
Archive for April, 2016
The Engineering and Physical Sciences Research Council (EPSRC) is the UK’s main agency for funding research in engineering and the physical sciences. In 2015, they made a very unusual type of fellowship call – one that was targeted specifically at Research Software Engineers. This was the first fellowship of its kind in the world and I believe it represents a strong commitment by EPSRC to the improvement of research software.
Research Software Engineers are the people behind research software. They make a huge contribution to science but often lack reward and recognition for the work that they do. This fellowship is a huge step in the right direction to providing some of that recognition. Quoting from the call document:
This call will support Research Software Engineer (RSE) Fellowships for a period of up to five years. The RSE Fellowship describes exceptional individuals with combined expertise in programming and a solid knowledge of the research environment. The Research Software Engineer works with researchers to gain an understanding of the problems they face, and then develops, maintains and extends software to provide the answers.
201 people responded to the call with an ‘Intent to submit’ outline application. Of these, 7 were successful. As part of my work with the EPSRC funded Research Software Engineering Network (RSE-N), I got in touch with the new cohort of RSE fellows and interviewed them about their projects and careers.
Follow the links below to see what they had to say.
- Louise Brown (University of Nottingham)
- Ian Bush (University of Oxford)
- Mike Croucher (University of Sheffield)
- Oliver Henrich (University of Edinburgh)
- Christopher Richardson (University of Cambridge)
- Paul Richmond (University of Sheffield)
- Chris Woods (University of Bristol)
This interview with The University of Bristol’s Chrys Woods is part of my series of interviews on the new cohort of EPSRC Research Software Engineering Fellows.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I have been coding since preschool when my Dad bought me a Texas Instruments TI-99/4A. This had a simple BASIC, but no tape or disk storage, meaning that all of the code was lost when the computer was switched off. After that, I had an Amiga as a teenager, and had fun coding little games in my spare time. I grew up in a seaside town on the East Coast, and the industry there was just fishing and making frozen food, so it didn’t occur to me that I could do programming as a job. It was just for fun. It was only when I went to University (Southampton) that I saw that programming could be useful for science. I undertook a 3rd-year computational chemistry research project with Jon Essex at Southampton, and from there I was hooked and wanted to become a computational chemist. In Jon’s group in the late 1990’s I helped to build Beowulf compute clusters from scratch (assembling shelves, doing all the cabling, building the cluster installer disks, job schedulers etc.), as well as developing lots of software in first Fortran 77 and then C++ and Python. From there, I moved to Bristol, and wrote lots of grant applications and managed to work for about 10 years on a series of EPSRC and BBSRC funded software development projects (sincere thanks to both funders for the grants). These all culminated in a framework for molecular simulation, called Sire (http://siremol.org), around which a reasonable community has formed (about 20+ people have developed the code over the years).
The experience of working with this community made me realise that software engineering was about helping other people develop and play with code. It showed me the importance of leading by example, e.g. adding in tests, using clean designs and APIs, and writing clear documentation (although I readily admit that I am a really bad documenter).
About 2 years ago I was offered a job in BrisSynBio (a BBSRC/EPSRC Synthetic Biology Research Centre), as a technical lead, systems administrator and RSE. I have really enjoyed this position, as it made me step back from my research and really work in “services” to support other researchers. This gave me a completely new perspective on research, as I saw the world from the view of e.g. administrators, finance, procurement and technical services. This showed me that successful research depends on a whole team of energised, committed and dedicated people, and that research software engineers can play an important role as part of the research development team.
What do you think is the role of a Research Software Engineer? Is it different from a ‘normal’ researcher?
For me, research software engineering is about helping junior researchers develop their code right the first time. Helping them to structure their code so that it is easier for them to write flexible, trustably correct and performance portable software without them having to be overburdened with learning a lot of computer science. Following this, good RSE work is helping researchers build flexible frameworks that allow researchers to play with their scientific ideas. The code should allow them to prototype and play with new ideas, to get them running quickly and efficiently first time without having to have people come and re-engineer everything later.
You’ve recently won an EPSRC RSE Fellowship – congratulations! Can you give a brief overview of your project?
My project is about providing a new member of a research team – the research software engineer. This will enable a new way of doing research. Research is team based, and I want to help change the culture so that RSEs are seen as a member of the research team and not a service. The EPSRC RSE project provides funding for me as an RSE to be embedded within research groups to work with them to develop new research. Twenty projects will initially be supported; 10 in the first wave that have been allocated, and then 10 that will be allocated in response to a call. The projects cover everything from modelling chemical reactions, designing new optical machines, creating great visualisations in an interactive 3D planetarium, modelling bacterial factories and engineering new scaffolds for future vaccines.

How long did it take you to write your Fellowship application (Any other thoughts/advice on the application process?)
I found out about the call when on holiday in Switzerland from a friend. That got me started thinking about a model for how RSEs could be added to a research team. Once I’d worked out the model, I found the proposal to be very easy to write. Indeed, it was the opportunity to write the proposal that I had always wanted to write – to put software development and good software engineering front and centre in the proposal itself. When I got back from from holiday I alerted HPC users at Bristol about what I was planning, and then met up with researchers from across the University in 10 minute quick flash talks set out my proposal for RSE projects. People contributed projects quickly, and I was soon oversubscribed. Then, writing the proposal was just about putting it all down on paper.
The strangest part was that I had consciously left an academic role when I moved into BrisSynBio, and had accepted that I was never going to become “an academic”. The hardest part was talking with my wife and persuading her that I should go back into that world.
Where do you want to be in 5 years?
I want to be running a large and successful RSE group and contributing to the development of computational science/engineering as a complete discipline, i.e. being on the path to having departments with faculty, teaching of undergraduates in good software engineering best practice, researchers in software engineering, collaborating with scientists as parts of teams to develop the next generation of well-engineered code to support 21st century science. I also want to help inspire the next generation of potential RSEs and help (1) raise awareness that programming a computer can help you leave a seaside town and travel the world, and (2) maths, physics and programming are useful skills, that there is stable career pathway for scientific software developers and RSEs, that this is an exciting and dynamic career choice, it does let you work with intelligent and energetic people, and most importantly, it puts you in a position to shape how the technology of the future will be designed and developed.
Who are your project partners?
Cresset, a company that writes software for the pharmaceutical industry, and the Software Sustainability Institute. Also, all of the researchers who will be supported by the RSE projects.
Tell me about your RSE group.
We are now building the RSE group at Bristol. Currently it is me, a new junior RSE to be appointed, and some graduates on our new Graduate Accelerator Programme (GAP) who will be appointed later this year. We anticipate growing further over the next few years.
Which programming languages and technologies do you regularly use?
C++ is my favourite, especially the functional coding support in C++11/14, closely followed by Python. I find the combination of C++ and Python is extremely powerful. It allows easy writing of fast, performant parallel code in the C++ layer, yet retains flexibility in the scripting layer which treats C++ as a library of building blocks. All unit testing can be via Python scripts that stress these building blocks.
I teach a lot of python and strongly recommend it to newcomers, e.g. see http://chryswoods.com/main/courses.html
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
Fortran. I have a soft spot for F77, but it is very 20th century. It is missing modern containers, generics, templates, virtual functions, task based parallelism, easy wrapping with scripting languages, integration with unit testing suites, etc. etc. It is also missing easy handling of low-level memory, while also providing a high level memory interface.
Perl. I loved Perl. I teach Perl, but no-one comes any more. Python is better, and it is difficult to argue against. And then the Perl community turned in on itself in going from Perl 5 to Perl 6.
Is there anything on your ‘to-learn’ list?
Management. How to Teach. Any new programming paradigm. LLVM and stuff that bridges the gap between scripted and compiled languages. Anything else in the programming world that is cool.
And, MATLAB, R, etc., as I need to learn how to interface with the communities that use those tools.
Humility. We don’t always know what is best (even if we do think we are right).
Do you have any advice for anyone who wants to become a Research Software Engineer?
My advice applies to anyone who wants to work in a university as an academic. Never forget that each grant and each award is a gift from the public. You are not given this gift so that you are employed there forever. It is given so that, in some way, you can make a difference to society. Be in research because you want to make a difference. The counter to this, is that there is a life outside academia, and it is not a failure to move on to other roles. Sometimes, like my BrisSynBio position, they can make you stronger
For research software engineering, I would say learn to communicate with people. Being able to talk with people is just as important as being able to talk with the computer. Also, learn the paradigms of programming (structural, object, functional etc.), as once you get these, different computer languages are just different syntax. Finally, learn some maths and science. They may be harder to learn, but they are fundamental, and without understanding these, it is very hard to really appreciate the complexities of research code, or to see the potential optimisations or approximations that may be available.
This interview with the University of Sheffield’s Paul Richmond is part of my series of interviews on the new cohort of EPSRC Research Software Engineering Fellows.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I have been working as a Research Associate (early career research) since I completed my PhD in 2010. During this time I have been working on the fringe of both novel computer science research and the application of emerging parallel computing architectures to various areas of science and engineering. Whilst carving a reasonably successful career as an early career researcher it became clear that in order to progress within the academic environment it would require me to become more specialised in novel research than to participate in applying my skills of parallel computing to broader research domains. The role of the research software engineer is one that means different things to different people. For me it is the role of applying my specialist skills of parallel computing to a wide range of domains. It is a position which encourages the development of my novel research software (FLAME GPU) giving me the flexibility to embed it as broadly as possible.
What do you think is the role of a Research Software Engineer? Is it different from a ‘normal’ researcher?
To me the role of RSE is one which is about facilitating research. This can be through hands on help or the provision of software, skills or a community which provides a specific researching computing need. Having worked both as a researcher and in my new role as a self recognised RSE my view is that it is important that people are able to transcend the boundary between the two. Many RSEs come from support backgrounds rather than research however there are countless researchers who work on providing research software or multi-disciplinary research computing skills. I feel that researchers should be encouraged to move into the roles of RSEs where appropriate but also that this shouldn’t be seen as a career limiting move. RSEs should be free to transition back into academia as a when the research requests it. I hope to demonstrate throughout my position as a RSE Fellow that it is possible to exist alongside this boundary delivering typical academic outputs whilst working collaboratively in a facilitation role.
You’ve recently won an EPSRC RSE Fellowship – congratulations! Can you give a brief overview of your project?
My RSE Fellowship is all about changing the way people think about coding and the way in which they use workstation and HPC computing. In the future computers will be highly parallel with hugh numbers of cores, we are already seeing this pattern emerge today through accelerated computing in the form of GPUs. The traditional “serial” was of thinking needs to change and parallelism needs to be incorporated into computational research from the ground up to enable researchers to target future computing systems. To ensure that this happens my fellowship proposed 1) a combination of software and tools targeting many core architectures, 2) upskilling of researchers on a national scale and embedding of parallel programming techniques within the undergraduate, and postgraduate curriculums and 3) a local and national community in which researchers can receive software consultancy and work collaboratively to embed accelerated computing into their research. As a result of this fellowship researchers will gain access to unprecedented levels of compute performance enabling them utilise scalable computational approaches to solve scientific chand challenges.

How long did it take you to write your Fellowship application (Any other thoughts/advice on the application process?)
The turnaround for the fellowship application was actually very quick. From consultation with colleagues it is normally expected that an EPSRC fellowship application should take about 6 months to complete, undergoing many rounds of internal review before submission. Following notification to continue to full submission (after expressions of interest) there was only just over a month and I had a weeks holiday booked the week before the final deadline… Trying to pick-up internet on holiday in Ireland, actually on Craggy Island (where Father Ted was filmed) was somewhat of a challenge. Fortunately every other applicant was in the same boat and I already had a good amount of material prepared on my ambitions for accelerated computing. Once through to the interview stage having a number of mock interviews helped tremendously in calming my nerves and polishing my pitch.
Who are your project partners?
NVIDIA, ARCHER, EPCC, OCR, ACRC, Oxford e-Science, WRG and N8, TRansport Systems Catapult, DNV.GL.
Bradford University, EPCC (Edinbugh), UCL, Oxford University
Tell me about your RSE group.
Sheffield has two EPSRC RSE fellows and we’ve teamed up to form the Sheffield Research Software Engineering group. We’ve only existed for a month! At the moment its just us but we have funds to recruit a few more people so watch this space.
Which programming languages and technologies do you regularly use?
It’s probably easier to list those that I don’t regularly use! My GOTO: languages are (get it? but seriously I don’t program with GOTO’s);
- C
- C++ (note not the same as above and should not be referred to as C/C++ #endrant)
- CUDA
- OpenMP/OpenACC/OpenGL
- Assembly (ARM and PTX)
- C++ extensions: e.g. Qt (for UI dev), Boost and C++11.
Other languages I use slightly less regularly are;
- Python,
- Java (if I have to, which I do especially for Eclipse plugins)
- Fortran,
- Javascript
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
I use java less and less now. It was taught on my undergraduate curriculum very heavily and at one point was the future for OpenGL on the web. There is just no need for java applets any more….
Is there anything on your ‘to-learn’ list?
Ohh yes. Vulkan is at the top of my list. As the successor to OpenGL for graphics with multi core support I look forward to integrating it with accelerated simulation models.
Do you have any advice for anyone who wants to become a Research Software Engineer?
Software underpins everything and is embedded within almost every research domain. Don’t let anyone tell you that there is no career progression for RSEs in academia. They (the research community) need us just as much as we need them and it’s up to you (and the collective us) to show the world how vital RSEs are in the academic environment.
This interview with the University of Cambridges’s Chris Richardson is part of my series of interviews on the new cohort of EPSRC Research Software Engineering Fellows.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I did a PhD in GeoPhysics, followed by a PostDoc in Japan, over 15 years ago. Although it was a numerical project (on transport of magma), it was rather frustrating to code in Fortran.
I might joke now, that I could solve some of my PhD problems in 5 minutes using some of the more modern tools that we are developing! Partly, that is because of the higher level of abstraction, and the offloading of more routine tasks to libraries.
When I finished my PostDoc, I decided to apply for a Computer Officer role, which I knew would involve some dull, standard IT support but it also came with interesting stuff… code, numerics etc., without the pressure of teaching, publishing and raising grants.
I have been involved with many different computational projects over the years, including calculating neutron diffraction of adsorbed monolayers (Chemistry), and dynamic geomorphology – how a landscape changes over time as a response to tectonics (Geophysics).
More recently, I started working with the FEniCS team, first via an EPSRC dCSE grant, administered by NAG. The idea of dCSE was to improve code for running on HPC systems – we needed to get better parallel I/O into FEniCS, so it was a perfect match. It was an opportunity for me to learn C++ and really get involved in some of the internal issues in parallel coding.
After the end of the project, I continued to work on FEniCS from time to time, and I gradually got accepted as a member of the core developer team. We applied for a (now rebranded) ECSE project and also some projects with commercial partners.
What do you think is the role of a Research Software Engineer? Is it different from a ‘normal’ researcher?
I suppose it depends what you mean by “normal”. Mostly, I would expect an RSE to work collaboratively with other scientists and engineers, and not to lead scientific projects themselves. So, whilst not being a PI on a project, they need to communicate effectively with the scientific team they are working with, provide the technical expertise to realise the computational aspects of the project, and have some scientific understanding too.
Ultimately, it is important to have something invested in a collaboration, so it is not just a service, but a personal involvement, which might result in a joint publication or another form of recognition. And that is not so different from many “normal” researchers below the PI level.
You’ve recently won an EPSRC RSE Fellowship – congratulations! Can you give a brief overview of your project?
I am part of a team, writing a finite element analysis library. Finite element analysis (FEA) goes way back to the early days of computing, and has been used by engineers for decades, because it is very good at modelling physics in arbitrary shaped objects. One of the problems of FEA is that it is tricky to program, so our library FEniCS takes care of some of the more difficult aspects, whilst allowing the user a great deal of flexibility in describing the equations or meshes to solve on.
I am extending FEniCS to use: (a) complex numbers – useful for wave-like phenomena, (b) powerful non-linear solvers, which can solve difficult problems more quickly, (c) curved boundaries – needed for interface problems, e.g. surface tension, and (d) dynamic meshes, which can change in geometry and topology over time.
As well as “just doing programming”, I want to engage with the scientific community to apply these techniques to actual physical problems, and form collaborations with domain scientists in their specialist areas. Ultimately, I want to build up a small RSE team who can help scientists across diverse fields to solve their computational problems, using FEniCS, or other relevant packages.
I also hope to be involved in teaching and training more sustainable practices in the scientific community, helping people to use revision control, and write more reusable code.

How long did it take you to write your Fellowship application?
The EPSRC call was very widely advertised, and I received multiple emails about it. Since the first hurdle was small – only an A4 sheet – I decided to give it a go.
I guess it was a standard EPSRC call template, and things like – ‘Early career stage researcher’ seemed like a possible blocker, but the A4 sheet was accepted, so I made a full application, and the feedback from reviewers was very positive. Writing the full application was very stressful, and really a full-time occupation for a few weeks. I felt like someone who had an exam but hadn’t revised for it. Some friends said to me: “make it easy for the reviewers” – which is good advice. By closely reading the call documents, I tried to tick off as many points as possible, and make my application match the criteria as well as I could.
I was quite nervous for the interview, and I’m sure I said a few stupid things, but I don’t think that’s particularly unusual. Everyone at EPSRC was very friendly.
Who are your project partners?
I’ve got academic project partners at Southampton and Oxford Universities in the UK, as well as at Simula Research in Norway, and Rice University in the US. Industrial partners are BP and Melior Innovations.
Who are the users of FEniCS?
FEniCS has got a lot of users across the world, but in many ways, it is difficult to know who they are. We have many different distribution channels, so we can’t really monitor downloads. One estimate is the number of questions we get on the user forum. These have come from 50+ countries around the world, and average about two questions per day.
How long have you been involved?
I have been involved for about the last 5 years, gradually building up from being a user, to a part-time contributor, to core developer.
Do you find it it difficult to get recognition/ full time employment for your work?
I’m not sure if I get recognition, I suppose becoming an EPSRC fellow is recognition, and I usually do get included as an author on scientific papers. Recently we started issuing release FEniCS notes in Arch. Num. Soft., which is a way to get recognition for pure library development.
How many Fenics developers and which version control system do you use?
There are about half a dozen core contributors, mostly Europe-based, and we use “git” on bitbucket.org.
Tell me about your group.
I am in a small institute, with researchers from Earth Sciences, Chemistry, Chemical Engineering, Engineering and Applied Maths. I am the only RSE in the building, but we are on the West Cambridge campus, which includes the University High Performance Computing Service (HPCS), just across the road. I am working with Filippo Spiga from HPCS and his team. I also spend quite a lot of time at the Engineering Department, where one of the other FEniCS developers (Dr Garth Wells) is based.
What’s your plan for the future?
The head of the BP Institute is a professor in Earth Sciences, and he has always been very supportive. He sees my RSE fellowship as an opportunity to expand our RSE activities in the future. I want to help researchers write RSE time into their grant proposals, so we can collaborate on a wide range of projects, continuing after the period of the fellowship.
Which programming languages and technologies do you regularly use?
For serious coding, almost everything is in C++11 now. Some people complain that it is not good for scientific computing, but there are some excellent libraries, such as Eigen3 and boost::multi_array which provide highly optimised matrix algebra, and access to multi-dimensional arrays, in much the same way as Fortran or C.
- Python is very useful for doing things quickly, and has really taken over almost entirely from shell scripting.
- SWIG – a bit esoteric, but essential for wrapping C++ to Python.
- Google tests. Atlassian Bamboo CI. Run tests inside docker inside Bamboo.
- ParaView – really useful for visualisation.
What would we like? We have a user forum, based on q2a, but it would be much nicer if it had a “Stack Exchange” like interface. Maybe we should investigate using Area51.
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
- Fortran. I know it’s still widely used, and there are modern versions, but I’m not going back.
- Shell scripting. I mostly use Python instead now – it’s easier to understand.
Is there anything on your ‘to-learn’ list?
- How to use Python in ParaView
- How to write threaded code that is efficient for Finite Element
- Using hybrid OpenMP/MPI
- Intel Xeon Phi
Do you have any advice for anyone who wants to become a Research Software Engineer?
I think you need to be multi-skilled. You need to understand people – psychology and culture; programming – obviously; and have some basic understanding of the science itself, even if you don’t know all the details.
This interview with Oliver Henrich is part of my series of interviews on the new cohort of EPSRC Research Software Engineering Fellows.
Which University are you from?
I work at the School of Physics and Astronomy and the Edinburgh Parallel Computing Centre at the University of Edinburgh.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I have a background in soft condensed matter physics, a relatively new and interdisciplinary field of science at the interface of physics, chemistry and biology. Soft matter is squidgy stuff that you know from your everyday lives: viscous liquids, polymers, foams, gels, granular materials, liquid crystals, but also biological materials. The behaviour of soft matter is difficult to predict, which is why computer simulations are a major tool of the trade. Over several postdoctoral appointments and a previous fellowship I evolved from an application scientist to a research software engineer (RSE). This is also why I still have a small personal research agenda, contrary to many other RSEs.
What do you think is the role of a Research Software Engineer? Is it different from a ‘normal’ researcher?
I think the roles of RSEs and researchers are very different. Researchers apply software as application scientists and publish their results in scientific publications. Developing new software is almost always just a means to an end of getting the next publication out. With the focus on science traditional researchers often lack the programming skills and rigorousness for developing sustainable, extendible and failure-proof software solutions. RSEs combine in-depth knowledge of IT technology with a scientific background. This skill set is also quite distinct from that of a Postdoctoral Research Associate. The role of RSEs is more akin to those of managers of experimental labs. Research software engineers are the caretakers of ‘virtual laboratories’, and in that sense do complementary and important infrastructural work for traditional researchers.
You’ve recently won an EPSRC RSE Fellowship – congratulations! Can you give a brief overview of your project?
My programme of software development consists roughly of two different tracks. The first strand of projects is related to Ludwig, a code for simulation of complex fluids which uses the lattice-Boltzmann method. Ludwig has unique capabilities and can model the flow of liquid crystals, bacterial and algae suspensions or liquid electrolytes in complex, nano- and microscopic geometries. Surprisingly little is known about the dynamics of these systems. My goal is to enable new research by extending Ludwig’s capabilities. We also want to make Ludwig part of an open source, scalable library for simulation of complex fluids. Something like this exists for conventional computational fluid dynamics in the form of the celebrated OpenFOAM framework.
The other strand of projects is about developing a community code for multiscale modelling of DNA and RNA. While we know a lot about DNA through genetic sequencing we know little as to how DNA and RNA behave dynamically in space. With sequencing we get the analogue of a 2D still photography of DNA, but what we need to understand its behaviour and functionality in more detail is in fact something like a 3D movie.
Besides these activities I am also involved in a number of other High-Performance Computing projects and outreach events. I am also planning to approach local coding clubs and give software enthusiasts an idea of the job role of RSEs.

How long did it take you to write your Fellowship application? Any other thoughts or advice on the application process?
It took me about 2-3 weeks to write and compile all necessary documents, i.e. the track record, case for support, pathways to impact statement and the support statements and letters of support from my project partners. I have to admit this is a lot of work for a single person, comparable to writing an EPSRC Standard Grant application all alone. This, however, would be normally done in a team together with other researchers. Other fellowship schemes take this into account and make their applications more lightweight.
I think what is really important is to ask for guidance from the research council. It helped me a lot to understand what the aim of this specific call was and how I had to write my application.
Who are your project partners?
As I am based at the University of Edinburgh I work with a number of local people, primarily members of the local Soft Matter Group, EPCC and researchers at the School of Engineering. My other project partners further afield are at the University of Barcelona in Spain, Sandia National Laboratories in the USA and domestic universities like the University of Oxford, University College London and the University of Cambridge. One of my project partners is actually the incumbent Lucasian Professor of Mathematics at Cambridge, showing how far research software engineering is linked to cutting-edge science.
Tell me about your RSE group.
There is strictly speaking no such thing as my group. I am a member of the Edinburgh Parallel Computing Centre (EPCC), a growing group of about 90 software development experts and work with them on a per-project basis. At EPCC, now in its 26th year, the career path of RSE is relatively well established. Many people have been around for a long time and built unique skill sets. It is a big advantage for me to be able to draw on their long-term experience and expertise. I also work with various academic researchers, Postdocs, PhD students and MSc students at the School of Physics and Astronomy and the School of Engineering.
Which programming languages and technologies do you regularly use?
Most of the time I use C/C++ and MPI for my applications and Python for scripts for pre- and postprocessing. I am also working with OpenMP and CUDA C, but I am not one of the lead developers and tend to extend and enhance existing code. For our own in-house software we use advanced UNIX language features for automated testing suites and nightly build tests.
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
I used Fortran a lot in the past and moved now away from it. This, however, reflects more the specific applications I work with at the moment. Some of my colleagues at EPCC are full-time Fortran programmers and there are fantastic Fortran codes out there which are virtually irreplaceable and would be difficult to rewrite in the current funding situation. Object-oriented programming has become so ubiquitous and offers a wide range of convenient features which simplify maintenance and reuse of code. This is more naturally embedded in C++.
Is there anything on your ‘to-learn’ list?
The latest standard MPI 3.1 (pdf download) offers a lot of sophisticated single-sided communication features which I would like to become acquainted with. I would also like to get a better understanding of CUDA C and OpenCL, but fear this will never go beyond basic knowledge as I don’t seem to have enough time to engage intensively with applications that are written in these languages. As for the computational science I need to become more familiar with specific algorithms and computational concepts. This includes advanced sampling techniques for rare events and discrete, non-standard methods for fluid dynamics.
Do you have any advice for anyone who wants to become a Research Software Engineer?
I think most of the people in this new and emerging profession have evolved towards rather than chosen this line of work. So aiming directly for this career is somewhat unprecedented. I would emphasise the importance of working in a research environment with scientists. Ultimately the job requires a very specific skill set between a traditional academic researcher and a software expert. Hence, a PhD or postdoctoral appointment in a specific field of interest with a strong focus on software development could be a good starting point for such a career.
In this article, I find myself in the rather odd position of interviewing myself as part of my series of interviews with the new cohort of EPSRC Research Software Engineering Fellows.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I completed a PhD in theoretical physics in 2005 at The University of Sheffield where my area of research was photonic crystals. The most important thing I learned during my PhD is that I was a lot better at solving computational problems than I was at Physics. In particular, I seemed to be a lot better at solving other people’s problems rather than inventing and solving my own.
This led me to consider a job at The University of Manchester in the centralised Applications Support Team with IT Services. This team looked fantastic! Its role was to support Manchester’s extensive site licensed application portfolio – MATLAB, Mathematica, Intel Compilers, SPSS, Abaqus…that sort of thing. It included aspects of licensing, sysadmin, installation support, high performance computing, consultancy, teaching – you name it! Sadly, 6 months after I started at Manchester, there was the first of many IT department restructures and the team was disbanded.
The centralised service was devolved into the faculties (It’s centralised again now!) and I ended up in the faculty of Engineering and Physical Sciences. I took the responsibility of supporting a portfolio of applications with me. Broadly speaking, I became ‘the MATLAB guy’ at Manchester but also started extending support into the open source world — Python, R, Octave and so on. This was done organically: I went were the work took me. If lots of academics came with problems in foo, I learned about foo, solved problems in foo and started teaching how to do foo better. If ‘foo’ happened to be distasteful to me — such as VBA — well, tough! To be successful in support, you must do the job that’s put in front of you. It’s a little like an Accident and Emergency department.
Very early on, I learned that the path to a researcher’s heart was speed. They wanted results and they wanted them fast! There was a team at Manchester doing hardcore Fortran/MPI stuff and they had that market sewn up — there was no space for the likes of me there. So, I took advantage of being ‘The MATLAB guy’ and started offering programming services to whoever wanted them for free. I could often achieve 100x speed-ups with less than a day’s work and this made me pretty popular!
I got to see a lot of code and that’s where the problems started. I’d get code with names like phdresults_dec2006_ver12_broken_fixed_FORMIKE.m that wouldn’t run on my machine. I’d learn that my machine was the second machine it had ever been run on and I was the second person to ever see the code. There would be 1000s of lines of code with no version control and no tests which made refactoring scary!
I learned that a huge amount of computational research was being done inefficiently. I feel that I need to be very clear: when I say ‘inefficient’, I’m not referring to Fortran code, say, that’s not making optimal use of the cache, SIMD instructions or has poor scaling over 128 cores. When I was young, this is where I thought the work would be. Sure, there’s some, but that’s not where you can help the most people.
A much more common situation, I find, is a researcher who’s workflow includes a huge amount of manual work. PhD students (and in one notable case, a very senior professor!) who manually edit 100s of spreadsheets for example. A morning’s work spent on some simple automation can completely change their lives!
These experiences got me interested in how to improve the general level of software engineering practice in research. I became a Software Sustainability Institute fellow in 2013, discovered this huge, amazing community and the rest is history.
You recently left Manchester University to move to Sheffield? What was behind that?
Prof. Neil Lawrence met me in The Sheffield Tap one evening and said ‘How would you like to ditch your commute and change the world?’ He was interested in bringing some of the research software initiatives I’d worked on in Manchester over to Sheffield as part of his Open Data Science initiative.
Changing the world sounded interesting but he had me at ‘ditch the commute’ if I’m being honest. I’ve lived in Sheffield for 20 years and commuted to Manchester by train for 10 of those. On some days, my twitter feed @walkingrandomly degenerated into little more than rants against various train companies! I needed to stop.
Working with Neil and the University of Sheffield has been an amazing experience. There’s a vibrancy here that’s infectious and a strong desire to do better in Research Software. That Sheffield won 2 of the 7 Research Software Engineering fellowships on offer was like a dream come true. The other Sheffield RSE fellow is Paul Richmond and we’ve joined forces to provide the strongest research software service we can to The University of Sheffield.
What do you think is the role of a Research Software Engineer?
I’m going to lift the answer to this straight out of my fellowship application.
Technological development in software is more like a cliff-face than a ladder – there are many routes to the top, to a solution. Further, the cliff face is dynamic – constantly and quickly changing as new technologies emerge and decline. Determining which technologies to deploy and how best to deploy them is in itself a specialist domain, with many features of traditional research.
Researchers need empowerment and training to give them confidence with the available equipment and the challenges they face. This role, akin to that of an Alpine guide, involves support, guidance, and load carrying. When optimally performed it results in a researcher who knows what challenges they can attack alone, and where they need appropriate support. Guides can help decide whether to exploit well-trodden paths or explore new possibilities as they navigate through this dynamic environment.
These guides are highly trained, technology-centric, research-aware individuals who have a curiosity driven nature dedicated to supporting researchers by forging a research software support career. Such Research Software Engineers (RSEs) guide researchers through the technological landscape and form a human interface between scientist and computer. A well-functioning RSE group will not just add to an organisation’s effectiveness, it will have a multiplicative effect since it will make every individual researcher more effective. It has the potential to improve the quality of research done across all University departments and faculties.
Are there any downsides to being a Research Software Engineer?
Something I’ve learned from conducting these interviews is that there are several different types of ‘Research Software Engineer’. We are not a ‘one size fits all’ community! I think that one thing we all have in common is that we don’t fit the normal ‘money-in, papers-out’ model of many academics. This was brought up in Louise Brown’s interview and it strongly resonates with me. This situation makes it difficult for us to follow an academic-like career path.
It is extremely difficult, for example, to get promoted as a research programmer without attempting to become something you are not. Worse, it’s difficult to simply get a permanent job! Many RSEs are on short term contracts with low salaries. In short, you get much of the grief of working in academia without any of the benefits. Little wonder, then, that many of the best in the community choose to work in industry.
An alternative path for RSEs is to work in the University IT department. It’s the path that I took for example. This solves the short term contract issue but brings with it a whole new set of problems. Many IT managers simply don’t understand the value that an RSE can bring to a University. You can sum the issue up with the observation ‘Academics rarely complain to the head of IT that there’s no one around who can optimise their MATLAB code but they complain very quickly when MATLAB doesn’t work on the University managed desktop’. So, guess what I’d get assigned to?
We’ve established that RSEs aren’t ‘normal academics’ and they aren’t ‘normal IT support’ either so where do we fit? I’m trying to help figure that out and help provide an environment where RSEs can not only exist but thrive.
You’ve recently won an EPSRC RSE Fellowship! Can you give a brief overview of your project?
I aim to improve the research software of the ‘long tail scientist’. This term, attributed to Jim Downing of the Unilever Centre for Molecular Informatics – refers to the large number of small research units who perform a huge amount of research. Often, these small research units only have one or two people in them. They aren’t “big science” but there are LOTS of them!
Much of this research involves the generation of code by relatively untrained and inexperienced programmers. This code can benefit greatly from input by RSEs. An experienced RSE can, with relatively little effort, significantly enhance the quality and efficiency of such code whilst simultaneously providing training for the researcher who wrote it. For examples of what I mean, see my Testiminonials page.
I will improve scientific software efficiency, sustainability and reproducibility at the University of Sheffield, by working alongside researchers on their research code in a consultative manner. Rather than working prescriptively, my approach is based on offering and implementing a series of nudges. Nudges are interventions that alter people’s behaviour in a predictable way without forbidding any options. In the context of research software, example nudges might include ‘Learn to write idiomatically in your language of choice – it can lead to faster execution’, ‘See how unit tests allow us to make changes with confidence’ or ‘Using version control, we always know which code produced what result’.
The gulf between the computing scientific “elite” and those emailing spreadsheets is growing and I aim to close that gap. One researcher I worked with recently said ‘You provide the next step after we’ve been on a Software Carpentry course.’ and I think that describes what I’m trying to do quite well.
How long did it take you to write your Fellowship application? Any other thoughts/advice on the application process?
Writing my fellowship application was one of the most difficult writing exercises I’ve ever undertaken! It took just over a month to write and during that time I did very little else. It took up my days, my evenings, my weekends, my every waking thought. It even consumed my dreams. It was exhausting!
Something that surprised me was the number of people who I needed to help make it happen. Fellowships are often made out to be very individual things but my application involved work by over 40 people! This includes university administrators at all levels, project partners, advisors and mentors. I had to navigate areas of University life and systems that were completely alien to me. There is no way I could have done it alone.
It is essential to get institutional support for your application. At the most basic level, you need a manager who is happy for you to go AWOL for a few weeks. At a higher level, you need to be able to demonstrate to the funding body that your University is fully behind you and your project.
You also need to be emotionally resilient. I poured my heart and soul into my first draft and the feedback from one of my advisors was ‘Well, you solved the blank-page problem.’ That was the only positive thing she had to say! Everything else was a tearing apart. It was brutal! I think I might have cried a little.
Every time I did a rewrite, my mentors found more weaknesses and beat up on me a little. This feedback was essential and made the application so much stronger. As such, I think one piece of advice I’d give is ‘Find mentors you trust who are going to be crushingly hard on you’. It’ll hurt but nowhere near as much as the comments of Reviewer 2 ;)
Who are your project partners?
My style of working is extremely collaborative. As such I have a lot of formal project partners: The Software Sustainability Institute, The University of Manchester, UCL, Microsoft Research, Dassault Systèmes, Wolfram Research, Mathworks, The N8 Research Partnership, Maplesoft and NAG.
Tell me about your RSE group.
Sheffield has two EPSRC RSE fellows and we’ve teamed up to form the Sheffield Research Software Engineering group. We’ve only existed for a month! At the moment its just us but we have funds to recruit a few more people so watch this space.
Which programming languages and technologies do you regularly use?
I don’t get to choose what languages I use — the researchers I support do that for me. As such, I’m doing a lot of MATLAB, Python and R these days. For compiled languages, I tend to use either C or C++. There’s also some Mathematica and Maple sprinkled here and there.
I help support Sheffield’s High Performance Computing Service so also do a reasonable amount of Bash scripting and parallel computing.
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
I used to use Fortran back in the day but don’t seem to need it much now — it’s been a long time since I did a project with it. A couple of groups are offering to teach ‘Modern Fortran’ for us at Sheffield so perhaps I’ll take another look?
I used to like Perl, and even taught a one-day course on it 10 years ago but I strongly prefer Python and so, it seems, do the researchers I support.
Is there anything on your ‘to-learn’ list?
- Cloud computing: I’ve started doing some small projects using Amazon EC2 and feel very much a newbie at the moment. I can figure out how to do things but am not sure if what I am doing is good practice or not.
- Docker: I understand the basics but am yet to figure out how to use the technology properly for research.
- Julia: I played with it a little a few years ago and really like it. There’s a lot of buzz around the language. No one has come to me with a Julia problem yet but I think its just a matter of time.
- Modern OpenMP: I learned OpenMP a long time ago. It’s time for an update.
This interview with Ian Bush is part of my series of interviews on the new cohort of EPSRC Research Software Engineering Fellows.
Which University are you from?
Oxford. The RSE fellowship will be in the Oxford e-Research Centre and will fund 80% of my time. The remaining 20% will be for my current post, as support staff for the HPC Cluster that ARC provides to the university.
Could you tell us a little about yourself and how you became a Research Software Engineer?
Drifted into it! Ultimately I’m a chemist/condensed matter physicist, my degree is in the former and my doctorate is more toward the later, but really the division is artificial. During my doctorate I had to code up various models to run on the two Cray 1 machines (nicknamed Ronnie and Reggie) then placed in ULCC, and as time went by I got more interested in the method of solving the problem rather than the solution of the problem itself; in the end I was investigating and implementing totally different algorithms from that originally proposed for my project. From there I went to what is now STFC Daresbury Laboratory supporting and developing parallel software on the Intel iPSC/860 machine there with a whole 64 cores. Hence my interest in parallel computing, and since then I have been working on the development, optimisation and support of a number of packages in the materials science/chemistry area. I’m probably most closely associated with CRYSTAL and DL_POLY (in total over 3000 groups worldwide hold licences for these applications) but I have code in a much larger number of widely used applications. If asked for my niche it would be that I couple good parallel programming skills with a good understanding of the scientific areas in which I specialise.
What do you think is the role of a Research Software Engineer? Is it different from a ‘normal’ researcher?
Yes it is different. An RSE’s prime role is in the enabling and facilitation of research, not in the carrying out of research itself. Given an idea, often (but not always, the RSE him/herself can be the driver) provided by a researcher, the RSE is the person who implements it, who makes it reality, and then usually hands it on/back to a researcher to exploit. Thus while the researcher gets the immediate benefit and publishes the papers, it would not be possible without the RSE, and I hope that EPSRC’s funding of these posts will drive the better understanding and recognition of these vital individuals and groups within the academic research infrastructure.
It requires a demanding skill set! While it is very much engineering in that the idea has to be turned into a design spec and then through the programming skill of the RSE into a correct, usable, maintainable, extendable and efficient solution to the researcher’s problem, it is more than that. People skills are required to interact constructively with the user to provide a solution tailored to their needs, often scientific insight into the user’s area is of great benefit and knowledge of the world without the RSE’s institution is vital to avoid reinventing the wheel – A RSE is not a jack but a master of all trades! But then again if it weren’t challenging it wouldn’t be fun …
You’ve recently won an EPSRC RSE Fellowship – congratulations! Can you give a brief overview of your project?
Well the funding provided by EPSRC is for me and a post-doc, 8 FTEs in total over a 5 year period. The theme running through the proposal is to push the scalability of software on the very highest end hardware, and so is very much based in high performance computing (HPC) and the exploitation of 10’s and 100’s of thousands of cores for the solution of scientific problems. Within this there are two threads, one programming, one based in teaching.
The programming thread is to develop a small set of codes so as to better utilise HPC, both in terms of scalability and in terms of solving scientifically exciting problems . These are mostly based in my traditional area of material science (CRYSTAL, CRYSCOR and DL_POLY), but one is a new collaboration with the Culham Centre for Fusion Energy, CCFE, to work on their gyrokinetic plasma simulation code, GS/2. All these codes have been demonstrated to scale in at least part of their functionality to many hundreds or thousands of cores, but there are scientific drivers for this to be improved.
As one example take CRYSTAL. This is an ab initio electronic structure code, so it (approximately) solves Schrödinger’s equation for a given system of interest, and from that solution many interesting properties of the material in question can be calculated. The issue here is that while the base solver is parallelised well and has been shown to amongst the best in class (see e.g. Orlando et al. “A new massively parallel version of CRYSTAL for large systems on high performance computing architectures”, Journal of computational Chemistry, vol. 33, no. 28, pp. 2276–2284) the calculation of certain quantities is not parallelised, and thus for large systems while the base equation can be solved the scientifically interesting stuff can’t! During the fellowship, in collaboration with STFC RAL, the University of Turin and Imperial College London, the post-doc and I will work to address this. One of the most interesting areas is how materials interact with light. This can be modelled by Time Dependent Density Functional Theory (TD-DFT). A serial version of this exists within CRYSTAL but due to lack of expertise within the developers this has not been parallelised. As RSEs, I and the post-doc will provide the skill set to develop a fully parallel distributed memory implementation capable of scaling to many thousands of cores. This in turn provides many scientific opportunities. One possibility is the first fully ab initio modelling of radiation damage in proteins; the current code is attempting this but its current model of a protein is the small 29 atom hydrocarbon n-C9H20 due to the limitations of the serial implementation, rather than the 100s or 1000s of atoms that make up a real protein. The new code will allow understanding what is really happening when X-rays are incident on materials, for example in a synchrotron such as Diamond, as the X-rays will damage the material being studied as the measurements are being taken. It will also provided insights when other soft, organic systems, such as humans, are exposed to high energy electromagnetic radiation.
High energies are also obviously relevant to the work on the plasma modelling code GS/2. The background to this is ultimately the 10 billion euro experimental tokamak ITER being built in France to examine the possibility of using hydrogen fusion power as a cheap, plentiful supply of energy – in other words cheaper electricity bills! Again the current code scales well to a few thousand cores, but even at this level of computational power they are still far away from a fully realistic model of the plasma within a tokamak such as ITER. For instance it would be desirable to use a spatial resolution which is roughly two orders of magnitude finer than currently used, this resulting in a 100 fold increase in simulation time on the current thousands of cores that can be used currently. To solve such a problem in reasonable times instead needs 100s of thousands of cores, and scaling the application up to this size of machine is what will be studied by myself and the post-doc.
The teaching strand covers areas I think are poorly covered within the UK. Firstly, unlike in my youth, the majority of HPC users are now not programmers but application users, people who view the computer program as black box, a tool used to generate results to present in papers and at conferences. But like any complex tool its use is not easy, and I believe application specific training for the best use of parallel computers is something that is sorely lacking. Thus for the codes I will work on I shall develop such material under a creative commons licence, and will present it to interested groups focusing in the first place on CDTs. For programmers I also feel that while teaching the syntax of OpenMP or MPI, the basic parallel programming tools within in computational science, is well covered, when and how to use them is not. After all a large supercomputer is one of the most powerful tools available to a programmer, we teach them what the tool is but not how to use it – it’s akin to giving someone a chainsaw and then telling them to cut down trees before you show them how to use it. So again under creative commons, and again initially focussed on CDTs, I shall develop material covering aspects such as how to think about distributing objects on multinode machines, and how to assess the potential scalability of different algorithms and data distributions.
Over and above that I hope to use the fellowship to raise the profile and recognition of the RSE initially within the byzantine institution that is Oxford, in the longer term without. I feel passionately that the lack of understanding, respect and job progression possibilities for people who provide the irreplaceable technical enabling of fundamental research is wasting any number of opportunities for UK PLC, not just in terms of scientific research that is just not possible without the RSE, but more importantly in the people who are lost from the field due to the lack of opportunities within it. I dearly hope that the existence and actions of RSE fellows will not only prove a first step in improving the current situation (and kudos to EPSRC for recognising the issue), but also as an example to aspiring, talented graduates that an RSE is a real career opportunity and path, with resulting benefit to all.

How long did it take you to write your Fellowship application? Do you have any advice on the application process?
Difficult to say, but the hard work was mainly over the last 2 weeks with 2 very long days just before the deadline … However long before then I had held a number of meetings with my collaborators, and I asked for letters of support as early as I possibly could.
Advice? Contact your collaborators as early as possible! The dependency list for writing the proposal when you have a large number of collaborators will be complicated, so get that sorted well before the deadline. Otherwise don’t underestimate how long it will take, and don’t overestimate how much you can put in 8 pages, it is not much space.
Who are your project partners?
Universities: Oxford, Turin, Bristol, Southampton, Imperial College London, University College London
Other: STFC RAL, STFC Daresbury, Culham Centre for Fusion Energy, HPC Materials Chemistry Consortium, NAG
Tell me about your RSE group.
The fellowship provides a seed for me to develop a research group within OeRC and Oxford, with 7 years of funding (3 provided by OeRC) for myself and 4 for a post-doc. The above paragraphs cover some of the more immediate goals for the group but of all of those possibly the most important is that raised last – “I hope to use the fellowship to raise the profile and recognition of the RSE initially within the byzantine institution that is Oxford, in the longer term without.” For me at least I hope to grow the group, and through collaborations with the group show the benefit of RSEs, both through the software engineering aspects and by providing RSEs with longer term employment possibilities coupled with real career progression opportunities. The cynic might say that I need to do that for my own career, the altruist that it is only in the interest of UK PLC for me to achieve this – I hope I am more the later than the former!
Which programming languages and technologies do you regularly use?
Fortran 95 or later, C, C++, MPI, OpenMP, Doxygen, svn, git, netCDF, a variety of debuggers and profilers, almost entirely on Linux. A variety of batch scheduling systems. And god’s own editor, Emacs. Powerpoint when I must, but I prefer the Libreoffice tools and latex where appropriate.
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
Fortran 77. Because it is crap not conducive to enabling modern best practice in software engineering. I only mention it because it is clear that students are still being taught this due to lack of funded, experienced RSEs in science departments. This leads to the teaching of programming being left to the department’s “computer guy” who learnt his/her programming 25 years ago and hasn’t done it seriously since. THIS MUST STOP. It is to the detriment of both the students and computational research in general. Fortran 77 was of its time, but its time was half a century ago, nowadays use Fortran 2003 or C++ where performance is required, or one of the better scripting languages, e.g. python, when it is not.
Apart from that numerous message passing technologies (e.g. PVM, NX/2, PARMACS) which are just thankfully obsolete. SCCS, RCS, CVS … why does every project I am involved in have a different revision control system!?
Is there anything on your ‘to-learn’ list?
Python. Improve my C++. Money. I fundamentally don’t understand money and I fear it will become rather important in the new post. The French Defence, Winawer variation from white’s perspective.
Do you have any advice for anyone who wants to become a Research Software Engineer?
Be passionate about solving problems. Be involved with the researchers you are helping. Be patient as it ain’t going to happen quickly!
This interview with the University of Nottingham’s Louise Brown is part of my series of interviews on the new cohort of EPSRC Research Software Engineering Fellows.
Could you tell us a little about yourself and how you became a Research Software Engineer?
I’ve had a peculiar career path. I’ve worked as a software engineer for 25 years. I did my PhD in Mechanical Engineering and then moved to a CS department where I worked for a company whilst based in the Drawing Recognition Research Group. I was working on CAD systems for industrial embroidery machines implementing algorithms for automatically converting image data into embroidery machine input data. I worked there for four years until my daughter was born after which I returned part time.
My daughter was ill when she was small and when my son was born 2 years later, I stopped work completely for 2 years. I then worked part time from home for 13 years, firstly on ‘Easy Cross’ software for design of home needlecrafts. I designed and developed add-on modules for different crafts including bobbin lace making, patchwork and knitwear design. My second job during that time was working on a system for automatic reading of travel documents such as passports and air tickets.
I moved to my current post six years ago which advertised for an open-source software co-ordinator. The job entails running the TexGen project, working as a software engineer but with a Research Fellow job title. After a while I started to become aware of the issues surrounding being employed as a researcher but spending most of the time programming. For me the main issue was the lack of career progression, being employed at the top of the Research Fellow scale but with little chance of promotion because there was limited chance of fulfilling the criteria for Senior Research Fellow. (The fellowship fixed this!).
To try and address this I started doing some teaching (MATLAB course for postgrads and first year undergrad drawing and design tutorials). I also joined committees to attempt to broaden my work profile. I am a co-author on a few papers but not enough for academic promotion, although there is more effort being made now to include me when a specific piece of development has been carried out which enables the work described in the paper. I applied for a promotion last year but was turned down, mainly due to lack of publications but also due to my not having done any PhD supervision..
One problem was that my performance reviewer did not know what to suggest in order to move my career forward. One possibility which I was encouraged to look at was fellowships but, having returned to academia relatively recently, I came into the category of ‘Early Career’ fellowships. These normally specify a time limit since completion of a PhD and the 25 years since I completed made these unsuitable. This fellowship was suitable because despite being labeled ‘Early Career’, it had no such time limits and it didn’t matter that I don’t fit the normal early career pigeon holes.
What do you think is the role of a Research Software Engineer? Is it different from a ‘normal’ researcher?
The fundamental difference is the fact that I do work which underpins research and without which the research wouldn’t happen but isn’t necessarily publishable in its own right. Without the work carried out by the Research Software Engineer the papers wouldn’t get published but they don’t necessarily get the credit. The research gets the publication and the credit!
I often end up spending time doing lots of odds and ends that are significant in that they support researchers and facilitate research but aren’t really quantifiable in the sense of a research output.
The outputs of a RSE are different to a ‘normal’ researcher. For example, in performance review, the work done on outputting software isn’t one of the KPIs. I don’t fit the normal ‘money-in, papers-out’ model of many academics.
You’ve recently won an EPSRC RSE Fellowship – congratulations! Can you give a brief overview of your project?
The project is centred around TexGen software. This is open source software for generating 3D geometric models of textiles and textile composites The initial part of the project will be to develop a new major version of the software aimed at addressing the modelling requirements of the increasingly complex textiles and preforms used in composite materials. The project will identify new and emerging areas in textile technology and develop tools to meet the analysis needs of these new technologies and materials.
The Faculty have committed to fund a PhD student and a project has been proposed to research optimisation of 3D woven preforms with various cross-sectional shapes.
Also included in the proposal are elements surrounding programming education and outreach. I currently teach a MATLAB course for postgraduate students which is intended to be a conversion from other languages. The reality is that many of the students haven’t programmed before so the course could be split to better meet the needs of the varying requirements of the students.

How long did it take you to write your Fellowship application?
It was horrendous! It was really hard work. The Business development team in the Faculty were really helpful, giving very useful advice on how to write a proposal. It consumed all of my time for the weeks between acceptance of the intent to submit and the submission date.
One thing that really helped was that two weeks before the submission date, the Graduate School held a ‘Writing retreat’ – 3 days for research staff to ‘just write’. There was space set aside, refreshments, speakers/courses if you wanted them and one-to-one appointments available with a careers advisor and EndNote specialist. The research development team people came down for a couple of meetings but there was a no phones rule and we were encouraged to turn our email off.
Having academics who were willing to spend time reading (and rereading!) the proposal was really important, especially as it was the first proposal that I’d written. The first draft was shredded by one of them but in a way that was very positive.
Who are your project partners?
I don’t have any named on the proposal. For the last couple of years I have been a platform fellow for EPSRC Centre for Innovative Manufacturing in Composites (CIMComp) which has a large number of project partners, funding research projects underpinned by TexGen. It is anticipated that this collaboration will continue. Part of the aim of the project is also to seek out new project partners, particularly for areas of textile research other than composites.
Tell me about your RSE group.
We don’t have one at Nottingham! It’s just me. There are plans to identify other RSEs in the faculty to start building a community. Watch this space.
Which programming languages and technologies do you regularly use?
TexGen is written in C++ and has Python wrappers. A bit of MATLAB for teaching. OS – Windows. I work in Visual Studio and am comfortable in it.
TexGen is cross platform so I have to make sure it builds in Linux. It also makes use of open source libraries such as wxWidgets, SWIG, OpenCASCADE and VTK.
I tend to work on a ‘need to know’ basis, looking for new technologies when there’s a specific need. When you are the only person in a project, you don’t have the luxury of learning lots of technologies.
Are there any languages/technologies that you used to use a lot but have now moved away from? Why?
I used to use C but rarely use it anymore. I also did assembler many years ago. When I was an undergrad, I did a software engineering course that used PDP-11 assembler. It was the first time that the lecturer had taught the course and was incomprehensible! I got the textbooks out of the library and worked my way through them, discovering how much I enjoyed assembler programming in the process. On the back of that the lecturer invited me to do a PhD where I designed and built a filament winding machine. The control system was run from a PC using 286 assembler.
Is there anything on your ‘to-learn’ list?
Getting better at the Linux side of things. I can get by but I am aware that there is much that I don’t know and could learn much better from someone who’s expert at using it rather than hunting around myself to work out how to do things. There are people who run TexGen on the HPC system so I would like to be able to support them better.
I’m looking forward to becoming part of the RSE community and learning from the other members.
I was sat in a meeting recently where people were discussing High Performance Computing options. Someone had found some money down the back of the sofa and asked the rest of us how we’d spend it if it were ours (For the record, I wanted some big-memory nodes — 512Gb RAM minimum).
Halfway through the meeting someone asked about the parallel filesystem in use on Sheffield’s HPC systems and I answered Lustre — not expecting any further comment. I don’t know much about parallel I/O systems but I do know that all of the systems I have access to make use of Lustre. Sheffield’s Iceberg, Manchester’s Computational Shared Facility and the UK National supercomputer, Archer to name three. The Wikipedia page for Lustre suggests that it is very widely used in the HPC community worldwide.
I was surprised, then, when this comment was met with derision from some in the room. One person remarked ‘It’s a bit…um…classic..isn’t it?’, giving the impression that it was old and outdated. There was not much love for dear old Lustre it seemed!
There was no time in this meeting for me ask ‘What’s wrong with it then? Works fine for me!’so I did what I often do in times like this, I asked twitter:
Q for HPC followers. Is there anything wrong with using Lustre? Just been in a meeting where it was mocked as ‘classic’.
— Mike Croucher (@walkingrandomly) April 12, 2016
I found the responses to be very instructive so thought I would share them here. Here’s a comment from Ben Waugh
@walkingrandomly Lustre failures seem to be the main cause of downtime in my limited experience of large HPC systems.
— Ben Waugh (@benwaughuk) April 12, 2016
Not a great start! I’ve been hit by Lustre downtime too but, since I’m not a sysadmin, I haven’t got a genuine sense of how big a problem it is. It happens often enough that I’m aware of it but not so often that I feel the need to worry about it. Looking after large HPC systems is difficult and when one attempts to do do something difficult, the occasional failure is inevitable.
It seems that configuration might play a part in stability and performance. Peter Van Heusden kicked off with
@walkingrandomly Depending on the configuration can lack resilience, but is still standard HPC parallel FS.
— Peter van Heusden (@pvanheus) April 12, 2016
Adrian Jackson , Research Architect, HPC and Parallel Programmer, is thinking along similar lines.
@walkingrandomly 1/2 Yes, for a long time the metadata servers have not kept up, meaning you can destroy it with lots of small files
— Adrian Jackson (@adrianjhpc) April 12, 2016
@walkingrandomly 2/2 Although I believe this is being fixed in a variety of ways.
— Adrian Jackson (@adrianjhpc) April 12, 2016
@walkingrandomly Also, the default settings often don’t give best large scale performance, but that’s a matter of configuration
— Adrian Jackson (@adrianjhpc) April 12, 2016
Adrian also followed up with an interesting report on Performance of Parallel IO on ARCHER from June 2015. Thanks Adrian!
Glen K Lockwood is a Computational scientist specialising in I/O platforms at @NERSC, the flagship computing centre for the U.S. Dept. of Energy’s Office of Science. Glen has this insight,
@eoinbrazil @walkingrandomly Lustre just gets trashed because everyone uses it (because of its cost). Parallel file systems all misbehave
— Glenn K. Lockwood (@glennklockwood) April 12, 2016
I like this comment because it fits with my own, much less experienced, view of the parallel I/O world. A classic demonstration of confirmation bias perhaps but I see this thought pattern in a lot of areas. The pattern looks like this:
It’s hard to do ‘thing’. Most smart people do ‘thing’ with ‘foo’ and, since ‘thing’ is hard, many people have experienced problems with ‘foo’. Hence, people bash ‘foo’ a lot. ‘foo’ sucks!
Alternatives exist of course but there may be trade-offs. Here’s Mark Basham, software scientist @diamondlightsou in the UK.
@walkingrandomly we use it at Diamond for several of our file systems. GPFS is a bit better, but a lot more costly.
— Mark Basham (@basham_mark) April 12, 2016
I’ll give the final word to Nick Holway who sums up how I feel about parallel storage from a user’s point of view.
@walkingrandomly I like my HPC storage to be "classic" and also rather "boring"
— Nick Holway (@nickholway) April 12, 2016
The University of Sheffield recently purchased licenses for the Windows version of the Intel compiler suite and I’m involved in the release to campus process. As part of this, I wrote some basic documentation on how to compile Hello World using the Intel C++ Compiler within Visual Studio Community Edition 2015. Since this may be useful to people outside of University of Sheffield, I reproduce this part of our documentation here.
These notes were prepared using Intel C++ XE 2015 version 15.0.6 and Visual Studio Community Edition 2015 RTM version. Note that there are problems with using this version of Intel C++ and later versions of Visual Studio Community Edition.
Click on any of the images to see them full size.
- Launch Visual Studio and click on File->New Project
- Choose Visual C++ -> Win32 Console Application and give your project a name.

- In the Win32 Application wizard, untick Precompiled header and Security Development Lifecycle (SDL) checks and click Finish.
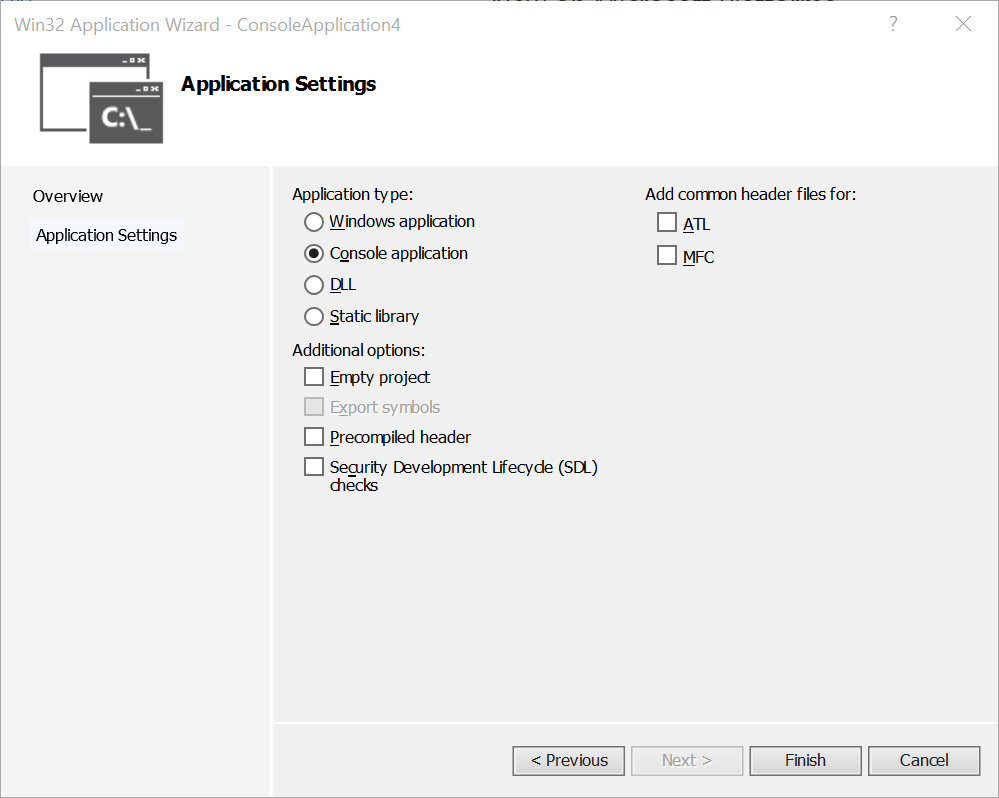
- A skeleton main() function will appear. Modify the code so that it reads
#include
int main()
{
std::cout << "Hello World";
return 0;
}
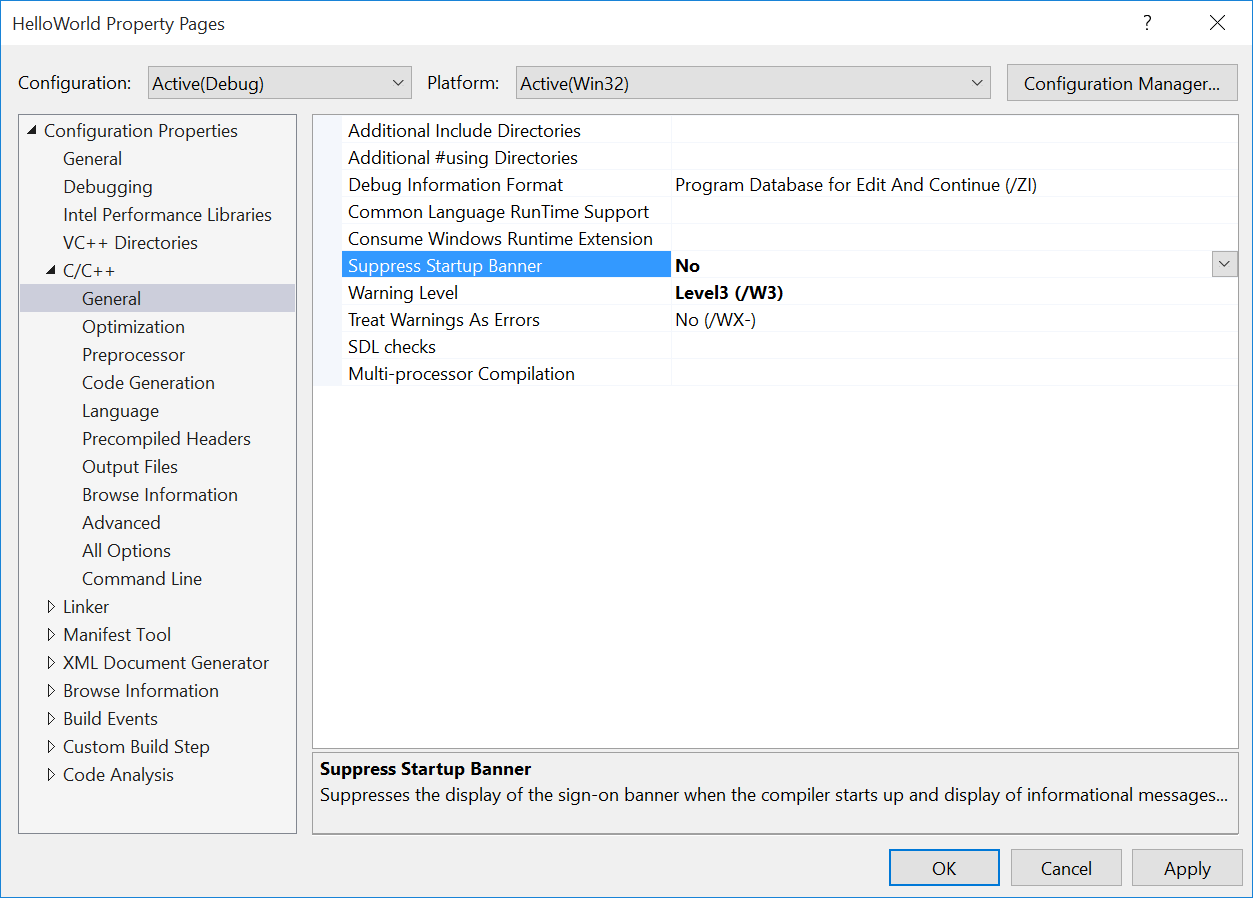
- Click on Project->HelloWorld Properties and under the C++ -> General section, ensure that Suppress Startup Banner is set to No and click OK. This will ensure that when you compile, you’ll be able to see that it’s the Intel Compiler doing the work rather than Visual Studio C++.
- Click on Project->Intel Compiler->Use Intel C++
- Build and run the code by pressing CTRL F5. You should see something like the following
>------ Build started: Project: HelloWorld, Configuration: Debug Win32 ------ 1> icl /Qvc14 "/Qlocation,link,C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin" /ZI /W3 /Od /Qftz- -D __INTEL_COMPILER=1500 -D WIN32 -D _DEBUG -D _CONSOLE -D _UNICODE -D UNICODE /EHsc /RTC1 /MDd /GS /Zc:wchar_t /Zc:forScope /FoDebug\ /FdDebug\vc140.pdb /Gd /TP HelloWorld.cpp stdafx.cpp 1> 1> Intel(R) C++ Compiler XE for applications running on IA-32, Version 15.0.6.285 Build 20151119 1> Copyright (C) 1985-2015 Intel Corporation. All rights reserved.
Once the compilation has completed, a console window should pop up showing the Hello World output.