
Archive for the ‘parallel programming’ Category
So, you’re the proud owner of a new license for MATLAB’s parallel computing toolbox (PCT) and you are wondering how to get some bang for your buck as quickly as possible. Sure, you are going to learn about constructs such as parfor and spmd but that takes time and effort. Wouldn’t it be nice if you could speed up some of your MATLAB code simply by saying ‘Turn parallelisation on’?
It turns out that The Mathworks have been adding support for their parallel computing toolbox all over the place and all you have to do is switch it on (Assuming that you actually have the parallel computing toolbox of course). For example say you had the following call to fmincon (part of the optimisation toolbox) in your code
[x, fval] = fmincon(@objfun, x0, [], [], [], [], [], [], @confun,opts)
To turn on parallelisation across 2 cores just do
matlabpool 2;
opts = optimset('fmincon');
opts = optimset('UseParallel','always');
[x, fval] = fmincon(@objfun, x0, [], [], [], [], [], [], @confun,opts);
That wasn’t so hard was it? The speedup (if any) completely depends upon your particular optimization problem.
Why isn’t parallelisation turned on by default?
The next question that might occur to you is ‘Why doesn’t The Mathworks just turn parallelisation on by default?’ After all, although the above modification is straightforward, it does require you to know that this particular function supports parallel execution via the PCT. If you didn’t think to check then your code would be doomed to serial execution forever.
The simple answer to this question is ‘Sometimes the parallel version is slower‘. Take this serial code for example.
objfun = @(x)exp(x(1))*(4*x(1)^2+2*x(2)^2+4*x(1)*x(2)+2*x(2)+1); confun = @(x) deal( [1.5+x(1)*x(2)-x(1)-x(2); -x(1)*x(2)-10], [] ); tic; [x, fval] = fmincon(objfun, x0, [], [], [], [], [], [], confun); toc
On the machine I am currently sat at (quad core running MATLAB 2011a on Linux) this typically takes around 0.032 seconds to solve. With a problem that trivial my gut feeling is that we are not going to get much out of switching to parallel mode.
objfun = @(x)exp(x(1))*(4*x(1)^2+2*x(2)^2+4*x(1)*x(2)+2*x(2)+1);
confun = @(x) deal( [1.5+x(1)*x(2)-x(1)-x(2); -x(1)*x(2)-10],[] );
%only do this next line once. It opens two MATLAB workers
matlabpool 2;
opts = optimset('fmincon');
opts = optimset('UseParallel','always');
tic;
[x, fval] = fmincon(objfun, x0, [], [], [], [], [], [], confun,opts);
toc
Sure enough, this increases execution time dramatically to an average of 0.23 seconds on my machine. There is always a computational overhead that needs paying when you go parallel and if your problem is too trivial then this overhead costs more than the calculation itself.
So which functions support the Parallel Computing Toolbox?
I wanted a web-page that listed all functions that gain benefit from the Parallel Computing Toolbox but couldn’t find one. I found some documentation on specific toolboxes such as Parallel Statistics but nothing that covered all of MATLAB in one place. Here is my attempt at producing such a document. Feel free to contact me if I have missed anything out.
This covers MATLAB 2011b and is almost certainly incomplete. I’ve only covered toolboxes that I have access to and so some are missing. Please contact me if you have any extra information.
Bioinformatics Toolbox
Global Optimisation
- Various solvers use the PCT. See this part of the MATLAB documentation for details.
Image Processing
- blockproc
- Note that many Image Processing functions run in parallel even without the parallel computing toolbox. See my article Which MATLAB functions are Multicore Aware?
Optimisation Toolbox
Simulink
- Running parallel simulations
- You can increase the speed of diagram updates for models containing large model reference hierarchies by building referenced models that are configured in Accelerator mode in parallel whenever conditions allow. This is covered in the documentation.
Statistics Toolbox
- bootstrp
- bootci
- cordexch
- candexch
- crossval
- dcovary
- daugment
- growTrees
- jackknife
- lasso
- nnmf
- plsregress
- rowexch
- sequentialfs
- TreeBagger
Other articles about parallel computing in MATLAB from WalkingRandomly
- Which MATLAB functions are multicore aware? There are a ton of functions in MATLAB that take advantage of parallel processors automatically. No Parallel Computing Toolbox necessary.
- Parallel MATLAB with OpenMP mex files Want to parallelize your own functions without purchasing the PCT? Not afraid to get your hands dirty with C? Perhaps this option is for you.
- MATLAB GPU/CUDA Experiences and tutorials on my laptop – A series of articles where I look a GPU computing with CUDA on MATLAB
This is part 1 of an ongoing series of articles about MATLAB programming for GPUs using the Parallel Computing Toolbox. The introduction and index to the series is at https://www.walkingrandomly.com/?p=3730.
Have you ever needed to take the sine of 100 million random numbers? Me either, but such an operation gives us an excuse to look at the basic concepts of GPU computing with MATLAB and get an idea of the timings we can expect for simple elementwise calculations.
Taking the sine of 100 million numbers on the CPU
Let’s forget about GPUs for a second and look at how this would be done on the CPU using MATLAB. First, I create 100 million random numbers over a range from 0 to 10*pi and store them in the variable cpu_x;
cpu_x = rand(1,100000000)*10*pi;
Now I take the sine of all 100 million elements of cpu_x using a single command.
cpu_y = sin(cpu_x)
I have to confess that I find the above command very cool. Not only are we looping over a massive array using just a single line of code but MATLAB will also be performing the operation in parallel. So, if you have a multicore machine (and pretty much everyone does these days) then the above command will make good use of many of those cores. Furthermore, this kind of parallelisation is built into the core of MATLAB….no parallel computing toolbox necessary. As an aside, if you’d like to see a list of functions that automatically run in parallel on the CPU then check out my blog post on the issue.
So, how quickly does my 4 core laptop get through this 100 million element array? We can find out using the MATLAB functions tic and toc. I ran it three times on my laptop and got the following
>> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.833626 seconds. >> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.899769 seconds. >> tic;cpu_y = sin(cpu_x);toc Elapsed time is 0.916969 seconds.
So the first thing you’ll notice is that the timings vary and I’m not going to go into the reasons why here. What I am going to say is that because of this variation it makes sense to time the calculation a number of times (20 say) and take an average. Let’s do that
sintimes=zeros(1,20);
for i=1:20;tic;cpu_y = sin(cpu_x);sintimes(i)=toc;end
average_time = sum(sintimes)/20
average_time =
0.8011
So, on average, it takes my quad core laptop just over 0.8 seconds to take the sine of 100 million elements using the CPU. A couple of points:
- I note that this time is smaller than any of the three test times I did before running the loop and I’m not really sure why. I’m guessing that it takes my CPU a short while to decide that it’s got a lot of work to do and ramp up to full speed but further insights are welcomed.
- While staring at the CPU monitor I noticed that the above calculation never used more than 50% of the available virtual cores. It’s using all 4 of my physical CPU cores but perhaps if it took advantage of hyperthreading I’d get even better performance? Changing OMP_NUM_THREADS to 8 before launching MATLAB did nothing to change this.
Taking the sine of 100 million numbers on the GPU
Just like before, we start off by using the CPU to generate the 100 million random numbers1
cpu_x = rand(1,100000000)*10*pi;
The first thing you need to know about GPUs is that they have their own memory that is completely separate from main memory. So, the GPU doesn’t know anything about the array created above. Before our GPU can get to work on our data we have to transfer it from main memory to GPU memory and we acheive this using the gpuArray command.
gpu_x = gpuArray(cpu_x); %this moves our data to the GPU
Once the GPU can see all our data we can apply the sine function to it very easily.
gpu_y = sin(gpu_x)
Finally, we transfer the results back to main memory.
cpu_y = gather(gpu_y)
If, like many of the GPU articles you see in the literature, you don’t want to include transfer times between GPU and host then you time the calculation like this:
tic gpu_y = sin(gpu_x); toc
Just like the CPU version, I repeated this calculation several times and took an average. The result was 0.3008 seconds giving a speedup of 2.75 times compared to the CPU version.
If, however, you include the time taken to transfer the input data to the GPU and the results back to the CPU then you need to time as follows
tic gpu_x = gpuArray(cpu_x); gpu_y = sin(gpu_x); cpu_y = gather(gpu_y) toc
On my system this takes 1.0159 seconds on average– longer than it takes to simply do the whole thing on the CPU. So, for this particular calculation, transfer times between host and GPU swamp the benefits gained by all of those CUDA cores.
Benchmark code
I took the ideas above and wrote a simple benchmark program called sine_test. The way you call it is as follows
[cpu,gpu_notransfer,gpu_withtransfer] = sin_test(numrepeats,num_elements]
For example, if you wanted to run the benchmarks 20 times on a 1 million element array and return the average times then you just do
>> [cpu,gpu_notransfer,gpu_withtransfer] = sine_test(20,1e6)
cpu =
0.0085
gpu_notransfer =
0.0022
gpu_withtransfer =
0.0116
I then ran this on my laptop for array sizes ranging from 1 million to 100 million and used the results to plot the graph below.
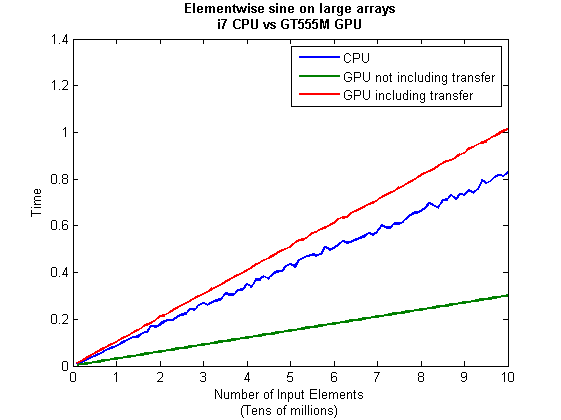
But I wanna write a ‘GPUs are awesome’ paper
So far in this little story things are not looking so hot for the GPU and yet all of the ‘GPUs are awesome’ papers you’ve ever read seem to disagree with me entirely. What on earth is going on? Well, lets take the advice given by csgillespie.wordpress.com and turn it on its head. How do we get awesome speedup figures from the above benchmarks to help us pump out a ‘GPUs are awesome paper’?
0. Don’t consider transfer times between CPU and GPU.
We’ve already seen that this can ruin performance so let’s not do it shall we? As long as we explicitly say that we are not including transfer times then we are covered.
1. Use a singlethreaded CPU.
Many papers in the literature compare the GPU version with a single-threaded CPU version and yet I’ve been using all 4 cores of my processor. Silly me…let’s fix that by running MATLAB in single threaded mode by launching it with the command
matlab -singleCompThread
Now when I run the benchmark for 100 million elements I get the following times
>> [cpu,gpu_no,gpu_with] = sine_test(10,1e8)
cpu =
2.8875
gpu_no =
0.3016
gpu_with =
1.0205
Now we’re talking! I can now claim that my GPU version is over 9 times faster than the CPU version.
2. Use an old CPU.
My laptop has got one of those new-fangled sandy-bridge i7 processors…one of the best classes of CPU you can get for a laptop. If, however, I was doing these tests at work then I guess I’d be using a GPU mounted in my university Desktop machine. Obviously I would compare the GPU version of my program with the CPU in the Desktop….an Intel Core 2 Quad Q9650. Heck its running at 3Ghz which is more Ghz than my laptop so to the casual observer (or a phb) it would look like I was using a more beefed up processor in order to make my comparison fairer.
So, I ran the CPU benchmark on that (in singleCompThread mode obviously) and got 4.009 seconds…noticeably slower than my laptop. Awesome…I am definitely going to use that figure!
I know what you’re thinking…Mike’s being a fool for the sake of it but csgillespie.wordpress.com puts it like this ‘Since a GPU has (usually) been bought specifically for the purpose of the article, the CPU can be a few years older.’ So, some of those ‘GPU are awesome’ articles will be accidentally misleading us in exactly this manner.
3. Work in single precision.
Yeah I know that you like working with double precision arithmetic but that slows GPUs down. So, let’s switch to single precision. Just argue in your paper that single precision is OK for this particular calculation and we’ll be set. To change the benchmarking code all you need to do is change every instance of
rand(1,num_elems)*10*pi;
to
rand(1,num_elems,'single')*10*pi;
Since we are reputable researchers we will, of course, modify both the CPU and GPU versions to work in single precision. Timings are below
- Desktop at work (single thread, single precision): 3.49 seconds
- Laptop GPU (single precision, not including transfer): 0.122 seconds
OK, so switching to single precision made the CPU version a bit faster but it’s more than doubled GPU performance. We can now say that the GPU version is over 28 times faster than the CPU version. Now we have ourselves a bone-fide ‘GPUs are awesome’ paper.
4. Use the best GPU we can find
So far I have been comparing the CPU against the relatively lowly GPU in my laptop. Obviously, however, if I were to do this for real then I’d get a top of the range Tesla. It turns out that I know someone who has a Tesla C2050 and so we ran the single precision benchmark on that. The result was astonishing…0.0295 seconds for 100 million numbers not including transfer times. The double precision performance for the same calculation on the C2050 was 0.0524 seonds.
5. Write the abstract for our ‘GPUs are awesome’ paper
We took an Nvidia Tesla C2050 GPU and mounted it in a machine containing an Intel Quad Core CPU running at 3Ghz. We developed a program that performs element-wise trigonometry on arrays of up to 100 million single precision random numbers using both the CPU and the GPU. The GPU version of our code ran up to 118 times faster than the CPU version. GPUs are awesome!
Results from different CPUs and GPUs. Double precision, multi-threaded
I ran the sine_test benchmark on several different systems for 100 million elements. The CPU was set to be multi-threaded and double precision was used throughout.
sine_test(10,1e8)
GPUs
- Tesla C2050, Linux, 2011a – 0.7487 seconds including transfers, 0.0524 seconds excluding transfers.
- GT 555M – 144 CUDA Cores, 3Gb RAM, Windows 7, 2011a (My laptop’s GPU) -1.0205 seconds including transfers, 0.3016 seconds excluding transfers
CPUs
- Intel Core i7-880 @3.07Ghz, Linux, 2011a – 0.659 seconds
- Intel Core i7-2630QM, Windows 7, 2011a (My laptop’s CPU) – 0.801 seconds
- Intel Core 2 Quad Q9650 @ 3.00GHz, Linux – 0.958 seconds
Conclusions
- MATLAB’s new GPU functions are very easy to use! No need to learn low-level CUDA programming.
- It’s very easy to massage CPU vs GPU numbers to look impressive. Read those ‘GPUs are awesome’ papers with care!
- In real life you have to consider data transfer times between GPU and CPU since these can dominate overall wall clock time with simple calculations such as those considered here. The more work you can do on the GPU, the better.
- My laptop’s GPU is nowhere near as good as I would have liked it to be. Almost 6 times slower than a Tesla C2050 (excluding data transfer) for elementwise double precision calculations. Data transfer times seem to about the same though.
Next time
In the next article in the series I’ll look at an element-wise calculation that really is worth doing on the GPU – even using the wimpy GPU in my laptop – and introduce the MATLAB function arrayfun.
Footnote
1 – MATLAB 2011a can’t create random numbers directly on the GPU. I have no doubt that we’ll be able to do this in future versions of MATLAB which will change the nature of this particular calculation somewhat. Then it will make sense to include the random number generation in the overall benchmark; transfer times to the GPU will be non-existant. In general, however, we’ll still come across plenty of situations where we’ll have a huge array in main memory that needs to be transferred to the GPU for further processing so what we learn here will not be wasted.
Hardware / Software used for the majority of this article
- Laptop model: Dell XPS L702X
- CPU: Intel Core i7-2630QM @2Ghz software overclockable to 2.9Ghz. 4 physical cores but total 8 virtual cores due to Hyperthreading.
- GPU: GeForce GT 555M with 144 CUDA Cores. Graphics clock: 590Mhz. Processor Clock:1180 Mhz. 3072 Mb DDR3 Memeory
- RAM: 8 Gb
- OS: Windows 7 Home Premium 64 bit. I’m not using Linux because of the lack of official support for Optimus.
- MATLAB: 2011a with the parallel computing toolbox
Other GPU articles at Walking Randomly
- GPU Support in Mathematica, Maple, MATLAB and Maple Prime – See the various options available
- Insert new laptop to continue – My first attempt at using the GPU functionality in MATLAB
- NVIDIA lets down Linux laptop users – and how an open source project saves the day
Thanks to various people at The Mathworks for some useful discussions, advice and tutorials while creating this series of articles.
These days it seems that you can’t talk about scientific computing for more than 5 minutes without somone bringing up the topic of Graphics Processing Units (GPUs). Originally designed to make computer games look pretty, GPUs are massively parallel processors that promise to revolutionise the way we compute.
A brief glance at the specification of a typical laptop suggests why GPUs are the new hotness in numerical computing. Take my new one for instance, a Dell XPS L702X, which comes with a Quad-Core Intel i7 Sandybridge processor running at up to 2.9Ghz and an NVidia GT 555M with a whopping 144 CUDA cores. If you went back in time a few years and told a younger version of me that I’d soon own a 148 core laptop then young Mike would be stunned. He’d also be wondering ‘What’s the catch?’
Of course the main catch is that all processor cores are not created equally. Those 144 cores in my GPU are, individually, rather wimpy when compared to the ones in the Intel CPU. It’s the sheer quantity of them that makes the difference. The question at the forefront of my mind when I received my shiny new laptop was ‘Just how much of a difference?’
Now I’ve seen lots of articles that compare CPUs with GPUs and the GPUs always win…..by a lot! Dig down into the meat of these articles, however, and it turns out that things are not as simple as they seem. Roughly speaking, the abstract of some them could be summed up as ‘We took a serial algorithm written by a chimpanzee for an old, outdated CPU and spent 6 months parallelising and fine tuning it for a top of the line GPU. Our GPU version is up to 150 times faster!‘
Well it would be wouldn’t it?! In other news, Lewis Hamilton can drive his F1 supercar around Silverstone faster than my dad can in his clapped out 12 year old van! These articles are so prevalent that csgillespie.wordpress.com recently published an excellent article that summarised everything you should consider when evaluating them. What you do is take the claimed speed-up, apply a set of common sense questions and thus determine a realistic speedup. That factor of 150 can end up more like a factor of 8 once you think about it the right way.
That’s not to say that GPUs aren’t powerful or useful…it’s just that maybe they’ve been hyped up a bit too much!
So anyway, back to my laptop. It doesn’t have a top of the range GPU custom built for scientific computing, instead it has what Notebookcheck.net refers to as a fast middle class graphics card for laptops. It’s got all of the required bits though….144 cores and CUDA compute level 2.1 so surely it can whip the built in CPU even if it’s just by a little bit?
I decided to find out with a few randomly chosen tests. I wasn’t aiming for the kind of rigor that would lead to a peer reviewed journal but I did want to follow some basic rules at least
- I will only choose algorithms that have been optimised and parallelised for both the CPU and the GPU.
- I will release the source code of the tests so that they can be critised and repeated by others.
- I’ll do the whole thing in MATLAB using the new GPU functionality in the parallel computing toolbox. So, to repeat my calculations all you need to do is copy and paste some code. Using MATLAB also ensures that I’m using good quality code for both CPU and GPU.
The articles
This is the introduction to a set of articles about GPU computing on MATLAB using the parallel computing toolbox. Links to the rest of them are below and more will be added in the future.
- Elementwise operations on the GPU #1 – Basic commands using the PCT and how to write a ‘GPUs are awesome’ paper; no matter what results you get!
- Elementwise operations on the GPU #2 – A slightly more involved example showing a useful speed-up compared to the CPU. An introduction to MATLAB’s arrayfun
- Optimising a correlated asset calculation on MATLAB #1: Vectorisation on the CPU – A detailed look at a port from CPU MATLAB code to GPU MATLAB code.
- Optimising a correlated asset calculation on MATLAB #2: Using the GPU via the PCT – A detailed look at a port from CPU MATLAB code to GPU MATLAB code.
- Optimising a correlated asset calculation on MATLAB #3: Using the GPU via Jacket – A detailed look at a port from CPU MATLAB code to GPU MATLAB code.
External links of interest to MATLABers with an interest in GPUs
- The Parallel Computing Toolbox (PCT) – The Mathwork’s MATLAB add-on that gives you CUDA GPU support.
- Mike Gile’s MATLAB GPU Blog – from the University of Oxford
- Accelereyes – Developers of ‘Jacket’, an alternative to the parallel computing toolbox.
- A Mandelbrot Set on the GPU – Using the parallel computing toolbox to make pretty pictures…FAST!
- GP-you.org – A free CUDA-based GPU toolbox for MATLAB
- Matlab, CUDA and Me – Stu Blair gives various examples of calling CUDA kernels directly from MATLAB
Over at Sol Lederman’s fantastic new blog, Playing with Mathematica, he shared some code that produced the following figure.

Here’s Sol’s code with an AbsoluteTiming command thrown in.
f[x_, y_] := Module[{},
If[
Sin[Min[x*Sin[y], y*Sin[x]]] >
Cos[Max[x*Cos[y],
y*Cos[x]]] + (((2 (x - y)^2 + (x + y - 6)^2)/40)^3)/
6400000 + (12 - x - y)/30, 1, 0]
]
AbsoluteTiming[
\[Delta] = 0.02;
range = 11;
xyPoints = Table[{x, y}, {y, 0, range, \[Delta]}, {x, 0, range, \[Delta]}];
image = Map[f @@ # &, xyPoints, {2}];
]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}], 135 Degree]
This took 8.02 seconds on the laptop I am currently working on (Windows 7 AMD Phenom II N620 Dual core at 2.8Ghz). Note that I am only measuring how long the calculation itself took and am ignoring the time taken to render the image and define the function.
Compiled functions make Mathematica code go faster
Mathematica has a Compile function which does exactly what you’d expect…it produces a compiled version of the function you give it (if it can!). Sol’s function gave it no problems at all.
f = Compile[{{x, _Real}, {y, _Real}}, If[
Sin[Min[x*Sin[y], y*Sin[x]]] >
Cos[Max[x*Cos[y],
y*Cos[x]]] + (((2 (x - y)^2 + (x + y - 6)^2)/40)^3)/
6400000 + (12 - x - y)/30, 1, 0]
];
AbsoluteTiming[
\[Delta] = 0.02;
range = 11;
xyPoints =
Table[{x, y}, {y, 0, range, \[Delta]}, {x, 0, range, \[Delta]}];
image = Map[f @@ # &, xyPoints, {2}];
]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}],
135 Degree]
This simple change takes computation time down from 8.02 seconds to 1.23 seconds which is a 6.5 times speed up for hardly any extra coding work. Not too shabby!
Switch to C code to get it even faster
I’m not done yet though! By default the Compile command produces code for the so-called Mathematica Virtual Machine but recent versions of Mathematica allow us to go even further.
Install Visual Studio Express 2010 (and the Windows 7.1 SDK if you are running 64bit Windows) and you can ask Mathematica to convert the function to low level C code, compile it and produce a function object linked to the resulting compiled code. Sounds complicated but is a snap to actually do. Just add
CompilationTarget -> "C"
to the Compile command.
f = Compile[{{x, _Real}, {y, _Real}},
If[Sin[Min[x*Sin[y], y*Sin[x]]] >
Cos[Max[x*Cos[y],
y*Cos[x]]] + (((2 (x - y)^2 + (x + y - 6)^2)/40)^3)/
6400000 + (12 - x - y)/30, 1, 0]
, CompilationTarget -> "C"
];
AbsoluteTiming[\[Delta] = 0.02;
range = 11;
xyPoints =
Table[{x, y}, {y, 0, range, \[Delta]}, {x, 0, range, \[Delta]}];
image = Map[f @@ # &, xyPoints, {2}];]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}],
135 Degree]
On my machine this takes calculation time down to 0.89 seconds which is 9 times faster than the original.
Making the compiled function listable
The current compiled function takes just one x,y pair and returns a result.
In[8]:= f[1, 2] Out[8]= 1
It can’t directly accept a list of x values and a list of y values. For example for the two points (1,2) and (10,20) I’d like to be able to do f[{1, 10}, {2, 20}] and get the results {1,1}. However what I end up with is an error
f[{1, 10}, {2, 20}]
CompiledFunction::cfsa: Argument {1,10} at position 1 should be a machine-size real number. >>
To fix this I need to make my compiled function listable which is as easy as adding
RuntimeAttributes -> {Listable}
to the function definition.
f = Compile[{{x, _Real}, {y, _Real}},
If[Sin[Min[x*Sin[y], y*Sin[x]]] >
Cos[Max[x*Cos[y],
y*Cos[x]]] + (((2 (x - y)^2 + (x + y - 6)^2)/40)^3)/
6400000 + (12 - x - y)/30, 1, 0]
, CompilationTarget -> "C", RuntimeAttributes -> {Listable}
];
So now I can pass the entire array to this compiled function at once. No need for Map.
AbsoluteTiming[
\[Delta] = 0.02;
range = 11;
xpoints = Table[x, {x, 0, range, \[Delta]}, {y, 0, range, \[Delta]}];
ypoints = Table[y, {x, 0, range, \[Delta]}, {y, 0, range, \[Delta]}];
image = f[xpoints, ypoints];
]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}],
135 Degree]
On my machine this gets calculation time down to 0.28 seconds, a whopping 28.5 times faster than the original. Rendering time is becoming much more of an issue than calculation time in fact!
Parallel anyone?
Simply by adding
Parallelization -> True
to the Compile command I can parallelise the code using threads. Since I have a dual core machine, this might be a good thing to do. Let’s take a look
f = Compile[{{x, _Real}, {y, _Real}},
If[
Sin[Min[x*Sin[y], y*Sin[x]]] >
Cos[Max[x*Cos[y],
y*Cos[x]]] + (((2 (x - y)^2 + (x + y - 6)^2)/40)^3)/
6400000 + (12 - x - y)/30, 1, 0]
, RuntimeAttributes -> {Listable}, CompilationTarget -> "C",
Parallelization -> True];
AbsoluteTiming[
\[Delta] = 0.02;
range = 11;
xpoints = Table[x, {x, 0, range, \[Delta]}, {y, 0, range, \[Delta]}];
ypoints = Table[y, {x, 0, range, \[Delta]}, {y, 0, range, \[Delta]}];
image = f[xpoints, ypoints];
]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}],
135 Degree]
The first time I ran this it was SLOWER than the non-threaded version coming in at 0.33 seconds. Subsequent runs varied and occasionally got as low as 0.244 seconds which is only a few hundredths of a second faster than the original.
If I make the problem bigger, however, by decreasing the size of Delta then we start to see the benefit of parallelisation.
AbsoluteTiming[
\[Delta] = 0.01;
range = 11;
xpoints = Table[x, {x, 0, range, \[Delta]}, {y, 0, range, \[Delta]}];
ypoints = Table[y, {x, 0, range, \[Delta]}, {y, 0, range, \[Delta]}];
image = f[xpoints, ypoints];
]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}],
135 Degree]
The above calculation (sans rendering) took 0.988 seconds using a parallelised version of f and 1.24 seconds using a serial version. Rendering took significantly longer! As a comparison lets put a Delta of 0.01 in the original code:
f[x_, y_] := Module[{},
If[
Sin[Min[x*Sin[y], y*Sin[x]]] >
Cos[Max[x*Cos[y],
y*Cos[x]]] + (((2 (x - y)^2 + (x + y - 6)^2)/40)^3)/
6400000 + (12 - x - y)/30, 1, 0]
]
AbsoluteTiming[
\[Delta] = 0.01;
range = 11;
xyPoints = Table[{x, y}, {y, 0, range, \[Delta]}, {x, 0, range, \[Delta]}];
image = Map[f @@ # &, xyPoints, {2}];
]
Rotate[ArrayPlot[image, ColorRules -> {0 -> White, 1 -> Black}], 135 Degree]
The calculation time (again, ignoring rendering time) took 32.56 seconds and so our C-compiled, parallel version is almost 33 times faster!
Summary
- The Compile function can make your code run significantly faster by compiling it for the Mathematica Virtual Machine (MVM). Note that not every function is suitable for compilation.
- If you have a C-compiler installed on your machine then you can switch from the MVM to compiled C-code using a single option statement. The resulting code is even faster
- Making your functions listable can increase performance.
- Parallelising your compiled function is easy and can lead to even more speed but only if your problem is of a suitable size.
- Sol Lederman has a very cool Mathematica blog – check it out! The code that inspired this blog post originated there.
Updated January 4th 2011
It is becoming increasingly common for programmers to make use of GPUs (Graphical Processing Units) to speed up their programs substantially. There are three major low-level programming libraries that allow you to do this in languages such as C; namely CUDA, OpenCL and Microsoft DirectCompute. Of these three, CUDA is the most developed but it only works on Nvidia graphics cards.
I am often asked if the major commercial math packages support GPU computing and I find myself writing the same summary email over and over again. So, here is a very brief breakdown of what is currently on offer. I plan to expand the information contained in this page over time so if you have any information about GPU computing in these packages then let me know.
MATLAB
Core MATLAB contains no support for GPU computing but several organizations (including The Mathworks themselves) have produced add-on toolboxes that add such support:
- Jacket – This is a product from a company called AccelerEyes and is possibly the most advanced and well developed GPU solution for MATLAB currently available. As of version 2.0 it supports both OpenCL and CUDA frameworks.
- The Mathworks’ Parallel Computing Toolbox (PCT) – If you want to do your MATLAB GPU computing the officially supported way then this is the product you need. As a bonus, it also allows you to make better use of the multicore processor that almost certainly resides in your machine. Like many of the offerings on this page, only the CUDA framework is supported so you are out of luck if you don’t have an NVidia graphics card. Even if you do have an NVidia graphics card then you still might be out of luck since the PCT only supports cards that have compute level 1.3 or above (i.e. double precision only).
- CULA is a set of GPU-accelerated linear algebra libraries utilizing the NVIDIA CUDA parallel computing architecture and it has a MATLAB interface.
- GPUmat – This product is completely free but is less developed than the commercial offerings above. Again. it is CUDA only
- OpenCL toolbox – The only OpenCL solution for MATLAB I could find. It is free but development seems to have stalled.
Mathematica
Mathematica 8 has support for both CUDA and OpenCL built in so no need for any add-ons. Furthermore, it supports both single and double precision GPUs so you can experiment with GPU computing on older, cheaper cards.
Maple
Maple has had some CUDA-only GPU support since version 14. On the face of it, the CUDA package only appears to contain one accelerated function–Matrix-Matrix multiplication– but when you load this function it accelerates many functions that use matrix-matrix multiply internally. I’ve never found a definitive list of such functions though.
Mathcad
Mathcad 15 and Mathcad Prime have no support for GPU enhanced computing.
In my previous blog post I mentioned that I am a member of a team that supports High Throughput Computing (HTC) at The University of Manchester via a 1600+ core ‘condor pool’. In order to make it as easy as possible for our researchers to make use of this resource one of my colleagues, Ian Cottam, created a system called DropAndCompute. In this guest blog post, Ian describes DropAndCompute and how it evolved into the system we use at Manchester today.
The Evolution of “DropAndCompute” by Ian Cottam
DropAndCompute, as used at The University of Manchester’s Faculty of Engineering and Physical Sciences, is an approach to using network (or grid or cloud based) computational resources without having to know the operating system of the resource’s gateway or any command line tools of either the resource itself —Condor in our case — or in general. Most such gateways run a flavour of Unix, often Linux. Many of our users are either unfamiliar with Linux or just prefer a drag-and-drop interface, as I do myself despite using various flavours of Unix since Version 6 in the late 70s.
Why did I invent it? On its original web site description page wiki.myexperiment.org/index.php/DropAndCompute the following reasons are given:
- A simple and uniform drag-and-drop graphical user interface, potentially, to many resource pools.
- No use of terminal windows or command lines.
- No need to login to remote hosts or install complicated grid-enabling software locally.
- No need for the user to have an account on the remote resources (instead they are accounted by having a shared folder allocated). Of course, nothing stops the users from having accounts should that be preferred.
- No need for complicated Virtual Private Networks, IP Tunnelling, connection brokers, or similar, in order to access grid resources on private subnets (provided at least one node is on the public Internet, which is the norm).
- Pop-ups notify users of important events (basically, log and output files being created when a job has been accepted, and when the generated result files arrive).
- Somewhat increased security as the user only has (indirect) access to a small subset of the computational resource’s commands.
Version One
The first version was used on a Condor Pool within our interdisciplinary biocentre (MIB). A video of it in use is shown below
Please do take the time to look at this video as it shows clearly how, for example, Condor can be used via this type of interface.
This version was notable for using the commercial service: Dropbox and, in fact, my being a Dropbox user inspired the approach and its name. Dropbox is trivial to install on any of the main platforms, on any number of computers owned by a user, and has a free version giving 2GB of synchronised and shared storage. In theory, only the computational resource supplier need pay for a 100GB account with Dropbox, have a local Condor submitting account, and share folders out with users of the free Dropbox-based service.
David De Roure, then at the University of Southampton and now Oxford, reviewed this approach here at blog.openwetware.org/deroure/?p=97, and offers his view as to why it is important in helping scientists start on the ‘ramp’ to using what can be daunting, if powerful, computational facilities.
Version Two
Quickly the approach migrated to our full, faculty-wide Condor Pool and the first modification was made. Now we used separate accounts for each user of the service on our submitting nodes; Dropbox still made this sharing scheme trivial to set up and manage, whilst giving us much better usage accounting information. The first minor problem came when some users needed more –much more in fact– than 2GB of space. This was solved by them purchasing their own 50GB or 100GB accounts from Dropbox.
Problems and objections
However, two more serious problems impacted our Dropbox based approach. First, the large volume of network traffic across the world to Dropbox’s USA based servers and then back down to local machines here in Manchester resulted in severe bottlenecks once our Condor Pool had reached the dizzy heights of over a thousand processor cores. We could have ameliorated this by extra resources, such as multiple submit nodes, but the second problem proved to be more of a showstopper.
Since the introduction of DropAndCompute several people –at Manchester and beyond– have been concerned about research data passing through commercial, USA-based servers. In fact, the UK’s National Grid Service (NGS) who have implemented their own flavour of DropAndCompute did not use Dropbox for this very reason. The US Patriot Act means that US companies must surrender any data they hold if officially requested to do so by Federal Government agencies. Now one approach to this is to do user-level encryption of the data before it enters the user’s dropbox. I have demonstrated this approach, but it complicates the model and it is not so straightforward to use exactly the same method on all of the popular platforms (Windows, Mac, Linux).
Version Three
To tackle the above issues we implemented a ‘local version’ of DropAndCompute that is not Dropbox based. It is similar to the NGS approach, but, in my opinion, much simpler to setup. The user merely has to mount a folder on the submit node on their local computer(s), and then use the same drag-and-drop approach to get the job initiated, debugged and run (or even killed, when necessary). This solves the above issues, but could be regarded as inferior to the Dropbox based approach in five ways:
1. The convenience and transparency of ‘offline’ use. That is, Dropbox jobs can be prepared on, say, a laptop with or without net access, and when the laptop next connects the job submissions just happens. Ditto for the results coming back.
2. When online and submitting or waiting for results with the local version, the folder windows do not update to give the user an indication of progress.
3. Users must remember to use an email notification that a job has finished, or poll to check its status.
4. The initial setup is a little harder for the local version compared with using Dropbox.
5. The computation’s result files are not copied back automatically.
So far, only item 5 has been remarked on by some of our users, and it, and the others, could be improved with some programming effort.
A movie of this version is shown below; it doesn’t have any commentary, but essentially follows the same steps as the Dropbox based video. You will see the network folder’s window having to be refreshed manually –this is necessary on a Mac (but could be scripted); other platforms may be better– and results having to be dragged back from the mounted folder.
I welcome comments on any aspect of this –still evolving– approach to easing the entry ‘cost’ to using distributed computing resources.
Acknowledgments
Our Condor Pool is supported by three colleagues besides myself: Mark Whidby, Mike Croucher and Chris Paul. Mark, inter alia, maintains the current version of DropAndCompute that can operate locally or via Dropbox. Thanks also to Mike for letting me be a guest on Walking Randomly.
Some time ago now, Sam Shah of Continuous Everywhere but Differentiable Nowhere fame discussed the standard method of obtaining the square root of the imaginary unit, i, and in the ensuing discussion thread someone asked the question “What is i^i – that is what is i to the power i?”
Sam immediately came back with the answer e^(-pi/2) = 0.207879…. which is one of the answers but as pointed out by one of his readers, Adam Glesser, this is just one of the infinite number of potential answers that all have the form e^{-(2k+1) pi/2} where k is an integer. Sam’s answer is the principle value of i^i (incidentally this is the value returned by google calculator if you google i^i – It is also the value returned by Mathematica and MATLAB). Life gets a lot more complicated when you move to the complex plane but it also gets a lot more interesting too.
While on the train into work one morning I was thinking about Sam’s blog post and wondered what the principal value of i^i^i (i to the power i to the power i) was equal to. Mathematica quickly provided the answer:
N[I^I^I] 0.947159+0.320764 I
So i is imaginary, i^i is real and i^i^i is imaginary again. Would i^i^i^i be real I wondered – would be fun if it was. Let’s see:
N[I^I^I^I] 0.0500922+0.602117 I
gah – a conjecture bites the dust – although if I am being honest it wasn’t a very good one. Still, since I have started making ‘power towers’ I may as well continue and see what I can see. Why am I calling them power towers? Well, the calculation above could be written as follows:
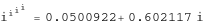
As I add more and more powers, the left hand side of the equation will tower up the page….Power Towers. We now have a sequence of the first four power towers of i:
i = i i^i = 0.207879 i^i^i = 0.947159 + 0.32076 I i^i^i^i = 0.0500922+0.602117 I
Sequences of power towers
“Will this sequence converge or diverge?”, I wondered. I wasn’t in the mood to think about a rigorous mathematical proof, I just wanted to play so I turned back to Mathematica. First things first, I needed to come up with a way of making an arbitrarily large power tower without having to do a lot of typing. Mathematica’s Nest function came to the rescue and the following function allows you to create a power tower of any size for any number, not just i.
tower[base_, size_] := Nest[N[(base^#)] &, base, size]
Now I can find the first term of my series by doing
In[1]:= tower[I, 0] Out[1]= I
Or the 5th term by doing
In[2]:= tower[I, 4] Out[2]= 0.387166 + 0.0305271 I
To investigate convergence I needed to create a table of these. Maybe the first 100 towers would do:
ColumnForm[
Table[tower[I, n], {n, 1, 100}]
]
The last few values given by the command above are
0.438272+ 0.360595 I 0.438287+ 0.360583 I 0.438287+ 0.3606 I 0.438275+ 0.360591 I 0.438289+ 0.360588 I
Now this is interesting – As I increased the size of the power tower, the result seemed to be converging to around 0.438 + 0.361 i. Further investigation confirms that the sequence of power towers of i converges to 0.438283+ 0.360592 i. If you were to ask me to guess what I thought would happen with large power towers like this then I would expect them to do one of three things – diverge to infinity, stay at 1 forever or quickly converge to 0 so this is unexpected behaviour (unexpected to me at least).
They converge, but how?
My next thought was ‘How does it converge to this value? In other words, ‘What path through the complex plane does this sequence of power towers take?” Time for a graph:
tower[base_, size_] := Nest[N[(base^#)] &, base, size];
complexSplit[x_] := {Re[x], Im[x]};
ListPlot[Map[complexSplit, Table[tower[I, n], {n, 0, 49, 1}]],
PlotRange -> All]
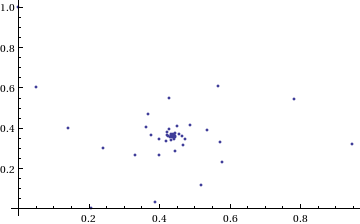
Who would have thought you could get a spiral from power towers? Very nice! So the next question is ‘What would happen if I took a different complex number as my starting point?’ For example – would power towers of (0.5 + i) converge?’
The answer turns out to be yes – power towers of (0.5 + I) converge to 0.541199+ 0.40681 I but the resulting spiral looks rather different from the one above.
tower[base_, size_] := Nest[N[(base^#)] &, base, size];
complexSplit[x_] := {Re[x], Im[x]};
ListPlot[Map[complexSplit, Table[tower[0.5 + I, n], {n, 0, 49, 1}]],
PlotRange -> All]
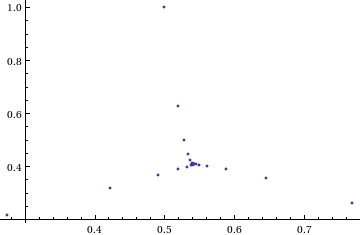 The zoo of power tower spirals
The zoo of power tower spirals
So, taking power towers of two different complex numbers results in two qualitatively different ‘convergence spirals’. I wondered how many different spiral types I might find if I consider the entire complex plane? I already have all of the machinery I need to perform such an investigation but investigation is much more fun if it is interactive. Time for a Manipulate
complexSplit[x_] := {Re[x], Im[x]};
tower[base_, size_] := Nest[N[(base^#)] &, base, size];
generatePowerSpiral[p_, nmax_] :=
Map[complexSplit, Table[tower[p, n], {n, 0, nmax-1, 1}]];
Manipulate[const = p[[1]] + p[[2]] I;
ListPlot[generatePowerSpiral[const, n],
PlotRange -> {{-2, 2}, {-2, 2}}, Axes -> ax,
Epilog -> Inset[Framed[const], {-1.5, -1.5}]], {{n, 100,
"Number of terms"}, 1, 200, 1,
Appearance -> "Labeled"}, {{ax, True, "Show axis"}, {True,
False}}, {{p, {0, 1.5}}, Locator}]
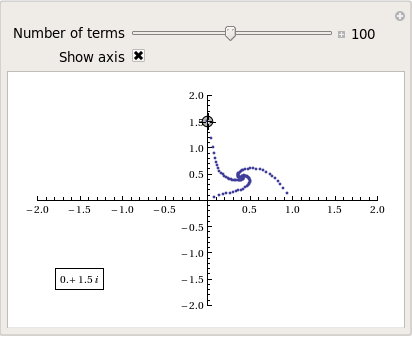
After playing around with this Manipulate for a few seconds it became clear to me that there is quite a rich diversity of these convergence spirals. Here are a couple more
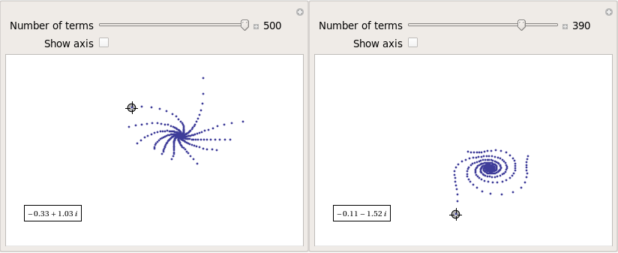
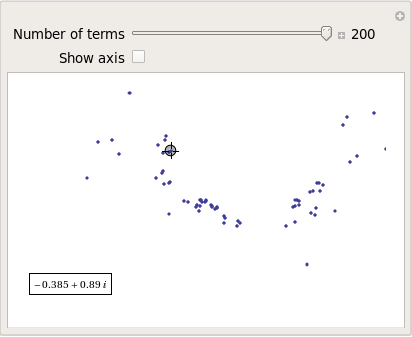
Some of them take a lot longer to converge than others and then there are those that don’t converge at all:
Optimising the code a little
Before I could investigate convergence any further, I had a problem to solve: Sometimes the Manipulate would completely freeze and a message eventually popped up saying “One or more dynamic objects are taking excessively long to finish evaluating……” What was causing this I wondered?
Well, some values give overflow errors:
In[12]:= generatePowerSpiral[-1 + -0.5 I, 200] General::ovfl: Overflow occurred in computation. >> General::ovfl: Overflow occurred in computation. >> General::ovfl: Overflow occurred in computation. >> General::stop: Further output of General::ovfl will be suppressed during this calculation. >>
Could errors such as this be making my Manipulate unstable? Let’s see how long it takes Mathematica to deal with the example above
AbsoluteTiming[ListPlot[generatePowerSpiral[-1 -0.5 I, 200]]]
On my machine, the above command typically takes around 0.08 seconds to complete compared to 0.04 seconds for a tower that converges nicely; it’s slower but not so slow that it should break Manipulate. Still, let’s fix it anyway.
Look at the sequence of values that make up this problematic power tower
generatePowerSpiral[-0.8 + 0.1 I, 10]
{{-0.8, 0.1}, {-0.668442, -0.570216}, {-2.0495, -6.11826},
{2.47539*10^7,1.59867*10^8}, {2.068155430437682*10^-211800874,
-9.83350984373519*10^-211800875}, {Overflow[], 0}, {Indeterminate,
Indeterminate}, {Indeterminate, Indeterminate}, {Indeterminate,
Indeterminate}, {Indeterminate, Indeterminate}}
Everything is just fine until the term {Overflow[],0} is reached; after which we are just wasting time. Recall that the functions I am using to create these sequences are
complexSplit[x_] := {Re[x], Im[x]};
tower[base_, size_] := Nest[N[(base^#)] &, base, size];
generatePowerSpiral[p_, nmax_] :=
Map[complexSplit, Table[tower[p, n], {n, 0, nmax-1, 1}]];
The first thing I need to do is break out of tower’s Nest function as soon as the result stops being a complex number and the NestWhile function allows me to do this. So, I could redefine the tower function to be
tower[base_, size_] := NestWhile[N[(base^#)] &, base, MatchQ[#, _Complex] &, 1, size]
However, I can do much better than that since my code so far is massively inefficient. Say I already have the first n terms of a tower sequence; to get the (n+1)th term all I need to do is a single power operation but my code is starting from the beginning and doing n power operations instead. So, to get the 5th term, for example, my code does this
I^I^I^I^I
instead of
(4th term)^I
The function I need to turn to is yet another variant of Nest – NestWhileList
fasttowerspiral[base_, size_] := Quiet[Map[complexSplit, NestWhileList[N[(base^#)] &, base, MatchQ[#, _Complex] &, 1, size, -1]]];
The Quiet function is there to prevent Mathematica from warning me about the Overflow error. I could probably do better than this and catch the Overflow error coming before it happens but since I’m only mucking around, I’ll leave that to an interested reader. For now it’s enough for me to know that the code is much faster than before:
(*Original Function*)
AbsoluteTiming[generatePowerSpiral[I, 200];]
{0.036254, Null}
(*Improved Function*)
AbsoluteTiming[fasttowerspiral[I, 200];]
{0.001740, Null}
A factor of 20 will do nicely!
Making Mathematica faster by making it stupid
I’m still not done though. Even with these optimisations, it can take a massive amount of time to compute some of these power tower spirals. For example
spiral = fasttowerspiral[-0.77 - 0.11 I, 100];
takes 10 seconds on my machine which is thousands of times slower than most towers take to compute. What on earth is going on? Let’s look at the first few numbers to see if we can find any clues
In[34]:= spiral[[1 ;; 10]]
Out[34]= {{-0.77, -0.11}, {-0.605189, 0.62837}, {-0.66393,
7.63862}, {1.05327*10^10,
7.62636*10^8}, {1.716487392960862*10^-155829929,
2.965988537183398*10^-155829929}, {1., \
-5.894184073663391*10^-155829929}, {-0.77, -0.11}, {-0.605189,
0.62837}, {-0.66393, 7.63862}, {1.05327*10^10, 7.62636*10^8}}
The first pair that jumps out at me is {1.71648739296086210^-155829929, 2.96598853718339810^-155829929} which is so close to {0,0} that it’s not even funny! So close, in fact, that they are not even double precision numbers any more. Mathematica has realised that the calculation was going to underflow and so it caught it and returned the result in arbitrary precision.
Arbitrary precision calculations are MUCH slower than double precision ones and this is why this particular calculation takes so long. Mathematica is being very clever but its cleverness is costing me a great deal of time and not adding much to the calculation in this case. I reckon that I want Mathematica to be stupid this time and so I’ll turn off its underflow safety net.
SetSystemOptions["CatchMachineUnderflow" -> False]
Now our problematic calculation takes 0.000842 seconds rather than 10 seconds which is so much faster that it borders on the astonishing. The results seem just fine too!
When do the power towers converge?
We have seen that some towers converge while others do not. Let S be the set of complex numbers which lead to convergent power towers. What might S look like? To determine that I have to come up with a function that answers the question ‘For a given complex number z, does the infinite power tower converge?’ The following is a quick stab at such a function
convergeQ[base_, size_] :=
If[Length[
Quiet[NestWhileList[N[(base^#)] &, base, Abs[#1 - #2] > 0.01 &,
2, size, -1]]] < size, 1, 0];
The tolerance I have chosen, 0.01, might be a little too large but these towers can take ages to converge and I’m more interested in speed than accuracy right now so 0.01 it is. convergeQ returns 1 when the tower seems to converge in at most size steps and 0 otherwise.:
In[3]:= convergeQ[I, 50] Out[3]= 1 In[4]:= convergeQ[-1 + 2 I, 50] Out[4]= 0
So, let’s apply this to a section of the complex plane.
towerFract[xmin_, xmax_, ymin_, ymax_, step_] :=
ArrayPlot[
Table[convergeQ[x + I y, 50], {y, ymin, ymax, step}, {x, xmin, xmax,step}]]
towerFract[-2, 2, -2, 2, 0.1]

That looks like it might be interesting, possibly even fractal, behaviour but I need to increase the resolution and maybe widen the range to see what’s really going on. That’s going to take quite a bit of calculation time so I need to optimise some more.
Going Parallel
There is no point in having machines with two, four or more processor cores if you only ever use one and so it is time to see if we can get our other cores in on the act.
It turns out that this calculation is an example of a so-called embarrassingly parallel problem and so life is going to be particularly easy for us. Basically, all we need to do is to give each core its own bit of the complex plane to work on, collect the results at the end and reap the increase in speed. Here’s the full parallel version of the power tower fractal code
(*Complete Parallel version of the power tower fractal code*)
convergeQ[base_, size_] :=
If[Length[
Quiet[NestWhileList[N[(base^#)] &, base, Abs[#1 - #2] > 0.01 &,
2, size, -1]]] < size, 1, 0];
LaunchKernels[];
DistributeDefinitions[convergeQ];
ParallelEvaluate[SetSystemOptions["CatchMachineUnderflow" -> False]];
towerFractParallel[xmin_, xmax_, ymin_, ymax_, step_] :=
ArrayPlot[
ParallelTable[
convergeQ[x + I y, 50], {y, ymin, ymax, step}, {x, xmin, xmax, step}
, Method -> "CoarsestGrained"]]
This code is pretty similar to the single processor version so let’s focus on the parallel modifications. My convergeQ function is no different to the serial version so nothing new to talk about there. So, the first new code is
LaunchKernels[];
This launches a set of parallel Mathematica kernels. The amount that actually get launched depends on the number of cores on your machine. So, on my dual core laptop I get 2 and on my quad core desktop I get 4.
DistributeDefinitions[convergeQ];
All of those parallel kernels are completely clean in that they don’t know about my user defined convergeQ function. This line sends the definition of convergeQ to all of the freshly launched parallel kernels.
ParallelEvaluate[SetSystemOptions["CatchMachineUnderflow" -> False]];
Here we turn off Mathematica’s machine underflow safety net on all of our parallel kernels using the ParallelEvaluate function.
That’s all that is necessary to set up the parallel environment. All that remains is to change Map to ParallelMap and to add the argument Method -> “CoarsestGrained” which basically says to Mathematica ‘Each sub-calculation will take a tiny amount of time to perform so you may as well send each core lots to do at once’ (click here for a blog post of mine where this is discussed further).
That’s all it took to take this embarrassingly parallel problem from a serial calculation to a parallel one. Let’s see if it worked. The test machine for what follows contains a T5800 Intel Core 2 Duo CPU running at 2Ghz on Ubuntu (if you want to repeat these timings then I suggest you read this blog post first or you may find the parallel version going slower than the serial one). I’ve suppressed the output of the graphic since I only want to time calculation and not rendering time.
(*Serial version*)
In[3]= AbsoluteTiming[towerFract[-2, 2, -2, 2, 0.1];]
Out[3]= {0.672976, Null}
(*Parallel version*)
In[4]= AbsoluteTiming[towerFractParallel[-2, 2, -2, 2, 0.1];]
Out[4]= {0.532504, Null}
In[5]= speedup = 0.672976/0.532504
Out[5]= 1.2638
I was hoping for a bit more than a factor of 1.26 but that’s the way it goes with parallel programming sometimes. The speedup factor gets a bit higher if you increase the size of the problem though. Let’s increase the problem size by a factor of 100.
towerFractParallel[-2, 2, -2, 2, 0.01]
The above calculation took 41.99 seconds compared to 63.58 seconds for the serial version resulting in a speedup factor of around 1.5 (or about 34% depending on how you want to look at it).

Other optimisations
I guess if I were really serious about optimising this problem then I could take advantage of the symmetry along the x axis or maybe I could utilise the fact that if one point in a convergence spiral converges then it follows that they all do. Maybe there are more intelligent ways to test for convergence or maybe I’d get a big speed increase from programming in C or F#? If anyone is interested in having a go at improving any of this and succeeds then let me know.
I’m not going to pursue any of these or any other optimisations, however, since the above exploration is what I achieved in a single train journey to work (The write-up took rather longer though). I didn’t know where I was going and I only worried about optimisation when I had to. At each step of the way the code was fast enough to ensure that I could interact with the problem at hand.
Being mostly ‘fast enough’ with minimal programming effort is one of the reasons I like playing with Mathematica when doing explorations such as this.
Treading where people have gone before
So, back to the power tower story. As I mentioned earlier, I did most of the above in a single train journey and I didn’t have access to the internet. I was quite excited that I had found a fractal from such a relatively simple system and very much felt like I had discovered something for myself. Would this lead to something that was publishable I wondered?
Sadly not!
It turns out that power towers have been thoroughly investigated and the act of forming a tower is called tetration. I learned that when a tower converges there is an analytical formula that gives what it will converge to:

Where W is the Lambert W function (click here for a cool poster for this function). I discovered that other people had already made Wolfram Demonstrations for power towers too
There is even a website called tetration.org that shows ‘my’ fractal in glorious technicolor. Nothing new under the sun eh?
Parting shots
Well, I didn’t discover anything new but I had a bit of fun along the way. Here’s the final Manipulate I came up with
Manipulate[const = p[[1]] + p[[2]] I;
If[hz,
ListPlot[fasttowerspiral[const, n], PlotRange -> {{-2, 2}, {-2, 2}},
Axes -> ax,
Epilog -> {{PointSize[Large], Red,
Point[complexSplit[N[h[const]]]]}, {Inset[
Framed[N[h[const]]], {-1, -1.5}]}}]
, ListPlot[fasttowerspiral[const, n],
PlotRange -> {{-2, 2}, {-2, 2}}, Axes -> ax]
]
, {{n, 100, "Number of terms"}, 1, 500, 1, Appearance -> "Labeled"}
, {{ax, True, "Show axis"}, {True, False}}
, {{hz, True, "Show h(z)"}, {True, False}}
, {{p, {0, 1.5}}, Locator}
, Initialization :> (
SetSystemOptions["CatchMachineUnderflow" -> False];
complexSplit[x_] := {Re[x], Im[x]};
fasttowerspiral[base_, size_] :=
Quiet[Map[complexSplit,
NestWhileList[N[(base^#)] &, base, MatchQ[#, _Complex] &, 1,
size, -1]]];
h[z_] := -ProductLog[-Log[z]]/Log[z];
)
]
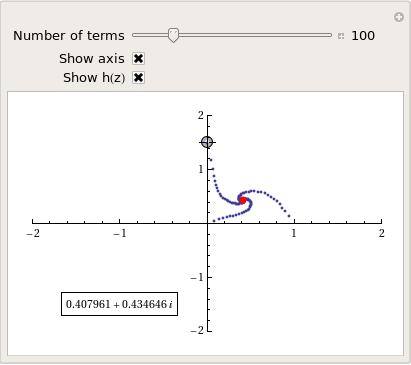
and here’s a video of a zoom into the tetration fractal that I made using spare cycles on Manchester University’s condor pool.
If you liked this blog post then you may also enjoy:
The MATLAB function ranksum is part of MATLAB’s Statistics Toolbox. Like many organizations who use network licensing for MATLAB and its toolboxes, my employer, The University of Manchester, sometimes runs out of licenses for this toolbox which leads to following error message when you attempt to evaluate ranksum.
??? License checkout failed. License Manager Error -4 Maximum number of users for Statistics_Toolbox reached. Try again later. To see a list of current users use the lmstat utility or contact your License Administrator.
An alternative to the Statistics Toolbox is the NAG Toolbox for MATLAB for which we have an unlimited number of licenses. Here’s how to replace ranksum with the NAG routine g08ah.
Original MATLAB / Statistics Toolbox code
x = [0.8147;0.9058;0.1270;0.9134;0.6324;0.0975;0.2785;0.5469;0.9575;0.9649]; y= [0.4076;1.220;1.207;0.735;1.0502;0.3918;0.671;1.165;1.0422;1.2094;0.9057;0.285;1.099;1.18;0.928]; p = ranksum(x,y)
The result is p = 0.0375
Code using the NAG Toolbox for MATLAB
x = [0.8147;0.9058;0.1270;0.9134;0.6324;0.0975;0.2785;0.5469;0.9575;0.9649]; y = [0.4076;1.220;1.207;0.735;1.0502;0.3918;0.671;1.165;1.0422;1.2094;0.9057;0.285;1.099;1.18;0.928]; tail = 'T'; [u, unor, p, ties, ranks, ifail] = g08ah(x, y, tail);
The value for p is the same as that calculated by ranksum: p = 0.0375
NAG’s g08ah routine returns a lot more than just the value p but, for this particular example, we can just ignore it all. In fact, if you have MATLAB 2009b or above then you could call g08ah like this
tail = 'T'; [~, ~, p, ~, ~, ~] = g08ah(x, y, tail);
Which explicitly indicates that you are not going to use any of the outputs other than p.
People at Manchester are using the NAG toolbox for MATLAB more and more; not only because we have a full site license for it but because it can sometimes be very fast. Here’s some more articles on the NAG toolbox you may find useful.
A bit of background to this post
I work in the IT department of the University of Manchester and we are currently developing a Condor Pool which is basically a method of linking together hundreds of desktop machines to produce a high-throughput computing resource. A MATLAB user recently submitted some jobs to our pool and complained that all of them gave identical results which is stupid because his code used MATLAB’s rand command to mix things up a bit.
I was asked if I knew why this should happen to which I replied ‘yes.’ I was then asked to advise the user how to fix the problem and I did so. The next request was for me to write some recommendations and tutorials on how users should use random numbers in MATLAB (and Mathematica and possibly Python while I was at it) along with our Condor Pool and I went uncharacteristically quiet for a while.
It turned out that I had a lot to learn about random numbers. This is the first of a series of (probably 2) posts that will start off by telling you what I knew and move on to what I have learned. It’s as much a vehicle for getting the concepts straight in my head as it is a tutorial.
Ask MATLAB for 10 Random Numbers
Before we go on, I’d like you to try something for me. You have to start on a system that doesn’t have MATLAB running at all so if MATLAB is running then close it before proceeding. Now, open up MATLAB and before you do anything else issue the following command
rand(10,1)
As many of you will know, the rand command produces random numbers from the uniform distribution between 0 and 1 and the command above is asking for 10 such numbers. You may reasonably expect that the 10 random numbers that you get will be different from the 10 random numbers that I get; after all, they are random right? Well, I got the following numbers when running the above command on MATLAB 2009b running on Linux.
ans = 0.8147 0.9058 0.1270 0.9134 0.6324 0.0975 0.2785 0.5469 0.9575 0.9649
Look familiar?
Now I’ve done this experiment with a number of people over the last few weeks and the responses can be roughly split into two different camps as follows:
1. Oh yeah, I know all about that – nothing to worry about. It’s pretty obvious why it happens isn’t it?
2. It’s a bug. How can the numbers be random if MATLAB always returns the same set?
What does random mean anyway?
If you are new to the computer generation of random numbers then there is something that you need to understand and that is that, strictly speaking, these numbers (like all software generated ‘random’ numbers) are not ‘truly’ random. Instead they are pseudorandom – my personal working definition of which is “A sequence of numbers generated by some deterministic algorithm in such a way that they have the same statistical properties of ‘true’ random numbers”. In other words, they are not random they just appear to be but the appearance is good enough most of the time.
Pseudorandom numbers are generated from deterministic algorithms with names like Mersenne Twister, L’Ecuyer’s mrg32k3a [1] and Blum Blum Schub whereas ‘true’ random numbers come from physical processes such as radioactive decay or atmospheric noise (the website www.random.org uses atmospheric noise for example).
For many applications, the distinction between ‘truly random’ and ‘pseudorandom’ doesn’t really matter since pseudorandom numbers are ‘random enough’ for most purposes. What does ‘random enough’ mean you might ask? Well as far as I am concerned it means that the random number generator in question has passed a set of well defined tests for randomness – something like Marsaglia’s Diehard tests or, better still, L’Ecuyer and Simard’s TestU01 suite will do nicely for example.
The generation of random numbers is a complicated topic and I don’t know enough about it to do it real justice but I know a man who does. So, if you want to know more about the theory behind random numbers then I suggest that you read Pierre L’Ecuyer’s paper simply called ‘Random Numbers’ (pdf file).
Back to MATLAB…
Always the same seed
So, which of my two groups are correct? Is there a bug in MATLAB’s random number generator or not?
There is nothing wrong with MATLAB’s random number generator at all. The reason why the command rand(10,1) will always return the same 10 numbers if executed on startup is because MATLAB always uses the same seed for its pseudorandom number generator (which at the time of writing is a Mersenne Twister) unless you tell it to do otherwise.
Without going into details, a seed is (usually) an integer that determines the internal state of a random number generator. So, if you initialize a random number generator with the same seed then you’ll always get the same sequence of numbers and that’s what we are seeing in the example above.
Sometimes, this behaviour isn’t what we want. For example, say I am doing a Monte Carlo simulation and I want to run it several times to verify my results. I’m going to want a different sequence of random numbers each time or the whole exercise is going to be pointless.
One way to do this is to initialize the random number generator with a different seed at startup and a common way of achieving this is via the system clock. The following comes straight out of the current MATLAB documentation for example
RandStream.setDefaultStream(RandStream('mt19937ar','seed',sum(100*clock)));
If you are using MATLAB 2011a or above then you can use the following, much simpler syntax to do the same thing
rng shuffle
Do this once per MATLAB session and you should be good to go (there is usually no point in doing it more than once per session by the way….your numbers won’t be any ‘more random’ if you so. In fact, there is a chance that they will become less so!).
Condor and ‘random’ random seeds
Sometimes the system clock approach isn’t good enough either. For example, at my workplace, Manchester University, we have a Condor Pool of hundreds of desktop machines which is perfect for people doing Monte Carlo simulations. Say a single simulation takes 5 hours and it needs to be run 100 times in order to get good results. On one machine that’s going to take about 3 weeks but on our Condor Pool it can take just 5 hours since all 100 simulations run at the same time but on different machines.
If you don’t think about random seeding at all then you end up with 100 identical sets of results using MATLAB on Condor for the reasons I’ve explained above. Of course you know all about this so you switch to using the clock seeding method, try again and….get 100 identical sets of results[2].
The reason for this is that the time on all 100 machines is synchronized using internet time servers. So, when you start up 100 simultaneous jobs they’ll all have the same timestamp and, therefore, have the same random seed.
It seems that what we need to do is to guarantee (as far as possible) that every single one of our condor jobs gets a unique seed in order to provide a unique random number stream and one way to do this would be to incorporate the condor process ID into the seed generation in some way and there are many ways one could do this. Here, however, I’m going to take a different route.
On Linux machines it is possible to obtain small numbers of random numbers using the special files /dev/random and /dev/urandom which are interfaces to the kernel’s random number generator. According to the documentation ‘The random number generator gathers environmental noise from device drivers and other sources into an entropy pool. The generator also keeps an estimate of the number of bit of the noise in the entropy pool. From this entropy pool random numbers are created.’
This kernel generator isn’t suitable for simulation purposes but it will do just fine for generating an initial seed for MATLAB’s pseudorandom number generator. Here’re the MATLAB commands
[status seed] = system('od /dev/urandom --read-bytes=4 -tu | awk ''{print $2}''');
seed=str2double(seed);
RandStream.setDefaultStream(RandStream('mt19937ar','seed',seed));
In MATLAB 2011a or above you can change this to
[status seed] = system('od /dev/urandom --read-bytes=4 -tu | awk ''{print $2}''');
seed=str2double(seed);
rng(seed);
Put this at the beginning of the MATLAB script that defines your condor job and you should be good to go. Don’t do it more than once per MATLAB session though – you won’t gain anything!
The end or the end of the beginning?
If you asked me the question ‘How do I generate a random seed for a pseudorandom number generator?’ then I think that the above solution answers it quite well. If, however, you asked me ‘What is the best way to generate multiple independent random number streams that would be good for thousands of monte-carlo simulations?‘ then we need to rethink somewhat for the following reasons.
Seed collisions: The Mersenne twister algorithm currently used as the default random number generator for MATLAB uses a 32bit integer seed which means that it can take on 2^32 or 4,294,967,296 different values – which seems a lot! However, by considering a generalisation of the birthday problem it can be seen that if you select such a seed at random then you have a 50% chance choosing two identical seeds after only 65,536 runs. In other words, if you perform 65,536 simulations then there is a 50% chance that two such simulations will produce identical results.
Bad seeds: I have read about (but never experienced) the possibility of ‘bad seeds’; that is some seeds that produce some very strange, non-random results – for the first few thousand iterates at least. This has led to some people advising that you should ‘warm-up’ your random number generator by asking for, and throwing away, a few thousand random numbers before you start using them. Does anyone know of any such bad seeds?
Overlapping or correlated sequences: All pseudorandom number generators are periodic (at least, all the ones that I know about are) – which means that after N iterations the sequence repeats itself. If your generator is good then N is usually large enough that you don’t need to worry about this. The Mersenne Twister used in MATLAB, for instance, has a huge period of (2^19937 – 1)/2 (half of the standard 32bit implementation).
The point I want to make is that you don’t get several different streams of random numbers, you get just one, albeit a very big one. Now, when you choose a seed you are essentially choosing a random point in this stream and there is no guarantee how far apart these two points are. They could be separated by a distance of trillions of points or they could be right next to each other – we simply do not know – and this leads to the possibility of overlapping sequences.
Now, one could argue that the possibility of overlap is very small in a generator such as the Mersenne Twister and I do not know of any situation where it has occurred in practice but that doesn’t mean that we shouldn’t worry about it. If your work is based on the assumption that all of your simulations have used independent, uncorrelated random number streams then there is a possibility that your assumptions could be wrong which means that your conclusions could be wrong. Unlikely maybe, but still no way to do science.
Next Time
Next time I’ll be looking at methods for generating guaranteed independent random number streams using MATLAB’s in-built functions as well as methods taken from the NAG Toolbox for MATLAB. I’ll also be including explicit examples that use this stuff in Condor.
Ask the audience
I assume that some of you will be in the business of performing Monte-Carlo simulations and so you’ll probably know much more about all of this than me. I have some questions
- Has anyone come across any ‘bad seeds’ when dealing with MATLAB’s Mersenne Twister implementation?
- Has anyone come across overlapping sequences when using MATLAB’s Mersenne Twister implementation?
- How do YOU set up your random number generator(s).
I’m going to change my comment policy for this particular post in that I am not going to allow (most) anonymous comments. This means that you will have to give me your email address (which, of course, I will not publish) which I will use once to verify that it really was you that sent the comment.
Notes and References
[1] L’Ecuyer P (1999) Good parameter sets for combined multiple recursive random number generators Operations Research 47:1 159–164
[2] More usually you’ll get several different groups of results. For example you might get 3 sets of results, A B C, and get 30 sets of A, 50 sets of B and 20 sets of C. This is due to the fact that all 100 jobs won’t hit the pool at precisely the same instant.
[3] Much of this stuff has already been discussed by The Mathworks and there is an excellent set of articles over at Loren Shure’s blog – Loren onThe Art of MATLAB.
I work for the University of Manchester in the UK as a ‘Science and Engineering Applications specialist’ which basically means that I am obsessed with software used by mathematicians and scientists. One of the applications within my portfolio is the NAG library – a product that we use rather a lot in its various incarnations. We have people using it from Fortran, C, C++, MATLAB, Python and even Visual Basic in areas as diverse as engineering, applied maths, biology and economics.
Yes, we are big users of NAG at Manchester but then that stands to reason because NAG and Manchester have a collaborative history stretching back 40 years to NAG’s very inception. Manchester takes a lot of NAG’s products but for reasons that are lost in the mists of time, we have never (to my knowledge at least) had a site license for their SMP library (more recently called The NAG Library for SMP & multicore). Very recently, that changed!
SMP stands for Symmetric Multi-Processor which essentially means ‘two or more CPUs sharing the same bit of memory.’ Five years ago, it would have been rare for a desktop user to have an SMP machine but these days they are everywhere. Got a dual-core laptop or a quad-core desktop? If the answer’s ‘yes’ then you have an SMP machine and you are probably wondering how to get the most out of it.
‘How can I use all my cores (without any effort)’
One of the most common newbie questions I get asked these days goes along the lines of ‘Program X is only using 50%/25%/12.5% of my CPU – how can I fix this?’ and, of course, the reason for this is that the program in question is only using a single core of their multicore machine. So, the problem is easy enough to explain but not so easy to fix because it invariably involves telling the user that they are going to have to learn how to program in parallel.
Explicit parallel programming is a funny thing in that sometimes it is trivial and other times it is pretty much impossible – it all depends on the problem you see. Sometimes all you need to do is drop a few OpenMP pragmas here and there and you’ll get a 2-4 times speed up. Other times you need to completely rewrite your algorithm from the ground up to get even a modest speed up. Yet more times you are simply stuck because your problem is inherently non-parallelisable. It is even possible to slow your code down by trying to parallelize it!
If you are lucky, however, then you can make use of all those extra cores with no extra effort at all! Slowly but surely, mathematical software vendors have been re-writing some of their functions to ensure that they work efficiently on parallel processors in such a way that it is transparent to the user. This is sometimes referred to as implicit parallelism.
Take MATLAB, for example, ever since release 2007a more and more built in MATLAB functions have been modified to allow them to make full use of multi-processor systems. If your program makes extensive use of these functions then you don’t need to spend extra money or time on the parallel computing toolbox, just run your code on the latest version of MATLAB, sit back and enjoy the speed boost. It doesn’t work for all functions of course but it does for an ever increasing subset.
The NAG SMP Library – zero effort parallel programming
For users of NAG routines, the zero-effort approach to making better use of your multicore system is to use their SMP library. According to NAG’s advertising blurb you don’t need to rewrite your code to get a speed boost – you just need to link to the SMP library instead of the Fortran library at compile time.
Just like MATLAB, you won’t get this speed boost for every function, but you will get it for a significant subset of the library (around 300+ functions as of Mark 22 – the full list is available on NAG’s website). Also, just like MATLAB, sometimes the speed-up will be massive and other times it will be much more modest.
I wanted to test NAG’s claims for myself on the kind of calculations that researchers at Manchester tend to perform so I asked NAG for a trial of the upcoming Mark 22 of the SMP library and, since I am lazy, I also asked them to provide me with simple demonstration programs and I’d like to share the results with you all. These are not meant to be an exhaustive set of benchmarks (I don’t have the time to do such a thing) but should give you an idea of what you can expect from NAG’s new library.
System specs
All of these timings were made on a 3Ghz Intel Core2 Quad Q9650 CPU desktop machine with 8Gb of RAM running Ubuntu 9.10. The serial version of the NAG library used was fll6a22dfl and the SMP version of the library was fsl6a22dfl. The version of gfortran used was 4.4.1 and the cpu-frequency governor was switched off as per a previous blog post of mine.
Example 1 – Nearest correlation matrix
The first routine I looked at was one that calculated the nearest correlation matrix. In other words ‘Given a symmetric matrix, what is the nearest correlation matrix—that is, the nearest symmetric positive semidefinite matrix with unit diagonal?’[1] This is a problem that pops up a lot in Finance – option pricing, risk management – that sort of thing.
The NAG routine that calculates the nearest correlation matrix is G02AAF which is based on the algorithm developed by Qi and Sun[2]. The example program I was sent first constructs a N x N tridiagonal matrix A of the form A(j,j)=2, A(j-1,j)=-1.1 and A(j,j-1)=1.0. It then times how long it takes G02AAF to find the nearest correlation matrix to A. You can download this example, along with all supporting files, from the links below.
To compile this benchmark against the serial library I did
gfortran ./bench_g02aaf.f90 shtim.c wltime.f /opt/NAG/fll6a22dfl/lib/libnag_nag.a \ /opt/NAG/fll6a22dfl/acml/libacml_mv.a -o serial_g02aaf
To compile the parallel version I did
gfortran -fopenmp ./bench_g02aaf.f90 shtim.c wltime.f /opt/NAG/fsl6a22dfl/lib/libnagsmp.a \ /opt/NAG/fsl6a22dfl/acml4.3.0/lib/libacml_mp.a -o smp_g02aaf
I didn’t need to modify the source code in any way when going from a serial version to a parallel version of this benchmark. The only work required was to link to the SMP library instead of the serial library – so far so good. Let’s run the two versions and see the speed differences.
First things first, let’s ensure that there is no limit to the stack size of my shell by doing the following in bash
ulimit -s unlimited
Also, for the parallel version, I need to set the number of threads to equal the number of processors I have on my machine by setting the OMP_NUM_THREADS environment variable.
export OMP_NUM_THREADS=4
This won’t affect the serial version at all. So, onto the program itself. When you run it, it will ask you for two inputs – an integer, N, and a boolean, IO. N gives the size of the starting matrix and IO determines whether or not to output the result.
Here’s an example run of the serial version with N=1000 and IO set to False. (In Fortran True is represented as .t. and False is represented as .f. )
./serial_g02aaf G02AAF: Enter N, IO 1000 .f. G02AAF: Time, IFAIL = 37.138997077941895 0 G02AAF: ITER, FEVAL, NRMGRD = 4 5 4.31049822255544465E-012
The only output I am really interested in here is the time and 37.13 seconds doesn’t seem too bad for a 1000 x 1000 matrix at first glance. Move to the parallel version though and you get a very nice surprise
./smp_g02aaf G02AAF: Enter N, IO 1000 .f. G02AAF: Time, IFAIL = 5.1906139850616455 0 G02AAF: ITER, FEVAL, NRMGRD = 4 5 4.30898281428799420E-012
The above times were typical and varied little from run to run (although the SMP version varied by a bigger percentage than the serial version). However I averaged over 10 runs to make sure and got 37.14 s for the serial version and 4.88 s for the SMP version which gives a speedup of 7.6 times!
Now, this is rather impressive. Usually, when one parallelises over N cores then the very best you can expect in an ideal word is a speed up of just less than N times, so called ‘linear scaling’. Here we have N=4 and a speedup of 7.6 implying that NAG have achieved ‘super-linear scaling’ which is usually pretty rare.
I dropped them a line to ask what was going on. It turns out that when they looked at parallelising this routine they worked out a way of speeding up the serial version as well. This serial speedup will be included in the serial library in its next release, Mark 23 but the SMP library got it as of Mark 22.
So, some of that 7.6 times speedup is as a result of serial speedup and the rest is parallelisation. By setting OMP_NUM_THREADS to 1 we can force the SMP version of the benchmark to only run on only one core and thus see how much of the speedup we can attribute to parallelisation:
export OMP_NUM_THREADS=1 ./smp_g02aaf G02AAF: Enter N, IO 1000 .f. G02AAF: Time, IFAIL = 12.714214086532593 0 G02AAF: ITER, FEVAL, NRMGRD = 4 5 4.31152424170390294E-012
Recall that the 4 core version took an average of 4.88 seconds so the speedup from parallelisation alone is 2.6 times – much closer to what I expected to see. Now, it is probably worth mentioning that there is an extra level of complication (with parallel programming there is always an extra level of complication) in that some of this parallelisation speedup comes from extra work that NAG has done in their algorithm and some of it comes from the fact that they are linking to parallel versions of the BLAS and LAPACK libraries. We could go one step further and determine how much of the speed up comes from NAG’s work and how much comes from using parallel BLAS/LAPACK but, well, life is short.
The practical upshot is that if you come straight from the Mark 22 serial version then you can expect a speed-up of around 7.6 times. In the future, when you compare the Mark 22 SMP library to the Mark 23 serial library then you can expect a speedup of around 2.6 times on a 4 core machine like mine.
Example 2 – Quasi random number generation
Quasi random numbers (also referred to as ‘Low discrepancy sequences’) are extensively used in Monte-Carlo simulations which have applications in areas such as finance, chemistry and computational physics. When people need a set of quasi random numbers they usually need a LOT of them and so the faster they can be produced the better. The NAG library contains several quasi random number generators but the one considered here is the routine g05ymf. The benchmark program I used is called bench_g05ymf.f90 and the full set of files needed to compile it are available at the end of this section.
The benchmark program requires the user to input 4 numbers and a boolean as follows.
- The first number is the quasi random number generator to use with the options being:
- NAG’s newer Sobol generator (based on the 2008 Joe and Kuo algorithm[3] )
- NAG’s older Sobol generator
- NAG’s Niederreiter generator
- NAG’s Faure generator
- The second number is the order in which the generated values are returned (The parameter RCORD as referred to in the documentation for g05ymf). Say that the matrix of returned values is called QUAS then if RCORD=1, QUAS(i,j) holds the jth value for the ith dimension, otherwise QUAS(i,j) holds the ith value for the jth dimension.
- The third number is the number of dimensions required.
- The fourth number is the number of number of quasi-random numbers required.
- The boolean (either .t. or .f.) determines whether or not the output should be verbose or not. A value of .t. will output the first 100 numbers in the sequence.
To compile the benchmark program against the serial library I did:
gfortran ./bench_g05ymf.f90 shtim.c wltime.f /opt/NAG/fll6a22dfl/lib/libnag_nag.a \ /opt/NAG/fll6a22dfl/acml/libacml_mv.a -o serial_g02aaf
As before, the only thing needed to turn this into a parallel program was to compile against the SMP library and add the -fopenmp switch
gfortran -fopenmp ./bench_g05ymf.f90 shtim.c wltime.f /opt/NAG/fsl6a22dfl/lib/libnagsmp.a \ /opt/NAG/fsl6a22dfl/acml4.3.0/lib/libacml_mp.a -o smp_g02aaf
The first set of parameters I used was
1 2 900 1000000 .f.
Which uses NAG’s new Sobol generator with RCORD=2 to generate and store 1,000,000 numbers over 900 dimensions with no verbose output. Averaged over 10 runs the times were 5.17 seconds for the serial version and 2.14 seconds for the parallel version giving a speedup of 2.4x on a quad-core machine. I couldn’t push number of dimensions much higher because the benchmark stores all of the numbers in one large array and I was starting to run out of memory.
If you only want a relatively small sequence then switching to the SMP library is actually slower thanks to the overhead involved in spawning extra threads. For example if you only want 100,000 numbers over 8 dimensions:
1 2 8 100000 .f.
then the serial version of the code takes an average of 0.0048 seconds compared to 0.0479 seconds for the parallel version so the parallel version is almost 10 times slower when using 4 threads for small problems. Setting OMP_NUM_THREADS to 1 gives exactly the same speed as the serial version as you might expect.
NAG have clearly optimized this function to ensure that you get a good speedup for large problem sets which is where it really matters so I am very pleased with it. However, the degradation in performance for smaller problems concerns me a little. I think I’d prefer it if NAG were to modify this function so that it works serially for small sequences and to automatically switch to parallel execution if the user requests a large sequence.
Conclusions
In the old days we could speedup our programs simply by buying a new computer. The new computer would have a faster clock speed than the old one and so our code would run faster with close to zero effort on our part. Thanks to the fact that clock speeds have stayed more or less constant for the last few years those days are over. Now, when we buy a new computer we get more processors rather than faster ones and this requires a change in thinking. Products such as the NAG Library for SMP & multicore help us to to get the maximum benefit out of our machines with the minimum amount of effort on our part. If switching to a product like this doesn’t give you the performance boost you need then the next thing for you to do is to learn how to program in parallel. The free ride is over.
In summary:
- You don’t need to modify your code if it already uses NAG’s serial library. Just recompile against the new library and away you go. You don’t need to know anything about parallel programming to make use of this product.
- The SMP Library works best with big problems. Small problems don’t work so well because of the inherent overheads of parallelisation.
- On a quad-core machine you can expect speed-ups around 2-4 times compared to the serial library. In exceptional circumstances you can expect speed-up as large as 7 times or more.
- You should notice a speed increase in over 300 functions compared to the serial library.
- Some of this speed increase comes from fundamental libraries such as BLAS and LAPACK, some of it comes from NAG directly parallelising their algorithms and yet more comes from improvements to the underlying serial code.
- I’m hoping that this Fortran version is just the beginning. I’ve always felt that NAG program in Fortran so I don’t have to and I’m hoping that they will go on to incorporate their SMP improvements in their other products, especially their C library and MATLAB toolbox.
Acknowledgements
Thanks to several staff at NAG who suffered my seemingly endless stream of emails during the writing of this article. Ed, in particular, has the patience of a saint. Any mistakes left over are all mine!
Links
- The Nearest Correlation Matrix benchmark program used here – bench_g02aaf.f90 – along with the source code for the timing routine.
- NAG’s documentation for the g02aaf routine.
- The Quasi Random Number benchmark program used here – bench_g05ymf.f90 – along with the source code for the timing routine.
- An Introduction to quasi random numbers (written by a member of NAG’s staff)
- Official NAG documentation for g05ymf – the quasi random number generator considered here.
References
[1] – Higham N, Computing the nearest correlation matrix—a problem from finance, IMA Journal of Numerical Analysis 22 (3): 329–343
[2] – Qi H and Sun D (2006), A Quadratically Convergent Newton Method for Computing the Nearest
Correlation Matrix, SIAM J. Matrix AnalAppl 29(2) 360–385
[3] – Joe S and Kuo F Y (2008) Constructing Sobol sequences with better two-dimensional projects SIAM J. Sci. Comput. 30 2635–2654
Dislaimer: This is a personal blog and the opinions expressed on it are mine and do not necessarily reflect the policies and opinions of my employer, The University of Manchester.