
Search Results
I have just installed SAGE 3.2 on my Ubuntu 8.10 machine and received the following error message.
It looks like jsMath failed to set up properly (error code -7). I will try to keep going, but it could get ugly.
I discovered a forum thread that suggested that installing jsmath-fonts would fix the problem
apt-get install jsmath-fonts
but, unfortunately, it didn’t. I found that I also had to install ttf-jsmath
apt-get install ttf-jsmath
A quick restart of firefox later and SAGE looked very pretty indeed!
Regular readers of this blog will know that I have been keeping an eye on the open source mathematics package, SAGE, but have never really had time to take a closer look at it. A couple of things happened recently that made me find time to sit down and have a play with this extremely promising piece of software.
First of all I discovered that the developers of SAGE have been implementing a command called interact which is essentially a free version of the Mathematica command Manipulate. I love tinkering with Manipulate and so this open source alternative proved to be very tempting. Secondly, the developers of Sage recently released version 3.0 and, usually, a .0 release signifies a major milestone in development.
So first things first. What exactly is SAGE? In my opinion, the easiest way to sum up the answer to this question is to quote the projects mission statement which is
“Creating a viable free open source alternative to Magma, Maple, Mathematica, and Matlab.
No small task! I have access to three of the four CAS systems that SAGE has chosen to compare itself with and they are all extremely powerful (not to mention expensive) applications backed by large, well funded development teams. Not content with taking just on just one of them – SAGE has chosen to compete with all four at the same time!
Free maths packages are nothing new of course – there are several good quality, regularly updated open-source packages that one could choose from. For example we have
- Octave – A numeric-centric application that aims to be source-compatible with the base version of Matlab
- Maxima – A more symbolic-centric package than Octave that is an open source development of the old commercial Macsyma code.
- Scilab – Another numeric-centric package that has similar functionality to Matlab but it does not aim to be source compatible in any way.
We also have YACAS, Mathomatic, PARI/GP, GAP, R, Singular and GINAC among others – some of which are very well known in various academic disciplines. So what makes SAGE different?
SAGE is a car
The first major thing I noticed when reading about SAGE is that its developers realised that there is a lot of good code in packages such as Maxima and it would take a long time to develop equivalent levels of functionality from scratch. So, to paraphrase their slogan, rather than re-inventing the wheel they built a car.
In other words they did not try to compete with Maxima by re-implementing its algorithms – they simply included the entire Maxima executable with the base install of SAGE and wrote a SAGE-Maxima interface. So that’s one of the wheels of the car for a start.
For the other wheels they included GAP, PARI and Singular with SAGE so you immediately have access to four different systems from one standard interface – that’s a lot of funtionality. Continuing with the car metaphor I guess we have Python as the engine along with the statistical package, R, as um..the doors? You also have GMP (multi-precision arithmetic), Matplotlib (2d plotting), Tachyon3d (3d plotting) and lots more!
You don’t have to stop with just these included systems if you don’t want to. For example, if you have a copy of Octave on your machine then you can also call that from inside SAGE. Apparently you can even use commercial packages such as Mathematica or Maple although I have yet to try this out myself.
Of course, SAGE is much more than just an interface to existing systems – the developers have also written 250,000 lines of new, SAGE specific code, that adds to this plethora of functionality.
This isn’t just any old car – this is a car with all the optional extras. That gets constantly upgraded. For free!
SAGE uses Python
The next thing about SAGE that stood out for me is the fact that you use the Python scripting language to interact with it. I already know some Python and so, without needing to learn a thing, I already know how to use large parts of SAGE.
SAGE’s use of Python doesn’t just provide a shallower learning curve for Pythonistas, there are a great many other benefits too. In particular, the use of Python gives SAGE access to all of the routines of the extensive numerical library numpy along with the plotting library, matplotlib. These two Python libraries alone provide a reasonable amount of matlab-like functionality before you start considering everything else in the SAGE system.
SAGE has a great user interface
Its been a while since I used any of the other open source maths packages in anger so what I am about to say might be a bit out of date but in general it seems that their user interfaces are a bit, well…primitive. Many of them look just like a terminal prompt with a graphics output window. This is all well and good but when you are used to the pretty, notebook-like interfaces in Mathematica or Maple they all look very last-century.
SAGE uses your web browser as its notebook-like interface and I think it looks great. Here is an example of it in use (shamelessly stolen from here)

Of course you can still use it in good, old fashioned terminal mode if you really want to :)
SAGE has the interact function
SAGE is first and foremost a tool written by researchers for research and so it contains a lot of very advanced mathematics. For example the lead developer, Willian Stein, is very pleased about the fact that SAGE includes code for computing with modular abelian varieties. Now I wouldn’t know what a modular abelian variety was if it hit me over the head (I would welcome an idiot’s guide by anyone willing to write one) but I am sure that this code is very important to those who work with them.
So, bearing in mind that the SAGE developers have worked very hard to include all of this cutting edge functionality, I would like to apologise to them in advance for the fact that the piece of SAGE that really got me interested was the interact command – something that many people may well find frivolous.
In a nutshell interact offers similar functionality to Mathematica’s Manipulate command which I am a HUGE fan of. If you are new here and have no idea why the Manipulate command is so wonderful – check out the Wolfram Demonstrations Project and note that without Manipulate, the project would not exist.
In the second part of this blog post (coming in a few days) I will give you an idea why I think the interact command is so wonderful, what you can do with it and how to use it along with some comparisons with the Manipulate command of SAGE’s competitor, Mathematica. If you can’t wait for me to write the next post and want to see some interact examples right now then check out the interact page on the SAGE wiki.
If you enjoyed this article, feel free to click here to subscribe to my RSS Feed.
Version 3.0 of the open-source maths package, SAGE Math, was released yesterday. I have been fiddling with SAGE a bit from time to time and it looks like a great piece of software but I am yet to get my hands properly dirty with it. At work I have just gained access to Maple 11, Origin 8 and COMSOL 3.4 as well as an 8 core Mac-pro and a new dual core Linux machine so my plate is pretty full right now. So many toys….so little time :(
In Matlab if you type the command
whos
then you will get a detailed list of all of the variables in the current workspace which is often very useful. The equivalent command in SAGE-Math is
show_identifiers()
I hope someone finds this useful.
Interesting times lie ahead for Sage Math I think! This is definitely an application worth keeping an eye on.
A new version of SAGE was released yesterday. There are no new features but it does fix a couple of bugs.
At the moment I am writing an introductory Mathematica course and was recently looking for inspiration for potential exercises. One website I came across (I have lost the link unfortunately) suggested that you get something interesting looking if you plot the following equation over the region -3<x<3, -5<y<5. It also suggested that you should only plot the z values in the range 0<z<0.001.

Suitably intrigued, I issued the required Mathematica commands and got the plot below which spoke to me in a way that no equation ever has before.

So now I have a question – What other messages could one find hidden inside equations like this? For example, is it possible to generate a three letter word with a relatively simple equation such as the one above? Of course if you were allowed to use very complex equations (and make use of Fourier transforms maybe) then I guess you could spell out whatever you choose but that’s no fun.
If anyone finds other such messages in simple(ish) equations then please let me know.
Feel free to discuss and contribute to this article over at the corresponding GitHub repo.
Many people suggest that you should use version control as part of your scientifc workflow. This is usually quickly followed up by recommendations to learn git and to put your project on GitHub. Learning and doing all of this for the first time takes a lot of effort. Alongside all of the recommendations to learn these technologies are horror stories telling how difficult it can be and memes saying that no one really knows what they are doing!

There are a lot of reasons to not embrace the git but there are even more to go ahead and do it. This is an attempt to convince you that it’s all going to be worth it alongside a bunch of resources that make it easy to get started and academic papers discussing the issues that version control can help resolve.
This document will not address how to do version control but will instead try to answer the questions what you can do with it and why you should bother. It was inspired by a conversation on twitter.
Improvements to individual workflow
Ways that git and GitHub can help your personal computational workflow – even if your project is just one or two files and you are the only person working on it.
Fixing filename hell
Is this a familiar sight in your working directory?
mycode.py
mycode_jane.py
mycode_ver1b.py
mycode_ver1c.py
mycode_ver1b_january.py
mycode_ver1b_january_BROKEN.py
mycode_ver1b_january_FIXED.py
mycode_ver1b_january_FIXED_for_supervisor.pyFor many people, this is just the beginning. For a project that has existed long enough there might be dozens or even hundreds of these simple scripts that somehow define all of part of your computational workflow. Version control isn’t being used because ‘The code is just a simple script developed by one person’ and yet this situation is already becoming the breeding ground for future problems.
- Which one of these files is the most up to date?
- Which one produced the results in your latest paper or report?
- Which one contains the new work that will lead to your next paper?
- Which ones contain deep flaws that should never be used as part of the research?
- Which ones contain possibly useful ideas that have since been removed from the most recent version?
Applying version control to this situation would lead you to a folder containing just one file
mycode.pyAll of the other versions will still be available via the commit history. Nothing is ever lost and you’ll be able to effectively go back in time to any version of mycode.py you like.

A single point of truth
I’ve even seen folders like the one above passed down generations of PhD students like some sort of family heirloom. I’ve seen labs where multple such folders exist across a dozen machines, each one with a mixture of duplicated and unique files. That is, not only is there a confusing mess of files in a folder but there is a confusing mess of these folders!
This can even be true when only one person is working on a project. Perhaps you have one version of your folder on your University HPC cluster, one on your home laptop and one on your work machine. Perhaps you email zipped versions to yourself from time to time. There are many everyday events that can lead to this state of affairs.
By using a GitHub repository you have a single point of truth for your project. The latest version is there. All old versions are there. All discussion about it is there.
Everything…one place.
The power of this simple idea cannot be overstated. Whenever you (or anyone else) wants to use or continue working on your project, it is always obvious where to go. Never again will you waste several days work only to realise that you weren’t working on the latest version.
Keeping track of everything that changed
The latest version of your analysis or simulation is different from the previous one. Thanks to this, it may now give different results today compared to yesterday. Version control allows you to keep track of everything that changed between two versions. Every line of code you added, deleted or changed is highlighted. Combined with your commit messages where you explain why you made each set of changes, this forms a useful record of the evolution of your project.
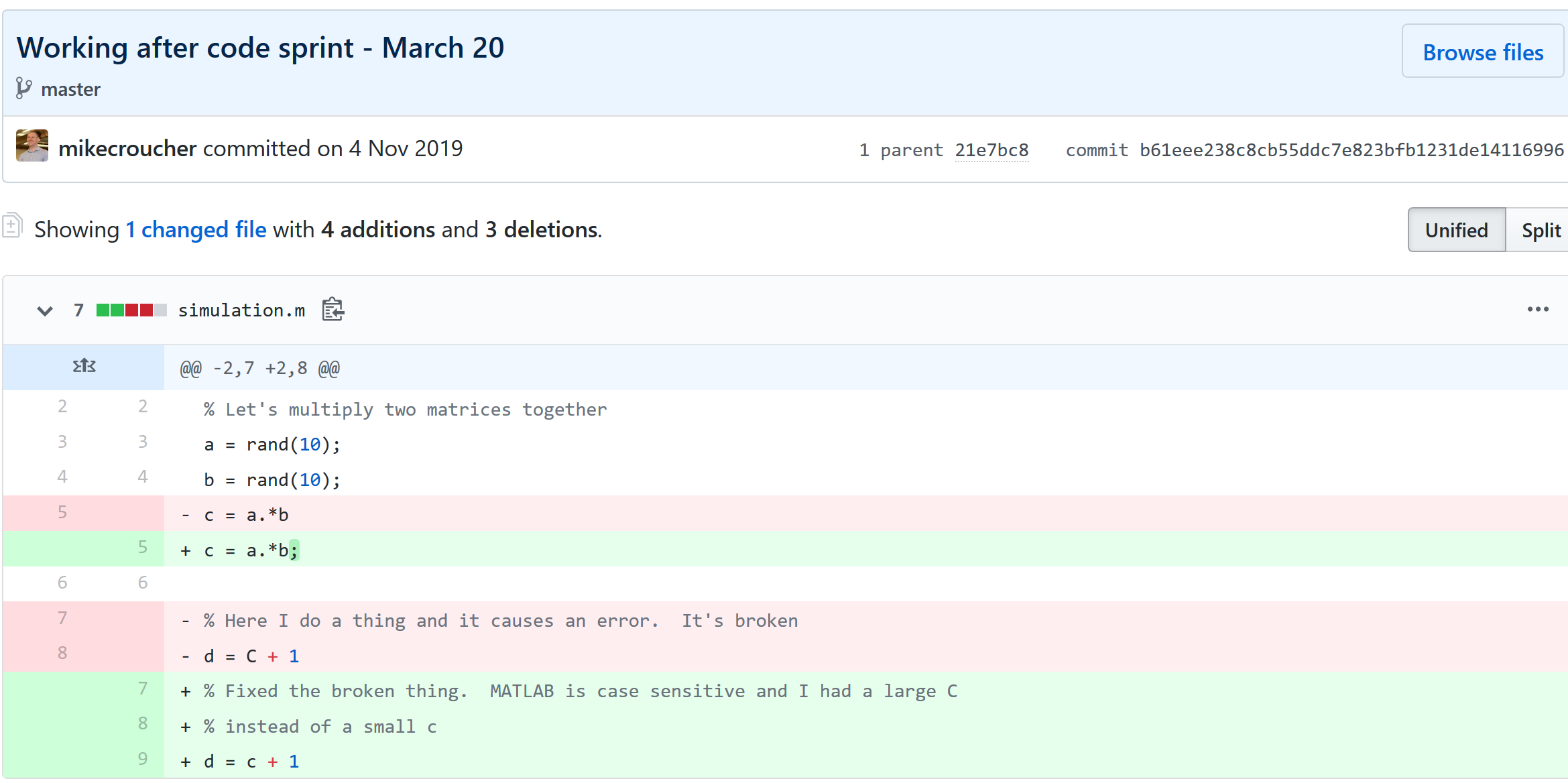
It is possible to compare the differences between any two commits, not just two consecutive ones which allows you to track the evolution of your project over time.
Always having a working version of your project
Ever noticed how your collaborator turns up unnanounced just as you are in the middle of hacking on your code. They want you to show them your simulation running but right now its broken! You frantically try some of the other files in your folder but none of them seem to be the version that was working last week when you sent the report that moved your collaborator to come to see you.
If you were using version control you could easily stash your current work, revert to the last good commit and show off your work.
Tracking down what went wrong
You are always changing that script and you test it as much as you can but the fact is that the version from last year is giving correct results in some edge case while your current version is not. There are 100 versions between the two and there’s a lot of code in each version! When did this edge case start to go wrong?
With git you can use git bisect to help you track down which commit started causing the problem which is the first step towards fixing it.

Providing a back up of your project
Try this thought experiment: Your laptop/PC has gone! Fire, theft, dead hard disk or crazed panda attack.

It, and all of it’s contents have vanished forever. How do you feel? What’s running through your mind? If you feel the icy cold fingers of dread crawling up your spine as you realise Everything related to my PhD/project/life’s work is lost then you have made bad life choices. In particular, you made a terrible choice when you neglected to take back ups.
Of course there are many ways to back up a project but if you are using the standard version control workflow, your code is automatically backed up as a matter of course. You don’t have to remember to back things up, back-ups happen as a natural result of your everyday way of doing things.
Making your project easier to find and install
There are dozens of ways to distribute your software to someone else. You could (HORRORS!) email the latest version to a colleuage or you could have a .zip file on your web site and so on.
Each of these methods has a small cognitive load for both recipient and sender. You need to make sure that you remember to update that .zip file on your website and your user needs to find it. I don’t want to talk about the email case, it makes me too sad. If you and your collaborator are emailing code to each other, please stop. Think of the children!

One great thing about using GitHub is that it is a standardised way of obtaining software. When someone asks for your code, you send them the URL of the repo. Assuming that the world is a better place and everyone knows how to use git, you don’t need to do anything else since the repo URL is all they need to get your code. a git clone later and they are in business.
Additionally, you don’t need to worry abut remembering to turn your working directory into a .zip file and uploading it to your website. The code is naturally available for download as part of the standard workflow. No extra thought needed!
In addition to this, some popular computational environments now allow you to install packages directly from GitHub. If, for example, you are following standard good practice for building an R package then a user can install it directly from your GitHub repo from within R using the devtools::install_github() function.
Automatically run all of your tests
You’ve sipped of the KoolAid and you’ve been writing unit tests like a pro. GitHub allows you to link your repo with something called Continuous Integration (CI) that helps maximise the utility of those tests.
Once its all set up the CI service runs every time you, or anyone else, makes a commit to your project. Every time the CI service runs, a virtual machine is created from scratch, your project is installed into it and all of your tests are run with any failures reported.
This gives you increased confidence that everything is OK with your latest version and you can choose to only accept commits that do not break your testing framework.
Collaboration and Community
How git and GitHub can make it easier to collaborate with others on computational projects.
Control exactly who can see your work
‘I don’t want to use GitHub because I want to keep my project private’ is a common reason given to me for not using the service. The ability to create private repositories has been free for some time now (Price plans are available here https://github.com/pricing) and you can have up to 3 collaborators on any of your private repos before you need to start paying. This is probably enough for most small academic projects.
This means that you can control exactly who sees your code. In the early stages it can be just you. At some point you let a couple of trusted collaborators in and when the time is right you can make the repo public so everyone can enjoy and use your work alongside the paper(s) it supports.
Faciliate discussion about your work
Every GitHub repo comes with an Issues section which is effectively a discussion forum for the project. You can use it to keep track of your project To-Do list, bugs, documentation discussions and so on. The issues log can also be integrated with your commit history. This allows you to do things like git commit -m "Improve the foo algorithm according to the discussion in #34" where #34 refers to the Issue discussion where your collaborator pointed out
Allow others to contribute to your work
You have absolute control over external contributions! No one can make any modifications to your project without your explicit say-so.
I start with the above statement because I’ve found that when explaining how easy it is to collaborate on GitHub, the first question is almost always ‘How do I keep control of all of this?’
What happens is that anyone can ‘fork’ your project into their account. That is, they have an independent copy of your work that is clearly linked back to your original. They can happily work away on their copy as much as they like – with no involvement from you. If and when they want to suggest that some of their modifications should go into your original version, they make a ‘Pull Request’.
I emphasised the word ‘Request’ because that’s exactly what it is. You can completely ignore it if you want and your project will remain unchanged. Alternatively you might choose to discuss it with the contributor and make modifications of your own before accepting it. At the other end of the spectrum you might simply say ‘looks cool’ and accept it immediately.
Congratulations, you’ve just found a contributing collaborator.
Reproducible research
How git and GitHub can contribute to improved reproducible research.
Simply making your software available
A paper published without the supporting software and data is (much!) harder to reproduce than one that has both.
Making your software citable
Most modern research cannot be done without some software element. Even if all you did was run a simple statistical test on 20 small samples, your paper has a data and software dependency. Organisations such as the Software Sustainability Institute and the UK Research Software Engineering Association (among many others) have been arguing for many years that such software and data dependencies should be part of the scholarly record alongside the papers that discuss them. That is, they should be archived and referenced with a permanent Digital Object Identifier (DOI).
Once your code is in GitHub, it is straightforward to archive the version that goes with your latest paper and get it its own DOI using services such as Zenodo. Your University may also have its own archival system. For example, The University of Sheffield in the UK has built a system called ORDA which is based on an institutional Figshare instance which allows Sheffield academics to deposit code and data for long term archival.
Which version gave these results?
Anyone who has worked with software long enough knows that simply stating the name of the software you used is often insufficient to ensure that someone else could reproduce your results. To help improve the odds, you should state exactly which version of the software you used and one way to do this is to refer to the git commit hash. Alternatively, you could go one step better and make a GitHub release of the version of your project used for your latest paper, get it a DOI and cite it.
This doesn’t guarentee reproducibility but its a step in the right direction. For extra points, you may consider making the computational environment reproducible too (e.g. all of the dependencies used by your script – Python modules, R packages and so on) using technologies such as Docker, Conda and MRAN but further discussion of these is out of scope for this article.
Building a computational environment based on your repository
Once your project is on GitHub, it is possible to integrate it with many other online services. One such service is mybinder which allows the generation of an executable environment based on the contents of your repository. This makes your code immediately reproducible by anyone, anywhere.
Similar projects are popping up elsewhere such as The Littlest JupyterHub deploy to Azure button which allows you to add a button to your GitHub repo that, when pressed by a user, builds a server in their Azure cloud account complete with your code and a computational environment specified by you along with a JupterHub instance that allows them to run Jupyter notebooks. This allows you to write interactive papers based on your software and data that can be used by anyone.
Complying with funding and journal guidelines
When I started teaching and advocating the use of technologies such as git I used to make a prediction These practices are so obviously good for computational research that they will one day be mandated by journal editors and funding providers. As such, you may as well get ahead of the curve and start using them now before the day comes when your funding is cut off because you don’t. The resulting debate was usually good fun.
My prediction is yet to come true across the board but it is increasingly becoming the case where eyebrows are raised when papers that rely on software are published don’t come with the supporting software and data. Research Software Engineers (RSEs) are increasingly being added to funding review panels and they may be Reviewer 2 for your latest paper submission.
Other uses of git and GitHub for busy academics
It’s not just about code…..
- Build your own websites using GitHub pasges. Every repo can have its own website served directly from GitHub
- Put your presentations on GitHub. I use reveal.js combined with GitHub pages to build and serve my presentations. That way, whenever I turn up at an event to speak I can use whatever computer is plugged into the projector. No more ‘I don’t have the right adaptor’ hell for me.
- Write your next grant proposal. Use Markdown, LaTex or some other git-friendly text format and use git and GitHub to collaboratively write your next grant proposal
The movie below is a visualisation showing how a large H2020 grant proposal called OpenDreamKit was built on GitHub. Can you guess when the deadline was based on the activity?
Further Resources
Further discussions from scientific computing practitioners that discuss using version control as part of a healthy approach to scientific computing
- Good Enough Practices in Scientific Computing –
- Is Your Research Software Correct? – A presentation from Mike Croucher discussing what can go wrong in computational research and what practices can be adopted to do help us do better
- The Turing Way A handbook of good practice in data science brought to you from the Alan Turning Institute
- A guide to reproducible code in ecology and evolution – A handbook from the British Ecological Society that discusses version control as part of general good practice
Learning version control
Convinced? Want to start learning? Let’s begin!
- Git lesson from Software Carpentry – A free, community written tutorial on the basics of git version control
Graphical User Interfaces to git
If you prefer not to use the command line, try these
My preferred workflow for writing technical documents these days is to write in Markdown (Or Jupyter Notebooks) and then use Pandoc to convert to PDF, Microsoft Word or whatever format is required by the end client.
While working with a markdown file recently, the pandoc conversion to PDF failed with the following error message
! Undefined control sequence. l.117 \[ \coloneqq
This happens because Pandoc first converts the Markdown file to LaTeX which then gets compiled to PDF and the command \coloneqq isn’t included in any of the LaTeX packages that Pandoc uses by default.
The coloneqq command is in the mathtools package which, on Ubuntu, can be installed using
apt-get install texlive-latex-recommended
Once we have the package installed, we need to tell Pandoc to make use of it. The way I did this was to create a Pandoc metadata file that contained the following
---
header-includes: |
\usepackage{mathtools}
---
I called this file pandoc_latex.yml and passed it to Pandoc as follows
pandoc --metadata-file=./pandoc_latex.yml ./input.md -o output.pdf
On one system I tried this on, I received the following error message
pandoc: unrecognized option `--metadata-file=./pandoc_latex.yml'
which suggests that the –metadata-file option is a relatively recent addition to Pandoc. I have no idea when this option was added but if this happens to you, you could try installing the latest version from https://github.com/jgm/pandoc/
I used 2.7.1.1 and it was fine so I guess anything later than this should also be OK.