.97 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
112 µs ± 1.01 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
np.empty is 1.0094651980894993 times faster than np.zeros
The speed-up has vanished! A subsequent discussion on twitter suggests that this is probably because the operating system is zeroing all of the memory for security reasons when using numpy.empty on large arrays.
In a recent blog post, Daniel Lemire explicitly demonstrated that vectorising random number generators using SIMD instructions could give useful speed-ups. This reminded me of the one of the first times I played with the Julia language where I learned that Julia’s random number generator used a SIMD-accelerated implementation of Mersenne Twister called dSFMT to generate random numbers much faster than MATLAB’s Mersenne Twister implementation.
Just recently, I learned that MATLAB now has its own SIMD accelerated version of Mersenne Twister which can be activated like so:
seed=1; rng(seed,'simdTwister')
This new Mersenne Twister implementation gives different random variates to the original implementation (which I demonstrated is the same as Numpy’s implementation in an older post) as you might expect
>> rng(1,'Twister') >> rand(1,5) ans = 0.4170 0.7203 0.0001 0.3023 0.1468 >> rng(1,'simdTwister') >> rand(1,5) ans = 0.1194 0.9124 0.5032 0.8713 0.5324
So it’s clearly a different algorithm and, on CPUs that support the relevant instructions, it’s about twice as fast! Using my very unscientific test code:
format compact
number_of_randoms = 10000000
disp('Timing standard twister')
rng(1,'Twister')
tic;rand(1,number_of_randoms);toc
disp('Timing SIMD twister')
rng(1,'simdTwister')
tic;rand(1,number_of_randoms);toc
gives the following results for a typical run on my Dell XPS 15 9560 which supports AVX instructions
number_of_randoms =
10000000
Timing standard twister
Elapsed time is 0.101307 seconds.
Timing SIMD twister
Elapsed time is 0.057441 seconds
The MATLAB documentation does not tell us which algorithm their implementation is based on but it seems to be different from Julia’s. In Julia, if we set the seed to 1 as we did for MATLAB and ask for 5 random numbers, we get something different from MATLAB:
julia> using Random
julia> Random.seed!(1);
julia> rand(1,5)
1×5 Array{Float64,2}:
0.236033 0.346517 0.312707 0.00790928 0.48861
The performance of MATLAB’s new generator is on-par with Julia’s although I’ll repeat that these timing tests are far far from rigorous.
julia> Random.seed!(1); julia> @time rand(1,10000000); 0.052981 seconds (6 allocations: 76.294 MiB, 29.40% gc time)
Audiences can be brutal
I still have nightmares about the first talk I ever gave as a PhD student. I was not a strong presenter, my grasp of the subject matter was still very tenuous and I was as nervous as hell. Six months or so into my studentship, I was to give a survey of the field I was studying to a bunch of very experienced researchers. I spent weeks preparing…practicing…honing my slides…hoping that it would all be good enough.
The audience was not kind to me! Even though it was only a small group of around 12 people, they were brutal! I felt like they leaped upon every mistake I made, relished in pointing out every misunderstanding I had and all-round gave me a very hard time. I had nothing like the robustness I have now and very nearly quit my PhD the very next day. I can only thank my office mates and enough beer to kill a pony for collectively talking me out of quitting.
I remember stopping three quarters of the way through saying ‘That’s all I want to say on the subject’ only for one of the senior members of the audience to point out that ‘You have not talked about all the topics you promised’. He made me go back to the slide that said something like ‘Things I will talk about’ or ‘Agenda’ or whatever else I called the stupid thing and say ‘Look….you’ve not mentioned points X,Y and Z’ [1].
Everyone agreed and so my torture continued for another 15 minutes or so.
Practice makes you tougher
Since that horrible day, I have given hundreds of talks to audiences that range in size from 5 up to 300+ and this amount of practice has very much changed how I view these events. I always enjoy them…always! Even when they go badly!
In the worst case scenario, the most that can happen is that I get given a mildly bad time for an hour or so of my life but I know I’ll get over it. I’ve gotten over it before. No big deal! Academic presentations on topics such as research computing rarely lead to life threatening outcomes.
But what if it was recorded?!
Anyone who has worked with me for an appreciable amount of time will know of my pathological fear of having one of my talks recorded. Point a camera at me and the confident, experienced speaker vanishes and is replaced by someone much closer to the terrified PhD student of my youth.
I struggle to put into words what I’m so afraid of but I wonder if it ultimately comes down to the fact that if that PhD talk had been recorded and put online, I would never have been able to get away from it. My humiliation would be there for all to see…forever.
JuliaCon 2018 and Rise of the Research Software Engineer
When the organizers of JuliaCon 2018 invited me to be a keynote speaker on the topic of Research Software Engineering, my answer was an enthusiastic ‘Yes’. As soon as I learned that they would be live streaming and recording all talks, however, my enthusiasm was greatly dampened.
‘Would you mind if my talk wasn’t live streamed and recorded’ I asked them. ‘Sure, no problem’ was the answer….
Problem averted. No need to face my fears this week!
A fellow delegate of the conference pointed out to me that my talk would be the only one that wouldn’t be on the live stream. That would look weird and not in a good way.
‘Can I just be live streamed but not recorded’ I asked the organisers. ‘Sure, no problem’ [2] was the reply….
Later on the technician told me that I could have it recorded but it would be instantly hidden from the world until I had watched it and agreed it wasn’t too terrible. Maybe this would be a nice first step in my record-a-talk-a-phobia therapy he suggested.
So…on I went and it turned out not to be as terrible as I had imagined it might be. So we published it. I learned that I say ‘err’ and ‘um’ a lot [3] which I find a little embarrassing but perhaps now that I know I have that problem, it’s something I can work on.
Rise of the Research Software Engineer
Anyway, here’s the video of the talk. It’s about some of the history of The Research Software Engineering movement and how I worked with some awesome people at The University of Sheffield to create a RSE group. If you are the computer-person in your research group who likes software more than papers, you may be one of us. Come join the tribe!
Slide deck at mikecroucher.github.io/juliacon2018/
Feel free to talk to me on twitter about it: @walkingrandomly
Thanks to the infinitely patient and wonderful organisers of JuliaCon 2018 for the opportunity to beat one of my long standing fears.
Footnotes
[1] Pro-Tip: Never do one of these ‘Agenda’ slides…give yourself leeway to alter the course of your presentation midway through depending on how well it is going.
[2] So patient! Such a lovely team!
[3] Like A LOT! My mum watched the video and said ‘No idea what you were talking about but OMG can you cut out the ummms and ahhs’
I’m working on optimising some R code written by a researcher at University of Sheffield and its very much a war of attrition! There’s no easily optimisable hotspot and there’s no obvious way to leverage parallelism. Progress is being made by steadily identifying places here and there where we can do a little better. 10% here and 20% there can eventually add up to something worth shouting about.
One such micro-optimisation we discovered involved multiplying two matrices together where one of them needed to be transposed. Here’s a minimal example.
#Set random seed for reproducibility set.seed(3) # Generate two random n by n matrices n = 10 a = matrix(runif(n*n,0,1),n,n) b = matrix(runif(n*n,0,1),n,n) # Multiply the matrix a by the transpose of b c = a %*% t(b)
When the speed of linear algebra computations are an issue in R, it makes sense to use a version that is linked to a fast implementation of BLAS and LAPACK and we are already doing that on our HPC system.
Here, I am using version 3.3.3 of Microsoft R Open which links to Intel’s MKL (an implementation of BLAS and LAPACK) on a Windows laptop.
In R, there is another way to do the computation c = a %*% t(b) — we can make use of the tcrossprod function (There is also a crossprod function for when you want to do t(a) %*% b)
c_new = tcrossprod(a,b)
Let’s check for equality
c_new == c [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [1,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [2,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [3,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [4,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [5,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [6,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [7,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [8,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [9,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [10,] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
Sometimes, when comparing the two methods you may find that some of those entries are FALSE which may worry you!
If that happens, computing the difference between the two results should convince you that all is OK and that the differences are just because of numerical noise. This happens sometimes when dealing with floating point arithmetic (For example, see https://www.walkingrandomly.com/?p=5380).
Let’s time the two methods using the microbenchmark package.
install.packages('microbenchmark')
library(microbenchmark)
We time just the matrix multiplication part of the code above:
microbenchmark( original = a %*% t(b), tcrossprod = tcrossprod(a,b) ) Unit: nanoseconds expr min lq mean median uq max neval original 2918 3283 3491.312 3283 3647 18599 1000 tcrossprod 365 730 756.278 730 730 10576 1000
We are only saving microseconds here but that’s more than a factor of 4 speed-up in this small matrix case. If that computation is being performed a lot in a tight loop (and for our real application, it was), it can add up to quite a difference.
As the matrices get bigger, the speed-benefit in percentage terms gets lower but tcrossprod always seems to be the faster method. For example, here are the results for 1000 x 1000 matrices
#Set random seed for reproducibility set.seed(3) # Generate two random n by n matrices n = 1000 a = matrix(runif(n*n,0,1),n,n) b = matrix(runif(n*n,0,1),n,n) microbenchmark( original = a %*% t(b), tcrossprod = tcrossprod(a,b) ) Unit: milliseconds expr min lq mean median uq max neval original 18.93015 26.65027 31.55521 29.17599 31.90593 71.95318 100 tcrossprod 13.27372 18.76386 24.12531 21.68015 23.71739 61.65373 100
The cost of not using an optimised version of BLAS and LAPACK
While writing this blog post, I accidentally used the CRAN version of R. The recently released version 3.4. Unlike Microsoft R Open, this is not linked to the Intel MKL and so matrix multiplication is rather slower.
For our original 10 x 10 matrix example we have:
library(microbenchmark)
#Set random seed for reproducibility
set.seed(3)
# Generate two random n by n matrices
n = 10
a = matrix(runif(n*n,0,1),n,n)
b = matrix(runif(n*n,0,1),n,n)
microbenchmark(
original = a %*% t(b),
tcrossprod = tcrossprod(a,b)
)
Unit: microseconds
expr min lq mean median uq max neval
original 3.647 3.648 4.22727 4.012 4.1945 22.611 100
tcrossprod 1.094 1.459 1.52494 1.459 1.4600 3.282 100
Everything is a little slower as you might expect and the conclusion of this article — tcrossprod(a,b) is faster than a %*% t(b) — seems to still be valid.
However, when we move to 1000 x 1000 matrices, this changes
library(microbenchmark)
#Set random seed for reproducibility
set.seed(3)
# Generate two random n by n matrices
n = 1000
a = matrix(runif(n*n,0,1),n,n)
b = matrix(runif(n*n,0,1),n,n)
microbenchmark(
original = a %*% t(b),
tcrossprod = tcrossprod(a,b)
)
Unit: milliseconds
expr min lq mean median uq max neval
original 546.6008 587.1680 634.7154 602.6745 658.2387 957.5995 100
tcrossprod 560.4784 614.9787 658.3069 634.7664 685.8005 1013.2289 100
As expected, both results are much slower than when using the Intel MKL-lined version of R (~600 milliseconds vs ~31 milliseconds) — nothing new there. More disappointingly, however, is that now tcrossprod is slightly slower than explicitly taking the transpose.
As such, this particular micro-optimisation might not be as effective as we might like for all versions of R.
UK to launch 6 major HPC centres
Tomorrow, I’ll be attending the launch event for the UK’s new HPC centres and have been asked to deliver a short talk as part of the program. As someone who paddles in the shallow-end of the HPC pool I find this both flattering and more than a little terrifying. What can little-ole-me say to the national HPC glitterati that might be useful?
This blog post is an attempt at gathering my thoughts together for that talk.
The technology gap in research computing
Broadly speaking, my role in academia is to hang out with researchers, compute providers (cloud and HPC) and software vendors in an attempt to be vaguely useful in the area of research software. I’m a Research Software Engineer with a focus on Long Tail Science: The large number of very small research groups who do a huge amount of modern research.
Time and again, what I see can be summarized in this quote by Greg Wilson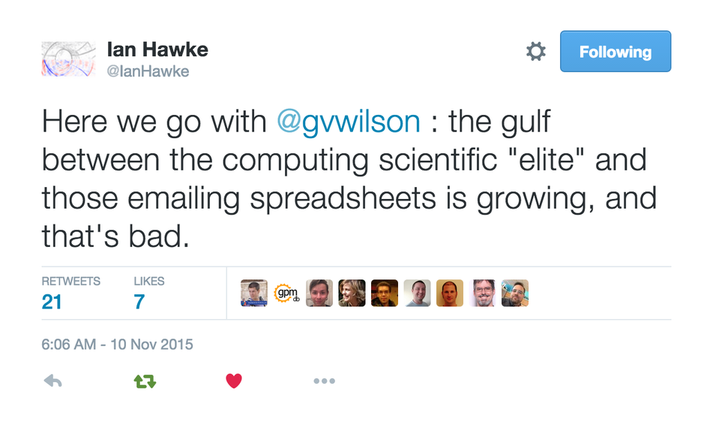
This is very true in the world of High Performance Computing.
Geek Top Gear
I love technology and I love HPC in particular. I love to geek out on Flops, Ghz, SIMD instructions, GPUs, FPGAs…..all that stuff. I help support The University of Sheffield’s local HPC service and worked in Research IT at The University of Manchester for around a decade before moving to Sheffield.
I’ve given and seen many a HPC-related talk in my time and have certainly been guilty of delivering what I now refer to as the ‘Geek Top Gear’ speech. For maximum effect, you need to do it in a Jeremy Clarkson voice and, if you’re feeling really macho, kiss your bicep at the point where you tell the audience how many Petaflops your system can do in Linpack.
*Begin Jeremy Clarkson Impression*
Our new HPC system has got 100,000 of the latest Intel Kaby Lake cores...which is a lot!
Usually running at 2.6Ghz, these cores can turbo-boost to 3.2Ghz for those moments when we need that extra boost of power. Obviously, being Kaby Lake, these cores have all the instruction extensions you’d expect with AVX2, FMA, SSE, ABM and many many other TLAs for all your SIMD needs. Of course every HPC system needs accelerators…..and we have the best of them: Xeon Phis with 68 cores each and NVIDIA GPUs with thousands of tiny little cores will handle every massively parallel job you can throw at them….Easily. We connect these many many cores together with high-speed interconnect fashioned from threads of pure unicorn hair and cool the whole thing with the tears of virigin nerds.
YEEEEEES! Our new HPC system is the best one since the last one and, achieving over a Gajillion Petaflops in the Linpack test (kiss bicep), it will change your life forever.

Any questions?
Audience member 1: What’s a core?
Audience member 2: Why does it run my R script slower than my laptop?
Audience member 3: Do you have Excel installed on it?
There is a huge gap between what many HPC providers like to focus on and what the typical long-tail researcher wants or needs. I propose that the best bridge for this gap is the Research Software Engineer (RSE).
Research Software Engineer as Alpine guide
In my fellowship proposal, I compared the role of a Research Software Engineer to that of an alpine guide:
Technological development in software is more like a cliff-face than a ladder – there are many routes to the top, to a solution. Further, the cliff face is dynamic – constantly and quickly changing as new technologies emerge and decline. Determining which technologies to deploy and how best to deploy them is in itself a specialist domain, with many features of traditional research.
Researchers need empowerment and training to give them confidence with the available equipment and the challenges they face. This role, akin to that of an Alpine guide, involves support, guidance, and load carrying. When optimally performed it results in a researcher who knows what challenges they can attack alone, and where they need appropriate support. Guides can help decide whether to exploit well-trodden paths or explore new possibilities as they navigate through this dynamic environment.
At Sheffield, we have built a pool of these Research Software Engineers to provide exactly this kind of support and it’s working extremely well so far. Not only are we helping individual research groups but we are also using our experiences in the field to help shape the University HPC environment in collaboration with the IT department.
Supercomputing: Irrelevant to many?
“Never bring an anecdote to a data-fight” so the saying goes and all I have from my own experiences are a bucket load of anecdotes, case studies and cursory log-mining experiments that indicate that even those who DO use HPC are not doing so effectively. Fortunately, others have stepped up to the plate and we have survey and interview data on how researchers are using compute resources.
How Do Scientists Develop and Use Scientific Software? is a report on a 2009 survey of 1972 researchers from around the world. They found that “79.9% of the scientists never use scientific software on a supercomputer”
When I first learned of this number, I found it faintly depressing. This technology that I love so much and for which University IT departments dedicate special days to seems to be pretty much irrelevant to the majority of researchers. Could it be that even in an era of big data, machine learning and research software engineering that most people only need a laptop?
Only ever needing a laptop certainly doesn’t fit with what I’ve seen while working in the trenches. Almost every researcher I’ve met who does computational research wishes it was faster or that they had more memory to allow them to do larger problems. Speed is the easiest thing to sell to researchers in the world of RSE. They come for faster execution and leave with a side-order of version control, testing and documentation. A combination of software development and migration to even a small HPC system can easily result in 100x or even 1000x speed-ups for many researchers.
In my experience, it’s not that researchers don’t need HPC, it’s that the jump from their laptop-based workflow to one that makes good use of a HPC system is too large for them to bridge without a little help. Providing that help can result in some great partnerships such as the recent one between the Sheffield RSE group and the Sheffield Faculty of Arts and Humanities.

Want to know how that partnership started? I compiled an experimental R/Rcpp package that they were struggling with and then took them for coffee and said ‘That code took a while to run. Here’s how we can make it go faster….Now…what exactly are you doing because it looks cool?’ Fast forward a year or so and we are on the cusp of starting a great new project that will include traditional HPC and cloud computing as part of their R-based workflow.
My experiences seem to be reflected in the data. In their 2011 article, A Survey of the Practice of Computational Science, Prabhu et al interviewed 114 randomly selected researchers from Princeton University. Princeton have a very strong, well supported HPC centre which provides both resources and the expertise to use them. Even at such a well equipped institution, the authors write that ‘Despite enormous wait times, many scientists run their programs only on desktops’ although they did report much higher HPC usage compared to the Hanny et al survey.
Other salient quotes from the Prabhu interviews include
“only 18% of researchers who optimize code leveraged profiling tools to inform their optimization plans”
“only 7% of researchers leveraged any form of thread based shared memory CPU parallelism”
“Only 11% of researchers utilized loop based parallelism”
“Currently, many researchers fit their scientific models to only a subset of available parameters for faster program runs.”
“Across disciplines, an order of magnitude performance improvement was cited as a requirement for significant changes in research quality”
HPC: There’s plenty of room at the bottom
Potential users of HPC look different to those of 20 years ago. The popularity explosion of languages such as MATLAB, Python and R have democratized programming and the world is awash with inefficient research software. Most of the time, this lack of efficiency is not a problem (see ‘In defense of inefficient scientific code‘) but if a researcher needs to scale up what they are doing, it can become limiting. Researchers might wait for days for the results to come in and limit the scope of their investigations to fit the hardware they have access to — their laptop usually.
The paper of Prabu et al said that an order of magnitude (10x) speed up was cited by researchers as a requirement for significant changes in research quality. For an experienced Research Software Engineer with access to cloud or HPC facilities, a 10x speed-up is usually pretty easy to achieve for this new audience. 100x or even 1000x can be achieved fairly frequently if you employ multiple hardware and software techniques. Compared to squeezing out a few percent more performance from HPC-centric code such as LAPACK or CASTEP, it’s not even all that difficult. I recently sped up one researcher’s MATLAB code by a factor of 800x in a couple of days and I’m a fairly middling developer if I’m brutally honest.
The whole point of High Performance Computing is to accelerate science and right now there is more computational science around than there has ever been before. Furthermore, it’s easier than ever to accelerate! There’s plenty of room at the bottom.
Closing the computational gap with people, training and compute power
The UK’s 6 new HPC centers represent the cutting edge of hardware technology. They provide a crucial component of our national hardware infrastructure, will contribute to research in HPC itself and will doubtless be of huge benefit to computational science. Furthermore, all of the funded proposals include significant engagement with the national Research Software Engineering community – the vital bridge between many researchers and HPC.
Co-development of research software with effort from both RSEs and researchers can be an extremely powerful model. Combine this with further collaboration between RSEs and compute providers and we have an environment that I think is both very exciting and capable of helping to close the rich/poor compute divide.
As an RSE who works with both researchers and University-level HPC providers, I ask for 3 things to be considered by these new regional centres.
- Enjoy your new compute-ferraris. I look forward to seeing how hard you can push them.
- You will be learning new good practice in how to provide HPC services. Disseminate this to those of us running smaller services.
- There’s plenty of room at the bottom! Help us to support the new wave of computational researchers.
Thanks to languages such as MATLAB, Python and R, general purpose programming has been fully democratized. I look forward to working with these new centres to help democratize high performance computing.
If you are a researcher and are currently writing scripts or developing code then I have a suggestion for you. If you haven’t done it already, get yourself a willing volunteer and send them your code/analysis/simulation/voodoo and ask them to run it on their machine to see what happens. Bonus points are awarded for choosing someone who uses a different operating system from you!
This simple act is one of the things I recommend in my talk Is Your Research Software Correct and it can often help improve both code and workflow.
It quickly exposes patterns that are not good practice. For example, scattered references to ‘/home/walkingrandomly/mydata.dat’ suddenly don’t seem like a great idea when your code buddy is running windows. The ‘minimal tweaking’ required to move your analysis from your machine to theirs starts to feel a lot less minimal as you get to the bottom of the second page of instructions.
Crashy McCrashFace
When I start working with someone new, the first thing I ask them to do is to provide access to their code and simple script called runme or similar that will build and run their code and spit out an answer that we agree is OK. Many projects stumble at this hurdle! Perhaps my compiler is different to theirs and objects to their abuse (or otherwise) of the standards or maybe they’ve forgotten to include vital dependencies or input data.
Email ping-pong ensues as we attempt to get the latest version…zip files with names like PhD_code_ver1b_ForMike_withdata_fixed.zip get thrown about while everyone wonders where Bob is because he totally got it working on Windows back in 2009.
git clone
‘Hey Mike, just clone the git repo and run the test suite. It should be fine because the latest continuous integration run didn’t throw up any issues. The benchmark code and data we’d like you to optimise is in the benchmarks folder along with the timings and results from our most recent tests. Ignore the papers folder, that just reproduces all of the results from our recent papers and links to Zenodo DOIs’
‘…………’
‘Are you OK Mike?’
‘I’m…..fine. Just have something in my eye’
I work at The University of Sheffield where I am one of the leaders of the new Research Software Engineering function. One of the things that my group does is help people make use of Sheffield’s High Performance Computing cluster, Iceberg.
Iceberg is a heterogenous system with around 3440 CPU cores and a sprinkling of GPUs. It’s been in use for several years and has been upgraded a few times over that period. It’s a very traditional HPC system that makes use of Linux and a variant of Sun Grid Engine as the scheduler and had served us well.

A while ago, the sysadmin pointed me to a goldmine of a resource — Iceberg’s accounting log. This 15 Gigabyte file contains information on every job submitted since July 2009. That’s more than 7 years of the HPC usage of 3249 users — over 46 million individual jobs.
The file format is very straightforward. There’s one line per job and each line consists of a set of colon separated fields. The first few fields look like something like this:
long.q:node54.iceberg.shef.ac.uk:el:abc07de:
The username is field 4 and the number of slots used by the job is field 35. On our system, slots correspond to CPU cores. If you want to run a 16 core job, you ask for 16 slots.
With one line of awk, we can determine the maximum number of slots ever requested by each user.
gawk -F: '$35>=slots[$4] {slots[$4]=$35};END{for(n in slots){print n, slots[n]}}' accounting > ./users_max_slots.csv
As a quick check, I grepped the output file for my username and saw that the maximum number of cores I’d ever requested was 20. I ran a 32 core MPI ‘Hello World’ job, reran the line of awk and confirmed that my new maximum was 32 cores.
There are several ways I could have filtered the number of users but I was having awk lessons from David Jones so let’s create a new file containing the users who have only ever requested 1 slot.
gawk -F: '$35>=slots[$4] {slots[$4]=$35};END{for(n in slots){if(slots[n]==1){print n, slots[n]}}}' accounting > users_where_max_is_one_slot.csv
Running wc on these files allows us to determine how many users are in each group
wc users_max_slots.csv 3250 6498 32706 users_max_slots.csv
One of those users turned out to be a blank line so 3249 usernames have been used on Iceberg over the last 7 years.
wc users_where_max_is_one_slot.csv 2393 4786 23837 users_where_max_is_one_slot.csv
That is, 2393 of our 3249 users (just over 73%) over the last 7 years have only ever run 1 slot, and therefore 1 core, jobs.
High Performance?
So 73% of all users have only ever submitted single core jobs. This does not necessarily mean that they have not been making use of parallelism. For example, they might have been running job arrays – hundreds or thousands of single core jobs performing parameter sweeps or monte carlo simulations.
Maybe they were running parallel codes but only asked the scheduler for one core. In the early days this would have led to oversubscribed nodes, possibly up to 16 jobs, each trying to run 16 cores.These days, our sysadmin does some voodoo to ensure that jobs can only use the number of cores that have been requested, no matter how many threads their code is spawning. Either way, making this mistake is not great for performance.
Whatever is going on, this figure of 73% is surprising to me!
Thanks to David Jones for the awk lessons although if I’ve made a mistake, it’s all my fault!
Update (11th Jan 2017)
UCL’s Ian Kirker took a look at the usage of their general purpose cluster and found that 71.8% of their users have only ever run 1 core jobs. https://twitter.com/ikirker/status/819133966292807680