
MATLAB GPU / CUDA experiences on my laptop – Elementwise operations on the GPU #1
This is part 1 of an ongoing series of articles about MATLAB programming for GPUs using the Parallel Computing Toolbox. The introduction and index to the series is at https://www.walkingrandomly.com/?p=3730.
Have you ever needed to take the sine of 100 million random numbers? Me either, but such an operation gives us an excuse to look at the basic concepts of GPU computing with MATLAB and get an idea of the timings we can expect for simple elementwise calculations.
Taking the sine of 100 million numbers on the CPU
Let’s forget about GPUs for a second and look at how this would be done on the CPU using MATLAB. First, I create 100 million random numbers over a range from 0 to 10*pi and store them in the variable cpu_x;
cpu_x = rand(1,100000000)*10*pi;
Now I take the sine of all 100 million elements of cpu_x using a single command.
cpu_y = sin(cpu_x)
I have to confess that I find the above command very cool. Not only are we looping over a massive array using just a single line of code but MATLAB will also be performing the operation in parallel. So, if you have a multicore machine (and pretty much everyone does these days) then the above command will make good use of many of those cores. Furthermore, this kind of parallelisation is built into the core of MATLAB….no parallel computing toolbox necessary. As an aside, if you’d like to see a list of functions that automatically run in parallel on the CPU then check out my blog post on the issue.
So, how quickly does my 4 core laptop get through this 100 million element array? We can find out using the MATLAB functions tic and toc. I ran it three times on my laptop and got the following
>> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.833626 seconds. >> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.899769 seconds. >> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.916969 seconds.
So the first thing you’ll notice is that the timings vary and I’m not going to go into the reasons why here. What I am going to say is that because of this variation it makes sense to time the calculation a number of times (20 say) and take an average. Let’s do that
sintimes=zeros(1,20);
for i=1:20;tic;cpu_y = sin(cpu_x);sintimes(i)=toc;end
average_time = sum(sintimes)/20
average_time =
0.8011
So, on average, it takes my quad core laptop just over 0.8 seconds to take the sine of 100 million elements using the CPU. A couple of points:
- I note that this time is smaller than any of the three test times I did before running the loop and I’m not really sure why. I’m guessing that it takes my CPU a short while to decide that it’s got a lot of work to do and ramp up to full speed but further insights are welcomed.
- While staring at the CPU monitor I noticed that the above calculation never used more than 50% of the available virtual cores. It’s using all 4 of my physical CPU cores but perhaps if it took advantage of hyperthreading I’d get even better performance? Changing OMP_NUM_THREADS to 8 before launching MATLAB did nothing to change this.
Taking the sine of 100 million numbers on the GPU
Just like before, we start off by using the CPU to generate the 100 million random numbers1
cpu_x = rand(1,100000000)*10*pi;
The first thing you need to know about GPUs is that they have their own memory that is completely separate from main memory. So, the GPU doesn’t know anything about the array created above. Before our GPU can get to work on our data we have to transfer it from main memory to GPU memory and we acheive this using the gpuArray command.
gpu_x = gpuArray(cpu_x); %this moves our data to the GPU
Once the GPU can see all our data we can apply the sine function to it very easily.
gpu_y = sin(gpu_x)
Finally, we transfer the results back to main memory.
cpu_y = gather(gpu_y)
If, like many of the GPU articles you see in the literature, you don’t want to include transfer times between GPU and host then you time the calculation like this:
tic gpu_y = sin(gpu_x); toc
Just like the CPU version, I repeated this calculation several times and took an average. The result was 0.3008 seconds giving a speedup of 2.75 times compared to the CPU version.
If, however, you include the time taken to transfer the input data to the GPU and the results back to the CPU then you need to time as follows
tic gpu_x = gpuArray(cpu_x); gpu_y = sin(gpu_x); cpu_y = gather(gpu_y) toc
On my system this takes 1.0159 seconds on average– longer than it takes to simply do the whole thing on the CPU. So, for this particular calculation, transfer times between host and GPU swamp the benefits gained by all of those CUDA cores.
Benchmark code
I took the ideas above and wrote a simple benchmark program called sine_test. The way you call it is as follows
[cpu,gpu_notransfer,gpu_withtransfer] = sin_test(numrepeats,num_elements]
For example, if you wanted to run the benchmarks 20 times on a 1 million element array and return the average times then you just do
>> [cpu,gpu_notransfer,gpu_withtransfer] = sine_test(20,1e6)
cpu =
0.0085
gpu_notransfer =
0.0022
gpu_withtransfer =
0.0116
I then ran this on my laptop for array sizes ranging from 1 million to 100 million and used the results to plot the graph below.
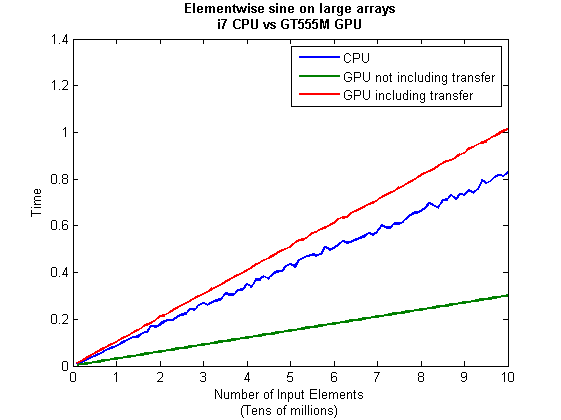
But I wanna write a ‘GPUs are awesome’ paper
So far in this little story things are not looking so hot for the GPU and yet all of the ‘GPUs are awesome’ papers you’ve ever read seem to disagree with me entirely. What on earth is going on? Well, lets take the advice given by csgillespie.wordpress.com and turn it on its head. How do we get awesome speedup figures from the above benchmarks to help us pump out a ‘GPUs are awesome paper’?
0. Don’t consider transfer times between CPU and GPU.
We’ve already seen that this can ruin performance so let’s not do it shall we? As long as we explicitly say that we are not including transfer times then we are covered.
1. Use a singlethreaded CPU.
Many papers in the literature compare the GPU version with a single-threaded CPU version and yet I’ve been using all 4 cores of my processor. Silly me…let’s fix that by running MATLAB in single threaded mode by launching it with the command
matlab -singleCompThread
Now when I run the benchmark for 100 million elements I get the following times
>> [cpu,gpu_no,gpu_with] = sine_test(10,1e8)
cpu =
2.8875
gpu_no =
0.3016
gpu_with =
1.0205
Now we’re talking! I can now claim that my GPU version is over 9 times faster than the CPU version.
2. Use an old CPU.
My laptop has got one of those new-fangled sandy-bridge i7 processors…one of the best classes of CPU you can get for a laptop. If, however, I was doing these tests at work then I guess I’d be using a GPU mounted in my university Desktop machine. Obviously I would compare the GPU version of my program with the CPU in the Desktop….an Intel Core 2 Quad Q9650. Heck its running at 3Ghz which is more Ghz than my laptop so to the casual observer (or a phb) it would look like I was using a more beefed up processor in order to make my comparison fairer.
So, I ran the CPU benchmark on that (in singleCompThread mode obviously) and got 4.009 seconds…noticeably slower than my laptop. Awesome…I am definitely going to use that figure!
I know what you’re thinking…Mike’s being a fool for the sake of it but csgillespie.wordpress.com puts it like this ‘Since a GPU has (usually) been bought specifically for the purpose of the article, the CPU can be a few years older.’ So, some of those ‘GPU are awesome’ articles will be accidentally misleading us in exactly this manner.
3. Work in single precision.
Yeah I know that you like working with double precision arithmetic but that slows GPUs down. So, let’s switch to single precision. Just argue in your paper that single precision is OK for this particular calculation and we’ll be set. To change the benchmarking code all you need to do is change every instance of
rand(1,num_elems)*10*pi;
to
rand(1,num_elems,'single')*10*pi;
Since we are reputable researchers we will, of course, modify both the CPU and GPU versions to work in single precision. Timings are below
- Desktop at work (single thread, single precision): 3.49 seconds
- Laptop GPU (single precision, not including transfer): 0.122 seconds
OK, so switching to single precision made the CPU version a bit faster but it’s more than doubled GPU performance. We can now say that the GPU version is over 28 times faster than the CPU version. Now we have ourselves a bone-fide ‘GPUs are awesome’ paper.
4. Use the best GPU we can find
So far I have been comparing the CPU against the relatively lowly GPU in my laptop. Obviously, however, if I were to do this for real then I’d get a top of the range Tesla. It turns out that I know someone who has a Tesla C2050 and so we ran the single precision benchmark on that. The result was astonishing…0.0295 seconds for 100 million numbers not including transfer times. The double precision performance for the same calculation on the C2050 was 0.0524 seonds.
5. Write the abstract for our ‘GPUs are awesome’ paper
We took an Nvidia Tesla C2050 GPU and mounted it in a machine containing an Intel Quad Core CPU running at 3Ghz. We developed a program that performs element-wise trigonometry on arrays of up to 100 million single precision random numbers using both the CPU and the GPU. The GPU version of our code ran up to 118 times faster than the CPU version. GPUs are awesome!
Results from different CPUs and GPUs. Double precision, multi-threaded
I ran the sine_test benchmark on several different systems for 100 million elements. The CPU was set to be multi-threaded and double precision was used throughout.
sine_test(10,1e8)
GPUs
- Tesla C2050, Linux, 2011a – 0.7487 seconds including transfers, 0.0524 seconds excluding transfers.
- GT 555M – 144 CUDA Cores, 3Gb RAM, Windows 7, 2011a (My laptop’s GPU) -1.0205 seconds including transfers, 0.3016 seconds excluding transfers
CPUs
- Intel Core i7-880 @3.07Ghz, Linux, 2011a – 0.659 seconds
- Intel Core i7-2630QM, Windows 7, 2011a (My laptop’s CPU) – 0.801 seconds
- Intel Core 2 Quad Q9650 @ 3.00GHz, Linux – 0.958 seconds
Conclusions
- MATLAB’s new GPU functions are very easy to use! No need to learn low-level CUDA programming.
- It’s very easy to massage CPU vs GPU numbers to look impressive. Read those ‘GPUs are awesome’ papers with care!
- In real life you have to consider data transfer times between GPU and CPU since these can dominate overall wall clock time with simple calculations such as those considered here. The more work you can do on the GPU, the better.
- My laptop’s GPU is nowhere near as good as I would have liked it to be. Almost 6 times slower than a Tesla C2050 (excluding data transfer) for elementwise double precision calculations. Data transfer times seem to about the same though.
Next time
In the next article in the series I’ll look at an element-wise calculation that really is worth doing on the GPU – even using the wimpy GPU in my laptop – and introduce the MATLAB function arrayfun.
Footnote
1 – MATLAB 2011a can’t create random numbers directly on the GPU. I have no doubt that we’ll be able to do this in future versions of MATLAB which will change the nature of this particular calculation somewhat. Then it will make sense to include the random number generation in the overall benchmark; transfer times to the GPU will be non-existant. In general, however, we’ll still come across plenty of situations where we’ll have a huge array in main memory that needs to be transferred to the GPU for further processing so what we learn here will not be wasted.
Hardware / Software used for the majority of this article
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit. I’m not using Linux because of the lack of official support for Optimus.
- MATLAB: 2011a with the parallel computing toolbox
Other GPU articles at Walking Randomly
- GPU Support in Mathematica, Maple, MATLAB and Maple Prime – See the various options available
- Insert new laptop to continue – My first attempt at using the GPU functionality in MATLAB
- NVIDIA lets down Linux laptop users – and how an open source project saves the day
Thanks to various people at The Mathworks for some useful discussions, advice and tutorials while creating this series of articles.
Great article! I laughed hard at the “GPUs are awesome!” process xD
CUDA developer here, and writer of some of those “GPUs are awesome!” papers. A couple issues…
I don’t believe using a transcendental function is really an appropriate metric here, for reasons of the actual GPU hardware. A 2.x CUDA multiprocessor has 32 “cores”, but only 4 units for transcendentals. I think you’ve inadvertently targeted a weakness of the hardware.
Regarding transfer time, I appreciate the point you’re trying to make. However, most papers in the field are targeting extremely intense computational work. Generally, a very large amount of computation is done on a very large amount of data. If every single function in a CUDA-accelerated program had a cpu->gpu->cpu transfer associated with it (as in your benchmark), it would be an extremely poor use of the equipment for the reasons specified. Using such a trivial example of a single function strikes me as poor metric for devices that are of interest for replacing/augmenting supercomputers, not laptops.
@Anon Thanks for your comments which I’ll do my best to address.
I didn’t know that GPUs were weak at transcendental functions until I read your comment. I feel that it was worth writing this article for me to learn that piece of information alone so thank you! I think it’s definitely an appropriate metric if your algorithm is heavy on such functions! Surely we shouldn’t target our measurements only on measurements that play to the hardware’s strengths?
As for transfer time, I merely wanted to point out that it is a factor to consider. Your comment ‘If every single function in a CUDA-accelerated program had a cpu->gpu->cpu transfer associated with it (as in your benchmark), it would be an extremely poor use of the equipment for the reasons specified. ‘ is pretty much the point I’m trying to make.
You infer that GPUS are ‘of interest for replacing/augmenting supercomputers, not laptops’ I think they are of interest to both supercomputer AND laptop users. If a researcher can do all of their computation on their laptop then they won’t need a traditional HPC supercomputer. They will effectively have a ‘personal supercomputer’ which is the whole point isn’t it?
Using such a trivial example IS a poor metric but then so are all benchmarks and you have to start somewhere. I believe that benchmarks should prove a point and I believe that this one has. One of the things it has proved is ‘Make sure that your computation is meaty enough to make it WORTH transferring to the GPU’
This article is the first in a series…the index to them is at
http://www.walkingrandomly.com/?p=3730
I have no anti or pro-gpu agenda here…All I am interested in is learning about (and demonstrating) when they are useful and when they are not. I’ll be using many more metrics as I go. Some of them will be trivial, some more involved. Ideally all of them will prove a point. I value any suggestions from more experienced CUDA programmers such as yourself.
You may ask why I picked on this particular example and the simple answer is ‘It’s the first thing I tried’. I was disappointed with the results and worked to get to the bottom of why.
Finally, one may ask ‘Why focus on a laptop?’ My answer to that is that many people are going out and buying laptops to ‘give GPU computing a go’ and if they get crappy performance then it may put them off the whole thing.
Cheers,
Mike
Regarding the cpu usage, it probably makes sense that matlab would only spawn one thread per physical core. Hyperthreading allows for faster switching between multiple threads but does not buy you any additional floating point horsepower . . . the floating point logic is shared among all threads on a single core.
There are more comments to this post over at Hacker News
http://news.ycombinator.com/item?id=2817918
This is better titled “How To Write Horrible GPU Code for Dummies”
There are all sorts of strawman ways to make any piece of hardware look bad. For GPUs, uploading data to the GPU, then performing a short calculation, and then copying it back is just the beginning.
So let me suggest how to improve on this masterwork because I think it would rock if Charlie Demerjian were to read this and use it as the basis of one of his meth-induced rants about NVIDIA’s pending demise: write some CUDA code that does entirely random reads of system memory (not GPU memory no no no anything but 120+ GB/s bandwidth GPU memory) which it then uses as the basis of a cascade of divergent if/then decisions, and finally issues GPU printf to display the results from a single tabulator filled up with atomic ops. Oh and don’t forget to *require* the code to run 1,536 threads per processor because, ya know, more threads buries latency and all that.
Meanwhile, those in the know about what GPUs can and cannot do will continue doing their thing. Like anything else, when they’re the right tool for the right job, they rock.
@GPUJunkie did you read ALL of the article or just the bits that justify your rant? Part of the point of it, and those that are due to follow it, is to demonstrate the pitfalls of coding for the gpu. Did you read the conclusions for example? Perhaps the bit that says ‘the more work you can do on the GPU the better because otherwise transfer times dominate’?
I guess not.
In the Hacker News thread, someone pointed the following superb article ‘Debunking the 100X GPU vs. CPU Myth:’
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.170.2755&rep=rep1&type=pdf
Have you considered trying an OpenCL GPU (i.e.: AMD)? They traditionally have far more stream processors than CUDA GPUs. Don’t know much about MATLAB though. Just a thought.
@Mike Croucher
I didn’t think anyone in the HPC community actually took that Intel paper seriously. A common response to that piece of work is something along the lines of “it’s not often a competitor goes to such effort to show that their product is merely 2.5x worse.”
For them to use much higher-level CUDA C code to compare to the very highly tuned MKL libraries while simultaneously accusing authors of comparing unoptimized CPU code to highly-optimized GPU code strikes me as bogus. Quotes like:
are hard not to laugh at. Like so many other researchers, I’m a scientist/engineer in my field first, and a programmer second. CUDA enables me to write very fast, very efficient code, without an extremely high level of knowledge in the hardware details. If Intel’s own engineers (whom I’d assume are very good at this kind of thing) have to go through great pains in code optimization only to get 1/5th the performance, I think it speaks volumes.
As far as your response regarding using transcendentals… sure, we shouldn’t just target the device’s strengths. But that particular test is definitely a fringe case; worse case scenario.
Regarding transfer time and using large systems… all GPU developers are aware of this bottleneck. It’s quite well documented even in the original CUDA programming guide. Particularly in HPC, getting large enough amounts of data to make good use of the GPU (and not have to be constantly transferring) is rarely a problem. In numerical codes I’ve worked on, it was generally the case to have full GPU utilization between minutes and days without any transfer to cpu on a desktop (compared to a similar amount of time for a well optimized CPU code on large HPC systems).
Lastly, I’d be interested if you redid the same test, but in more native CUDA C and CPU-C versions, and see if you had similar results. I’m not sure how MATLAB’s new acceleration handles everything behind the scenes. It’d be nice to remove that variable.
@Anon I agree that Intel’s paper smacks of defensiveness and you are right..if an amateur on one hardware can beat experts on another then the former hardware is worth having.
Regarding transcendentals, your information has informed the next article in this series which I am currently working through. I’ll be keeping my original demo but adding another, similar one, that avoids transcendentals.
Transfer times…yes, they only matter for simple calculations for this one or when the code in question has to interact with the CPU a lot. That was part of the point of this part #1…I show an elementwise example where transfer times dominate and then move on to one where it doesn’t and the GPU wins. Moral? Keep transfer times to a minimum.
This article is for GPU beginners using the new MATLAB functionality so I didn’t want to rely on assuming some information that all GPU developers are aware of.
If you were to consider the sine_test as a single benchmark by which to judge GPUs then you are right…it is unfair. That wasn’t my intention though. My intention is to have it as the first of many tests..essentially an excuse for me to explore the do’s and don’ts of GPU coding.
I also wanted to show how one could take a negative result for GPUs and turn it into a positive result via various transformations. The idea being to inform people who read the literature that we shouldn’t take everything at face value. See my comment at http://www.walkingrandomly.com/?p=3730#comment-86454 for the background as to why I wanted to do this.
The Mathworks have written an article that compares their automatic acceleration with natice CUDA C. Native CUDA C is around a factor of 2 faster than the MATLAB code in the example given http://blogs.mathworks.com/loren/2011/07/18/a-mandelbrot-set-on-the-gpu/
@Brett Sure I’ve considered using other GPUs but the one on my laptop is the only one I can afford :) I’ve got access to a Tesla via colleagues and a few other NVidia cards but that’s about it.
MATLAB doesn’t support OpenCL yet but it should be relatively easy to write an OpenCL function that interfaces with MATLAB via the mex interface.
So after all this discussion my conclusion is that:
until some gurus from intel and nvidia handwrite, in assembly code specifically for each platform, a compehensive set of benchmarks, designed from neutral arbiters, no one will ever know if GPUs are faster or slower than CPUs…
and a personal comment:
I am not Perelman or Kalman or Feynman but from my small scientific experience I believe that computational efficiency in transcendental function calculation is not such a bad choice for a benchmark…
In addition to the above remarks, one can dismiss the Intel paper as utter garbage from the get-go just from the starting premise of comparing a 7-month old CPU (Core I7-960) to a 2+ year-old GPU at the time of its presentation. That’s an entire iteration of Moore’s Law between them. For the record, the correct GPU to compare against at that time would have been a GTX480.
However, unapologetically venturing into strawman territory, I suspect the authors realized they’d need to rewrite all their code to take advantage of the GTX480’s features and opted not to do so. But even then, the least they could have done was to use the 20% faster but otherwise-identical GTX285. But wait, this is Intel (not some lonely professor in some obscure unfunded community college), no excuses, this is pure FUD.
Second, the ridiculous hubris of assuming 12 Intel engineers can write the best implementations possible for 14 algorithms on a competitor’s GPU hardware is just daffy. Moving on…
The only fact is that GPUs are cheaper than CPUs that have equivelant processor power, that’s why nowdays they are used in arrays as cheap supercomputers.
In terms of raw ALU throughput and memory bandwidth, GPUs are generally have about a five-fold advantage over comparable CPUs. So, for well-written code that executes with high efficiency on a GPU, one can gain perhaps a factor of 4 (efficiency over 80% is rather uncommon) over a CPU. That’s great, until you compare in terms of performance-per-watt (the real metric for HPC) and realise that the GPU uses at least three times the power the CPU does. Taken together with the difficulty in programming them efficiently and the fact that so little memory, comparatively speaking, is available on current GPU boards, this advantage begins to look rather marginal. For this reason, applications that target GPUs really ought to be looking to take advantage of fixed-function units (such as texture samplers and interpolation hardware) that are missing in CPUs and which can give an overwhelming (hundred-fold, say) advantage to codes that can use them efficiently.
I’d also like to add that taking sines is hardly optimal for either type of hardware; while as already mentioned GPUs have few transcendental units, CPUs have none at all and therefore have a low throughput for these types of operations. Do something that exercises only the multiply and add units–taking the dot product of the 100 million element vector of random numbers with itself, say–and you will see dramatically better performance, much nearer the peak of their respective capabilities, from both the CPU and the GPU.
“In terms of raw ALU throughput and memory bandwidth, GPUs are generally have about a five-fold advantage over comparable CPUs. So, for well-written code that executes with high efficiency on a GPU, one can gain perhaps a factor of 4 (efficiency over 80% is rather uncommon) over a CPU. That’s great, until you compare in terms of performance-per-watt (the real metric for HPC) and realise that the GPU uses at least three times the power the CPU does.”
Inaccurate on the first count and nonsense on the second.
A GTX580 can fire off 512 instructions per cycle. That times 1.54 GHZ is ~790 GInstructions per second.
Meanwhile, Intel’s brand-new shiny quad-core Sandybridge CPUs can fire 4 cores * 8-way SIMD * 3 GHZ == 72 GInstructions per second. That’s slightly better than 10x.
Second, referring you to the link from the other thread:
http://insidehpc.com/2011/07/23/report-gpus-deliver-10x-molecular-dynamics-acceleration-75-energy-reduction-on-tsubame2-0/
The GPU cluster in question eats 1/4 the power of the CPU Cluster for an equivalent computation on a real app in use by tens of thousands of biologists and chemists around the world.
Now let’s move on to ease of programming. Sure, CUDA and OpenCL are harder than C/C++/FORTRAN 90. No disagreement there, but I’m not letting you off easy on this one.
How many scientists (and even computer scientists) out there are capable of writing efficient SSE code to get anywhere close to the CPU numbers above? And beyond that, how many of them understand OpenMP and MPI sufficiently to parallelize their code? Very few of them that I know even grok what it takes to make code maximize use of L1 cache. Yes, this is a strawman. But I work with them daily and I see this pattern again and again.
For these sorts, learning CUDA at even a basic level allows them to abstract away multi-threading and SIMD. Their codes usually make horrible use of GPU L1, but 2 out of 3 is pretty cool in my book.
Can we please come up with some new and improved FUD instead of repeating AMD and Intel white paper nonsense from 2007?
“Inaccurate on the first count and nonsense on the second.
A GTX580 can fire off 512 instructions per cycle. That times 1.54 GHZ is ~790 GInstructions per second.
Meanwhile, Intel’s brand-new shiny quad-core Sandybridge CPUs can fire 4 cores * 8-way SIMD * 3 GHZ == 72 GInstructions per second. That’s slightly better than 10x.”
While I will not disagree with your numbers (perhaps I should have said five- to ten-fold advantage to avoid this sort of argument), I will remind you that I said “comparable”. The GTX580 costs 40% more and uses two and a half times the amount of power relative to a 3.4GHz Sandy Bridge 2600K. So the advantage is not as great as it at first seems, though perhaps still a bit more than fivefold depending on your preferred metric.
As to “nonsense”, you will note that I did indeed mention that specific applications can make hundred-fold gains (or 40-fold, as in this case) if the types of operation they require map particularly well onto hardware such as texture samplers that exists only in GPUs. This is great for molecular dynamics, but if you think this applies to HPC in general then you are simply dreaming. I’ve yet to see any electronic structure, QCD, finite element, Poisson, CFD, etc. codes offering such dramatic gains. At best they seem to get 5-10 times the performance in exchange for over twice the power, which is equivalent to maybe three years’ (on the outside) head-start against Moore’s law, at the cost of totally rewriting the codes. To many researchers, this is not worth it–which is, of course, definitively not a claim that it is not worth it to anyone regardless of their application.
Regarding achievable performance: of course I expect that people will use ports of BLAS/LAPACK/FFTW/ARPACK/QUADPACK/whatever rather than writing the code themselves. But can you show me one of these that manages anywhere near a decent level of hardware utilization on a GPU for large numbers of small or medium-sized inputs? Not all HPC applications, by far, rely on or are anything even remotely comparable algorithmically to 10,000 by 10,000 DGEMM (and Amdahl’s law still counts for something, too). If your application borders on embarrassingly parallel, more power to you–but it’s not an excuse for alleging that anyone with different requirements is motivated only by some rabid desire to slander GPUs.
That it’s slower in the case you are piping the data to the graphics card and back again is not interesting. The typical uses I have for the thing is when computation takes TENS to HUNDREDS of seconds E.g. mldivide/mrdivide of big problems. The time lost due to the transfer is then trivial.
Using a hacked version of the example code for mldivide I ran their benchmark using the gpuArrray and gather method tic-tocing around the code. The speed up for 8192×8192 random matrix GPU computation over the CPU:
single: 3.9x->3.3x
double: 3x->2.8x
That being said I’m not 100% sure how matlab treats reused variables when you move the memory back and forth from the graphics card, that may be a factor in the lack of impact. Further, I’m running an i7-920 w/2GB GTX560Ti using a x58 chipset pipeline. If you are using Sandy Bridge it may be that your “tiny” pipeline is exacerbating the transfer problem, same goes for the i7-880 which has P55 (if memory serves). It may be that GPUs are awesome if you don’t skimp out on your computer :P.
Apologies but I found the relevant page on wiki
http://en.wikipedia.org/wiki/List_of_device_bandwidths#Main_buses
@Jagang Funny you should mention mldivide, that’s coming in a future article :)
As for ‘It may be that GPUs are awesome if you don’t skimp out on your computer’, so what you’re saying is that expensive computers are better than cheap ones? Who’d have thought it ;)
In all seriousness though, I agree with you. Data transfer becomes increasingly irrelevant as the size of your computation increases.
@Ben
“As to “nonsense”, you will note that I did indeed mention that specific applications can make hundred-fold gains (or 40-fold, as in this case) if the types of operation they require map particularly well onto hardware such as texture samplers that exists only in GPUs.”
What it boils down to is whether a problem can be broken down into task parallel chunks and whether each of those chunks can be processed in an efficient data-parallel manner. If you hit just one or these requirements, you’ll see 2-5X. If you hit them both, you get 10-100x. Molecular Dynamics does hit them both, hard. What confuses the matter here is that the optimal way to program hardware like this is by paying more attention to what it actually does than to what either of the major languages (CUDA/OpenCL) recommend. Their suggestions are valid because the underlying hardware changes remain brutal between generations, but one sacrifices a lot of attainable performance by doing so.
“Regarding achievable performance: of course I expect that people will use ports of BLAS/LAPACK/FFTW/ARPACK/QUADPACK/whatever rather than writing the code themselves. But can you show me one of these that manages anywhere near a decent level of hardware utilization on a GPU for large numbers of small or medium-sized inputs? Not all HPC applications, by far, rely on or are anything even remotely comparable algorithmically to 10,000 by 10,000 DGEMM (and Amdahl’s law still counts for something, too). If your application borders on embarrassingly parallel, more power to you–but it’s not an excuse for alleging that anyone with different requirements is motivated only by some rabid desire to slander GPUs.”
And this is a problem wherein the libraries for these tasks were designed around solving one big problem across the entire GPU (which sucks for small FFTs/matrices) and only secondarily for addressing batches. And that’s because the primary benchmark, LINPACK, is a paradise for optimizing weak over strong scaling and it’s focused on big matrices. And it’s not just matrix math: until CUDA 3.2, GPU FFTs on non power of 2 dimensions were godawful (as in 10x less efficient than powers of 2). Now they’re 80-90% the efficiency of powers of 2. Why? Because FFT benchmarks always focus on power of 2 dimensions.
There’s still lots of room for improvement here. That doesn’t excuse the state of these libraries, but it’s also not a valid indicator that GPUs can’t do a lot better here. The question this really raises to me is if there’s a big enough market for this, would it be worth fixing it as a 3rd party? Or should EM Photonics fix this and add it to their suite of products?
Just started working on GPUs and found your site.
On a laptop running a core i7 @ 2.8GHz dual core CPU, I get an average of 0.1634s.
With the built in Nvidia NVS 4200M processor, I’m seeing 0.1040s and 0.1268s for without and with memory transfer, respectively.
Using only 10M elements due to a lack of memory.
A pretty modest improvement.
Substituting the sin with a log function, the cpu averages around 0.2025s. The gpu gets about 0.0775s and 0.1435s, for without and with memory transfer.
Not sure why the memory transfer time in the second case is so much longer for log compared to sin? Is there another factor affecting the times here?
Maybe you could update this article now that you can generate the cpu_x array directly on the GPU using gpuArray.rand? The discussion about transfer timing is altered.
Hi Eric
I don’t think I’ll update the original but will write new articles instead. Leave this as a record of the way things were.
Cheers,
Mike