
Archive for the ‘Science’ Category
Feel free to discuss and contribute to this article over at the corresponding GitHub repo.
Many people suggest that you should use version control as part of your scientifc workflow. This is usually quickly followed up by recommendations to learn git and to put your project on GitHub. Learning and doing all of this for the first time takes a lot of effort. Alongside all of the recommendations to learn these technologies are horror stories telling how difficult it can be and memes saying that no one really knows what they are doing!

There are a lot of reasons to not embrace the git but there are even more to go ahead and do it. This is an attempt to convince you that it’s all going to be worth it alongside a bunch of resources that make it easy to get started and academic papers discussing the issues that version control can help resolve.
This document will not address how to do version control but will instead try to answer the questions what you can do with it and why you should bother. It was inspired by a conversation on twitter.
Improvements to individual workflow
Ways that git and GitHub can help your personal computational workflow – even if your project is just one or two files and you are the only person working on it.
Fixing filename hell
Is this a familiar sight in your working directory?
mycode.py
mycode_jane.py
mycode_ver1b.py
mycode_ver1c.py
mycode_ver1b_january.py
mycode_ver1b_january_BROKEN.py
mycode_ver1b_january_FIXED.py
mycode_ver1b_january_FIXED_for_supervisor.pyFor many people, this is just the beginning. For a project that has existed long enough there might be dozens or even hundreds of these simple scripts that somehow define all of part of your computational workflow. Version control isn’t being used because ‘The code is just a simple script developed by one person’ and yet this situation is already becoming the breeding ground for future problems.
- Which one of these files is the most up to date?
- Which one produced the results in your latest paper or report?
- Which one contains the new work that will lead to your next paper?
- Which ones contain deep flaws that should never be used as part of the research?
- Which ones contain possibly useful ideas that have since been removed from the most recent version?
Applying version control to this situation would lead you to a folder containing just one file
mycode.pyAll of the other versions will still be available via the commit history. Nothing is ever lost and you’ll be able to effectively go back in time to any version of mycode.py you like.

A single point of truth
I’ve even seen folders like the one above passed down generations of PhD students like some sort of family heirloom. I’ve seen labs where multple such folders exist across a dozen machines, each one with a mixture of duplicated and unique files. That is, not only is there a confusing mess of files in a folder but there is a confusing mess of these folders!
This can even be true when only one person is working on a project. Perhaps you have one version of your folder on your University HPC cluster, one on your home laptop and one on your work machine. Perhaps you email zipped versions to yourself from time to time. There are many everyday events that can lead to this state of affairs.
By using a GitHub repository you have a single point of truth for your project. The latest version is there. All old versions are there. All discussion about it is there.
Everything…one place.
The power of this simple idea cannot be overstated. Whenever you (or anyone else) wants to use or continue working on your project, it is always obvious where to go. Never again will you waste several days work only to realise that you weren’t working on the latest version.
Keeping track of everything that changed
The latest version of your analysis or simulation is different from the previous one. Thanks to this, it may now give different results today compared to yesterday. Version control allows you to keep track of everything that changed between two versions. Every line of code you added, deleted or changed is highlighted. Combined with your commit messages where you explain why you made each set of changes, this forms a useful record of the evolution of your project.
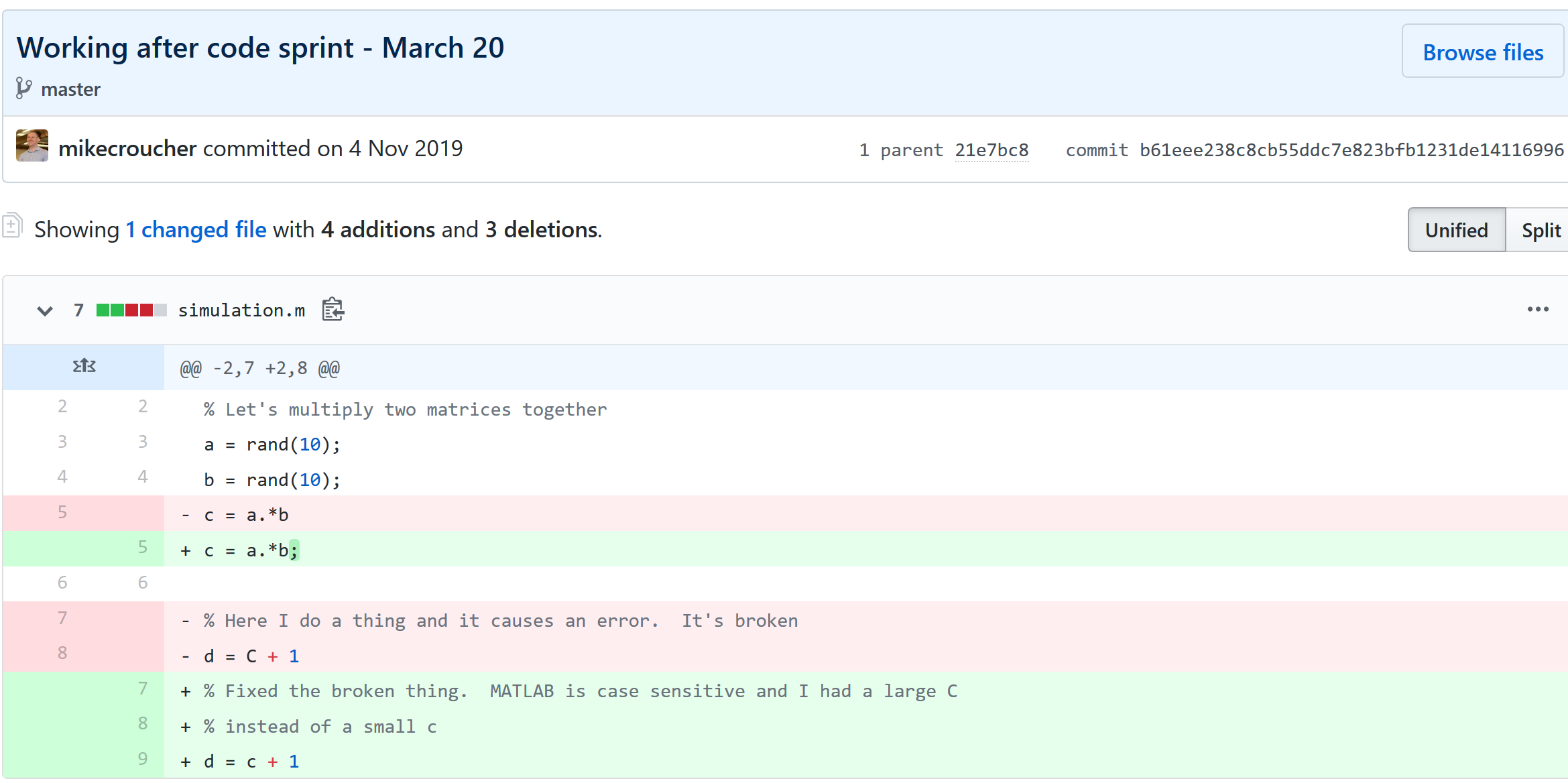
It is possible to compare the differences between any two commits, not just two consecutive ones which allows you to track the evolution of your project over time.
Always having a working version of your project
Ever noticed how your collaborator turns up unnanounced just as you are in the middle of hacking on your code. They want you to show them your simulation running but right now its broken! You frantically try some of the other files in your folder but none of them seem to be the version that was working last week when you sent the report that moved your collaborator to come to see you.
If you were using version control you could easily stash your current work, revert to the last good commit and show off your work.
Tracking down what went wrong
You are always changing that script and you test it as much as you can but the fact is that the version from last year is giving correct results in some edge case while your current version is not. There are 100 versions between the two and there’s a lot of code in each version! When did this edge case start to go wrong?
With git you can use git bisect to help you track down which commit started causing the problem which is the first step towards fixing it.

Providing a back up of your project
Try this thought experiment: Your laptop/PC has gone! Fire, theft, dead hard disk or crazed panda attack.

It, and all of it’s contents have vanished forever. How do you feel? What’s running through your mind? If you feel the icy cold fingers of dread crawling up your spine as you realise Everything related to my PhD/project/life’s work is lost then you have made bad life choices. In particular, you made a terrible choice when you neglected to take back ups.
Of course there are many ways to back up a project but if you are using the standard version control workflow, your code is automatically backed up as a matter of course. You don’t have to remember to back things up, back-ups happen as a natural result of your everyday way of doing things.
Making your project easier to find and install
There are dozens of ways to distribute your software to someone else. You could (HORRORS!) email the latest version to a colleuage or you could have a .zip file on your web site and so on.
Each of these methods has a small cognitive load for both recipient and sender. You need to make sure that you remember to update that .zip file on your website and your user needs to find it. I don’t want to talk about the email case, it makes me too sad. If you and your collaborator are emailing code to each other, please stop. Think of the children!

One great thing about using GitHub is that it is a standardised way of obtaining software. When someone asks for your code, you send them the URL of the repo. Assuming that the world is a better place and everyone knows how to use git, you don’t need to do anything else since the repo URL is all they need to get your code. a git clone later and they are in business.
Additionally, you don’t need to worry abut remembering to turn your working directory into a .zip file and uploading it to your website. The code is naturally available for download as part of the standard workflow. No extra thought needed!
In addition to this, some popular computational environments now allow you to install packages directly from GitHub. If, for example, you are following standard good practice for building an R package then a user can install it directly from your GitHub repo from within R using the devtools::install_github() function.
Automatically run all of your tests
You’ve sipped of the KoolAid and you’ve been writing unit tests like a pro. GitHub allows you to link your repo with something called Continuous Integration (CI) that helps maximise the utility of those tests.
Once its all set up the CI service runs every time you, or anyone else, makes a commit to your project. Every time the CI service runs, a virtual machine is created from scratch, your project is installed into it and all of your tests are run with any failures reported.
This gives you increased confidence that everything is OK with your latest version and you can choose to only accept commits that do not break your testing framework.
Collaboration and Community
How git and GitHub can make it easier to collaborate with others on computational projects.
Control exactly who can see your work
‘I don’t want to use GitHub because I want to keep my project private’ is a common reason given to me for not using the service. The ability to create private repositories has been free for some time now (Price plans are available here https://github.com/pricing) and you can have up to 3 collaborators on any of your private repos before you need to start paying. This is probably enough for most small academic projects.
This means that you can control exactly who sees your code. In the early stages it can be just you. At some point you let a couple of trusted collaborators in and when the time is right you can make the repo public so everyone can enjoy and use your work alongside the paper(s) it supports.
Faciliate discussion about your work
Every GitHub repo comes with an Issues section which is effectively a discussion forum for the project. You can use it to keep track of your project To-Do list, bugs, documentation discussions and so on. The issues log can also be integrated with your commit history. This allows you to do things like git commit -m "Improve the foo algorithm according to the discussion in #34" where #34 refers to the Issue discussion where your collaborator pointed out
Allow others to contribute to your work
You have absolute control over external contributions! No one can make any modifications to your project without your explicit say-so.
I start with the above statement because I’ve found that when explaining how easy it is to collaborate on GitHub, the first question is almost always ‘How do I keep control of all of this?’
What happens is that anyone can ‘fork’ your project into their account. That is, they have an independent copy of your work that is clearly linked back to your original. They can happily work away on their copy as much as they like – with no involvement from you. If and when they want to suggest that some of their modifications should go into your original version, they make a ‘Pull Request’.
I emphasised the word ‘Request’ because that’s exactly what it is. You can completely ignore it if you want and your project will remain unchanged. Alternatively you might choose to discuss it with the contributor and make modifications of your own before accepting it. At the other end of the spectrum you might simply say ‘looks cool’ and accept it immediately.
Congratulations, you’ve just found a contributing collaborator.
Reproducible research
How git and GitHub can contribute to improved reproducible research.
Simply making your software available
A paper published without the supporting software and data is (much!) harder to reproduce than one that has both.
Making your software citable
Most modern research cannot be done without some software element. Even if all you did was run a simple statistical test on 20 small samples, your paper has a data and software dependency. Organisations such as the Software Sustainability Institute and the UK Research Software Engineering Association (among many others) have been arguing for many years that such software and data dependencies should be part of the scholarly record alongside the papers that discuss them. That is, they should be archived and referenced with a permanent Digital Object Identifier (DOI).
Once your code is in GitHub, it is straightforward to archive the version that goes with your latest paper and get it its own DOI using services such as Zenodo. Your University may also have its own archival system. For example, The University of Sheffield in the UK has built a system called ORDA which is based on an institutional Figshare instance which allows Sheffield academics to deposit code and data for long term archival.
Which version gave these results?
Anyone who has worked with software long enough knows that simply stating the name of the software you used is often insufficient to ensure that someone else could reproduce your results. To help improve the odds, you should state exactly which version of the software you used and one way to do this is to refer to the git commit hash. Alternatively, you could go one step better and make a GitHub release of the version of your project used for your latest paper, get it a DOI and cite it.
This doesn’t guarentee reproducibility but its a step in the right direction. For extra points, you may consider making the computational environment reproducible too (e.g. all of the dependencies used by your script – Python modules, R packages and so on) using technologies such as Docker, Conda and MRAN but further discussion of these is out of scope for this article.
Building a computational environment based on your repository
Once your project is on GitHub, it is possible to integrate it with many other online services. One such service is mybinder which allows the generation of an executable environment based on the contents of your repository. This makes your code immediately reproducible by anyone, anywhere.
Similar projects are popping up elsewhere such as The Littlest JupyterHub deploy to Azure button which allows you to add a button to your GitHub repo that, when pressed by a user, builds a server in their Azure cloud account complete with your code and a computational environment specified by you along with a JupterHub instance that allows them to run Jupyter notebooks. This allows you to write interactive papers based on your software and data that can be used by anyone.
Complying with funding and journal guidelines
When I started teaching and advocating the use of technologies such as git I used to make a prediction These practices are so obviously good for computational research that they will one day be mandated by journal editors and funding providers. As such, you may as well get ahead of the curve and start using them now before the day comes when your funding is cut off because you don’t. The resulting debate was usually good fun.
My prediction is yet to come true across the board but it is increasingly becoming the case where eyebrows are raised when papers that rely on software are published don’t come with the supporting software and data. Research Software Engineers (RSEs) are increasingly being added to funding review panels and they may be Reviewer 2 for your latest paper submission.
Other uses of git and GitHub for busy academics
It’s not just about code…..
- Build your own websites using GitHub pasges. Every repo can have its own website served directly from GitHub
- Put your presentations on GitHub. I use reveal.js combined with GitHub pages to build and serve my presentations. That way, whenever I turn up at an event to speak I can use whatever computer is plugged into the projector. No more ‘I don’t have the right adaptor’ hell for me.
- Write your next grant proposal. Use Markdown, LaTex or some other git-friendly text format and use git and GitHub to collaboratively write your next grant proposal
The movie below is a visualisation showing how a large H2020 grant proposal called OpenDreamKit was built on GitHub. Can you guess when the deadline was based on the activity?
Further Resources
Further discussions from scientific computing practitioners that discuss using version control as part of a healthy approach to scientific computing
- Good Enough Practices in Scientific Computing –
- Is Your Research Software Correct? – A presentation from Mike Croucher discussing what can go wrong in computational research and what practices can be adopted to do help us do better
- The Turing Way A handbook of good practice in data science brought to you from the Alan Turning Institute
- A guide to reproducible code in ecology and evolution – A handbook from the British Ecological Society that discusses version control as part of general good practice
Learning version control
Convinced? Want to start learning? Let’s begin!
- Git lesson from Software Carpentry – A free, community written tutorial on the basics of git version control
Graphical User Interfaces to git
If you prefer not to use the command line, try these
One aspect of my EPSRC Research Software Engineering fellowship is to spread basic good practice in research software to different academic fields. Last year, I was invited to participate in a Reproducible research in Ecology workshop which was part of the 2016 International Society of Behavioural Ecology Conference. My contributions included a talk (your research software correct?) and a workshop on using projects and version control using R and RStudio.
The latest output from this stream of work is a paper in Behavioral Ecology called Striving for transparent and credible research: practical guidelines for behavioral ecologists which discusses various topics including preregistration, open science and, of course, research software practices with shout-outs to initiatives such as Software Carpentry, Research Software Engineering and the Software Sustainability Institute. The lead author is Malika Ihle with contributions from Isabel S Winney, Anna Krystalli and me.
One of the great things about being a Research Software Engineer is the diversity of work you can get involved with. I specialise in smaller interventions which means that I can be working with physicists on Monday, engineers on Tuesday, geneticists on Wednesday….you get the idea.
Last month, I got to work with some Ecologists along with Anna Krystalli. We undertook the arduous journey from Sheffield down to Exeter to deliver talks and workshops at a post-conference symposium on reproducibility in science, organised by Malika Ihle and Isabel Winney, at the International Symposium on Behavioural Ecology.
I gave my talk, Is your research software correct?, and also delivered a workshop on using projects and version control using R and RStudio in the Code Cafe style. For the full write up of the day, see the excellent blog post by Anna over at the Mozilla Science Lab blog.
Updates : More resources
- Elevating the status of code in Ecology. Thanks to @katerererena for pointing this one out to me.
- Anna Krystalli’s course material
Back in December 2014, I learned that I’d be moving from The University of Manchester to The University of Sheffield to do the type of thing I’ve always done which is a combination of research software engineering and research software support.
I’ve been in Sheffield for two months now and am having a blast! There’s so much cool stuff going on here that it makes my head spin a little and the community at Sheffield have welcomed me with open arms. It truly is a wonderful place in which to work.
One of the departments I’ve started working with is The Sheffield Institute for Translation Neuroscience (SITraN). My contributions have been relatively minor so far – A bit of Python coding for a machine learning project called GPy and some code speed-up work in R for Winston Hide and his collaborators. When I hang out in SITraN, I usually sit with the machine learning people and listen in on their conversions about Python, MATLAB, GPUs, C++ and R — it’s essentially Nerdvana for someone like me.
On to the point of this blog post. SITraN now have their own blog called SITraNsmissions where they’ll be discussing various aspects of their work and how it applies the principles of neuroscience to help treat diseases such as Motor Neurone Disease (MND). In the video below, taken from SITraNsmissions first blog post, Professor Pamela Shaw gives an overview of the work that SITraN does.
Research Software Engineers (RSEs) are the people who develop software in academia: the ones who write code, but not papers. The Software Sustainability Institute (a group of which I am a Fellow) believes that Research Software Engineers lack the recognition and reward they deserve for their contribution to research. A campaign website – with more information – launched last week:
The campaign has had some early successes and has been generating publicity for the cause, but nothing will change unless the Institute can show that a significant number of Research Software Engineers exist.
Hence this post. If you agree with the issues and objectives on the website, please sign up to the mailing list. If you know of any other Research Software Engineers, please pass this post onto them.
One of my favourite parts of my job at The University of Manchester is the code optimisation service that my team provides to researchers there. We take code written in languages such as MATLAB, Python, Mathematica and R and attempt (usually successfully) to make them go faster. It’s sort of a cross between training and consultancy, is a lot of fun and we can help a relatively large number of people in a short time. It also turns out to be very useful to the researchers as some of my recent testimonials demonstrate.
Other researchers,however, need something more. They already have a nice piece of code with several users and a selection of papers. They also have a bucket-load of ideas about how to turn this nice code into something amazing. They have all this good stuff and yet they find that they are struggling to get their code to the next level. What these people need is some quality time with a team of research software engineers.
Enter the Software Sustainability Institute (SSI), an organisation that I have been fortunate enough to have a fellowship with throughout 2013. These guys are software-development ninjas, have extensive experience with working with academic researchers and, right now, they have an open call for projects. It’s free to apply and, if your application is successful, all of their services will be provided for free. If you’d like an idea of the sort of projects they work on, take a look at the extensive list of past projects.
So, if you are a UK-based researcher who has a software problem, and no one else can help, maybe you can hire* the SSI team.
*for free!
Links
I am extremely short sighted and have a contact lens prescription of the order of -10 dioptres or so. Recently, I was trying to explain to my wife exactly how I see the world when I am not wearing my contact lenses or glasses and the best I could do was ‘VERY blurry!’
This got me thinking. Would it be possible to code something up that took an input picture and a distance from my eyes and return an image that would show how it looks to my unaided eyes?
Would anyone like to give this a go? How hard could it be?
One of my academic colleagues, Fumie Costen, recently asked members of The University of Manchester GPU Club the following question
‘I am looking for a journal with high impact factor where I can publish our work on GPU for FDTD computations. Can anyone help?’
So far, we haven’t had any replies so I’m throwing the question open to the world. Any suggestions?
Earlier this year I was awarded a fellowship from the software sustainability institute, an organization that works to improve all aspects of research software. During their recent collaborations workshop in Oxford, it occurred to me that I was aware of only a relatively tiny number of software projects at my own institution, The University of Manchester. I decided to change that and started contacting our researchers to see what software they had released freely to the world as part of their research activities.
Research software comes in many forms; from small but useful MATLAB, Python or R scripts with just a handful of users and one developer right through to fully-fledged applications used by large communities of researchers and supported by teams of specialist developers. I’m interested in knowing about all of it. After all, we live in a time when even a mistake in an Excel spreadsheet can change the world.
The list below is what’s been sent to me so far and is a mirror of an internal list that’s been doing the rounds at Manchester. I’ll update it as more information becomes available. If you are at Manchester and know of a project that I’ve missed, feel free to contact me.
Last updated: 26th Jan 2015
Centre for Imaging Sciences
- BoneFinder – BoneFinder is a fully automatic segmentation tool to extract bone contours from 2D radiographs. It is written in C++ and is available for Linux and Windows.
Faculty of Life Sciences
- antiSMASH – Genome annotation tool for secondary metabolite gene clusters.
- MultiMetEval – Flux-balance analysis tool for comparative and multi-objective analysis of genome-scale metabolic models.
- mzMatch/mzmatch.R/mzMatch.ISO – Comprehensive LC/MS metabolomics data processing toolbox.
- Rank Products – Statistical tool for the identification of differentially expressed entities in molecular profiles.
Health Informatics
- openCDMS – The openCDMS project is a community effort to develop a robust, commercial-grade, full-featured and open source clinical data management system for studies and trials.
IT Services
- idiffh – Research software can produce huge text files (e.g. logs). The GNU diff program needs to read the files into memory and therefore has an upper bound on file size. idiffh might only use a simple heuristic but is only bounded by the maximum file size (and free file store).
- nearest_correlation – Python versions of nearest correlation matrix algorithms
- ParaFEM – A portable library for parallel finite element analysis. Contributions from MACE, SEAES, School of Materials.
- Shadow – This is an Apple Mac OS X shell level application that can monitor Dropbox shared folders for file deletions and restore them.
- The Reality Grid Steering Library – A software library for steering and monitoring numerical simulations, APIs available for Fortran/C++/Java and steering clients available for installation on laptops and mobile devices. Developed in collaboration with the School of computer science.
Manchester Institute of Biotechnology
- Copasi – COPASI is a software application for simulation and analysis of biochemical networks and their dynamics.
- Condor Copasi – Condor-COPASI is a web-based interface for integrating COPASI with the Condor High Throughput Computing (HTC) environment.
School of Chemical Engineering & Analytical Science
- SurfaceSpectra Identity– is free software that allows you to view and export isotope patterns.
School of Chemistry
- DOSY Toolbox – A free, open source programme for processing PFG NMR diffusion data (a.k.a. DOSY data).
- Clinical NERC – Clinical NERC is a simple customizable state-of-the-art named entity recognition, and classification software for clinical concepts or entities.
- EasyChair – EasyChair is a free conference management system.
- GPC – The University of Manchester GPC library is a flexible and highly robust polygon set operations library for use with C, C#, Delphi, Java, Perl, Python, Haskell, Lua, VB.Net (and other) applications.
- HiPLAR – High Performance Linear Algebra in R. A collaboration between Manchester and Imperial.
- iProver – 7 times word champion in theorem proving.
- INSEE – Interconnection Networks Simulation and Evaluation Environment
- KUPKB (The Kidney & Urinary Pathway Knowledge Base) – The KUPKB is a collection of omics datasets that have been extracted from scientific publications and other related renal databases. The iKUP browser provides a single point of entry for you to query and browse these datasets.
- ManTIME – ManTIME is an open-source machine learning pipeline for the extraction of temporal expressions from general domain texts.
- MethodBox – MethodBox provides a simple, easy to use environment for browsing and sharing surveys, methods and data.
- myExperiment – myExperiment makes it easy to find, use and share scientific workflows and other Research Objects, and to build communities.
- Open PHACTS Discovery Platform – Freely available, this platform integrates pharmacological data from a variety of information resources and provides tools and services to question this integrated data to support pharmacological research.
- OWL API – A Java API and reference implementation for creating, manipulating and serialising OWL Ontologies. The latest version of the API is focused towards OWL 2. The OWL API is open source and is available under either the LGPL or Apache Licenses.
- OWL Tools – a collection of tools for working with OWL ontologies
- OWL Webapps – a collection of web apps for working with OWL ontologies
- RightField – Semantic annotation by stealth. RightField is tool for adding ontology term selection to Excel spreadsheets to create templates which are then reused by Scientists to collect and annotate their data without any need to understand, or even be aware of, RightField or the ontologies used. Later the annotations can be collected as RDF
- SEEK – SEEK is a web-based platform, with associated tools, for finding, sharing and exchanging Data, Models and Processes in Systems Biology.
- ServiceCatalographer – ServiceCatalographer is an open-source Web-based platform for describing, annotating, searching and monitoring REST and SOAP Web services.
- Simple Spreadsheet Extractor – A simple ruby gem that provides a facility to read an XLS or XLSX Excel spreadsheet document and produce an XML representation of its content.
- Taverna – Taverna is an open source and domain-independent Workflow Management System – a suite of tools used to design and execute scientific workflows and aid in silico experimentation.
- TERN – TERN is a temporal expressions identification and normalisation software; designed for clinical data.
- Utopia Documents – Utopia Documents brings a fresh new perspective to reading the scientific literature, combining the convenience and reliability of the PDF with the flexibility and power of the web.
School of Earth, Atmospheric and Environmental Sciences
- ManUniCast – iPad/iPhone app. Weather and Air-Quality Forecasts for the UK and Europe
School of Electrical and Electronic Engineering
- Automatic classification of eye fixations – Identify fixations and saccades from point-of-gaze data without parametric assumptions or expert judgement. MATLAB code.
- Bootstrap Threshold Software – Estimate a threshold and a robust SD from stimulus-response data with a normal cumulative distribution. Written in C.
- LDLTS – Laplace transform Transient Processor and Deep Level Spectroscopy. A collaboration between Manchester and the Institute of Physics Polish Academy of Sciences in Warsaw
- Model-Free Psychometric Function Software – Fit a stimulus-response curve and estimate a threshold and SD without a parametric model
- Raspbian – Raspbian is a free operating system based on Debian optimized for the Raspberry Pi hardware.
- Signal Wizard – Digital signal processing software.
School of Mathematics
- EIDORS – Electrical Impedance Tomography and Diffuse Optical Tomography Reconstruction Software.
- Fractional Matrix Powers – MATLAB functions to compute fractional matrix powers with Frechet derivatives and condition number estimate
- fAbcond – Python code for the condition number of a matrix exponential times a vector
- funm_quad – Quadrature-based Arnoldi restarts for matrix function computations in MATLAB
- IFISS – IFISS is a graphical package for the interactive numerical study of incompressible flow problems which can be run under Matlab or Octave.
- MARKOVFUNMV – An adaptive black-box rational Arnoldi method for the approximation of Markov functions.
- Matrix Computation Toolbox – The Matrix Computation Toolbox is a collection of MATLAB M-files containing functions for constructing test matrices, computing matrix factorizations, visualizing matrices, and carrying out direct search optimization.
- Matrix Function Toolbox – The Matrix Function Toolbox is a MATLAB toolbox connected with functions of matrices.
- Matrix Logarithm – MATLAB Files. Two functions for computing the matrix logarithm by the inverse scaling and squaring method.
- Matrix Logarithm with Frechet Derivatives and Condition Number – MATLAB files
- NLEVP A Collection of Nonlinear Eigenvalue Problems – This MATLAB Toolbox provides a collection of nonlinear eigenvalue problems.
- oomph-lib – An object-oriented, open-source finite-element library for the simulation of multiphysics problems.
- rktoolbox – A Rational Krylov Toolbox for MATLAB
- Shrinking (MATLAB) – MATLAB codes for restoring definiteness of a symmetric matrix by shrinking
- Shrinking (Python) – Python codes for restoring definiteness of a symmetric matrix by shrinking
- Simfit – Free software for simulation, curve fitting, statistics, and plotting.
- SmallOverlap – SmallOverlap is a GAP 4 package which implements new, highly efficient algorithms for computing with finitely presented semigroups and monoids whose defining presentations satisfy small overlap conditions (in the sense of J.H.Remmers)
- Symmetric eigenvalue decomposition and the SVD – MATLAB files
- testing_matrix_functions – MATLAB files for testing matrix function algorithms using identities such as exp(log(A)) = A
School of Mechanical, Aerospace and Civil Engineering (MACE)
- DualSPHysics – DualSPHysics is based on the Smoothed Particle Hydrodynamics model named SPHysics and makes use of GPUs.
- FLIGHT – FLIGHT specialises in the prediction and modelling of fixed-wing aircraft performance
- SPHYSICS – SPHysics is a platform of Smoothed Particle Hydrodynamics (SPH) codes inspired by the formulation of Monaghan (1992) developed jointly by researchers at the Johns Hopkins University (U.S.A.), the University of Vigo (Spain), the University of Manchester (U.K.) and the University of Rome La Sapienza (Italy).
- SWAB Online – Innovative and User Friendly Web Application in Running Fortran-based 1-D Shallow Water near Shore Wave Simulation Modelling
School of Physics and Astronomy
- Herwig++ – Herwig++ is a new event generator, written in C++, built on the experience gained with the well-known event generator HERWIG, which was used by the particle physics community for nearly 30 years. Herwig++ is used by the LHC experiments to predict the results of their collisions and as an essential component of their data analysis. It is developed by a consortium of four main nodes, including Manchester, and its published write-up has been cited over 500 times.
- im3shape – Im3shape measures the shapes of galaxies in astronomical survey images, taking into account that they have been distorted by a point-spread function.
- MAD8/madinput – Mathematica code and MAD8 installer for performing optics calculations for particle accelerator design.
- PolyParticleTracker – MATLAB code for particle tracking against complex optical backgrounds
One of the benefits of working at a university is that you are surrounded by a lot of smart people doing very interesting things and it usually doesn’t take much effort to get them to talk about their research. I work in the faculty of Engineering and Physical Sciences which means that I’m pretty well covered in subjects such as mathematics, physics, chemistry, engineering, computer science, materials and earth sciences but I have to go all the way to the other side of campus if I want to learn a little about the life sciences.
Last week, I attended a free event called The Rogue Cell which was arranged by The Wellcome Trust Centre for Cell-Matrix Research and hosted by The Manchester Museum as part of World Cancer Day. I had no idea what to expect out of the evening but if you were to press me I would have guessed that there was going to be a lot of power point slides and row upon row of gently dozing delegates. I could not have been more wrong.
The event was arranged in a workshop format where all of the attendees were split into five groups of six or so. Each group was then assigned a Wellcome Trust Researcher who’s job it was to explain to us one of five defining characteristics of a cancer cell which were
- Evading the immune system
- Angiogenesis (formation of blood vessels)
- Migration/invasion
- Proliferation
- Lack of apoptosis (programmed cell death).
Each group kept their researcher for 20 minutes or so before they got assigned a new one who discussed a different topic from the five. So, by the end of the evening we had covered the lot. The presentations were intimate, informal and highly interactive and it felt to me like I was having a good chat down my local pub with a group of people who just happened to be world-class cancer researchers. If only all learning experiences were like this one!
There was a great cross section of attendees from PhD biology students through to clinicians, undergraduates, random people off the street and, of course, the occasional math software geek. One of the great things about this event was the fact that everyone seemed to get a lot out of it, no matter what their background. I asked a lot of questions, many of which would have been blindingly obvious to a student of the life sciences but not once was I made to feel stupid or out of place. It must have been exhausting for the presenters but I can honestly say that it was one of the most enjoyable learning experiences I’ve had for quite some time.
I sincerely hope that The Wellcome Trust Centre for Cell-Matrix Research and The Manchester Museum will be arranging more events like this in the future.
Links:
The following links were sent to us following the event. I include them here for anyone who’s interested.
Evasion of Immune System:
- New cancer therapy:http://www.youtube.com/watch?v=t3bI9nBa4FY
- Herceptin mechanism of action:http://www.youtube.com/watch?v=IeE3K7U9fTQ
Migration/Invasion
Proliferation
- http://www.cancerresearchuk.org/cancer-info/prod_consump/groups/cr_common/@nre/@car/@gen/documents/flash/018206.swf
- http://www.youtube.com/watch?v=IeUANxFVXKc&feature=related
- http://www.youtube.com/watch?v=Hm03rCUODqg&feature=related
Angiogenesis